
Answer Engine Optimization Services: A GEO Framework
Discover how professional answer engine optimization services reverse-engineer AI search. Learn our framework for AEO and drive measurable business impact.

The most popular advice about answer engine optimization services is already obsolete. Publishing FAQs, adding schema, and hoping AI systems notice isn't a strategy.
Modern visibility is decided upstream, inside retrieval and synthesis systems that select, compress, and cite information before a user ever clicks. CXL reported that zero-click Google searches rose from 56% in 2024 to 69% in 2025 in its AEO guide. That single shift changes the competitive surface. The page is no longer the prize. The answer is.
This paper treats answer engine optimization services as an engineering discipline, not a content checklist. It argues that the only valid foundation for AEO is reverse-engineering how large language models retrieve evidence, score retrievability, and reuse passages. That lens overturns two decades of SEO orthodoxy built around ranking pages, accumulating links, and maximizing clicks.
What matters now is whether a model can confidently extract a claim, verify its context, and cite it inside a generated response. That requires a different operating model, a different measurement model, and a different procurement standard for CMOs buying services in this category.
Table of Contents
Executive Summary
The answer surface replaced the result page
Most service offerings still optimize the wrong unit
Deconstructing Modern AI Search Architecture
Retrieval decides what can become truth
Synthesis rewards citable chunks not pages
The Algomizer Framework Evidence Clusters and Semantic Density
Evidence Clusters create machine-verifiable consensus
Semantic Density replaces keyword density
The Four Pillars of Answer Engine Optimization Services
Visibility assessment comes first
Content engineering changes the source material
Technical implementation makes answers extractable
Measurement and calibration keep the program alive
A Direct Comparison SEO vs AEO
Measuring Business Impact and True ROI
Citation metrics are business metrics
Independent verification is now a buying requirement
Conclusion The New Mandate for Enterprise Marketing
A buyer checklist separates real services from surface tactics
Executive Summary
SEO no longer defines digital visibility. Large language models now compress discovery into a single answer, decide which sources are credible enough to cite, and intercept demand before a click occurs.
The answer surface replaced the result page
The commercial consequence is larger than a channel shift. It is a change in how authority is computed. As noted earlier in the article, recent industry reporting on zero-click behavior and AI visibility gains points to the same conclusion. Users increasingly consume a synthesized answer instead of evaluating a list of links, and brands win only if their information survives that synthesis step.
That changes the unit of competition. Visibility now means presence inside generated outputs across ChatGPT, Gemini, Perplexity, and Google AI Overviews. A brand can hold strong rankings and still lose category demand if answer engines repeatedly extract, cite, and restate a competitor's material.
Research finding: The winning asset in AI search is the most retrievable and reusable evidence unit attached to a trusted entity.
Most service offerings still optimize the wrong unit
Many answer engine optimization services still sell surface tactics inherited from SEO. They recommend schema, FAQ blocks, and content refresh cycles without showing how those interventions affect passage selection, entity resolution, or citation eligibility inside retrieval systems.
That gap matters because models do not evaluate pages the way human visitors do. They process chunked text, source relationships, factual consistency, and structural cues that reduce uncertainty at retrieval time. A service built without that architectural model cannot explain results, cannot forecast them, and usually cannot reproduce them across answer surfaces.
This is the break with two decades of SEO orthodoxy. Rankings were a useful proxy when search engines exposed ten blue links. In answer engines, the proxy fails. The operational target is answer inclusion probability.
Algomizer treats that target as a measurable system, not a branding exercise. Our implementation model starts with reverse-engineering how retrieval-augmented systems admit evidence into the model context, then scores content by evidence coverage, semantic density, and citation usability. Readers who need a technical baseline can review this overview of LLMO fundamentals.
Procurement should reflect that reality. The relevant questions are whether a provider can measure share of answer, raise citation frequency, and validate gains across multiple AI interfaces with a repeatable framework. That is the standard used throughout this paper.
Deconstructing Modern AI Search Architecture
SEO taught marketers to optimize for exposure. AI search rewards admissibility. The difference is architectural, not stylistic, and it changes what an answer engine optimization service must measure.
A technical baseline appears in this overview of LLMO fundamentals.
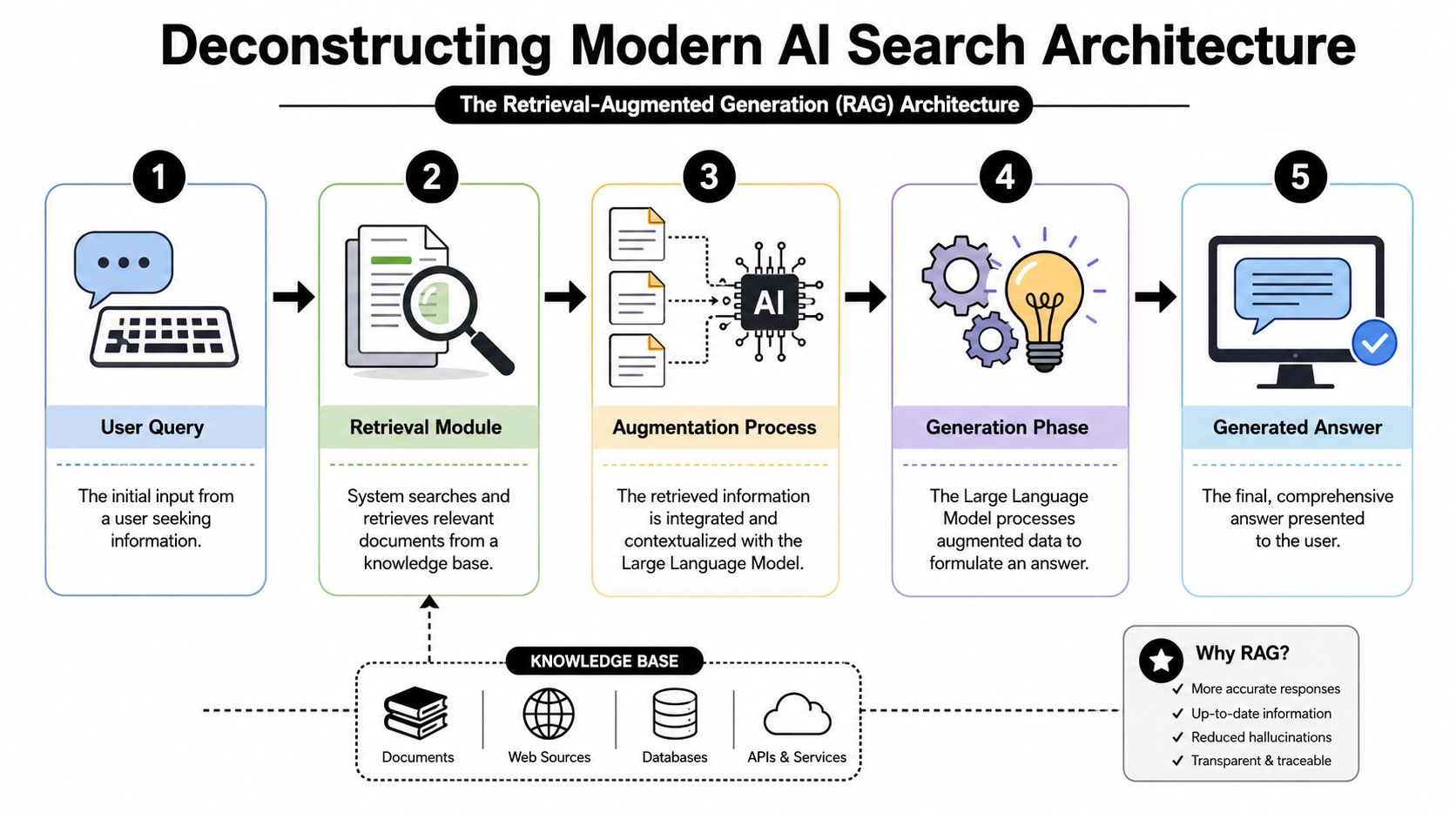
Retrieval decides what can become truth
Modern answer systems follow a constrained pipeline. A query enters the system. Retrieval fetches candidate passages. Ranking filters those passages by relevance, source confidence, and contextual fit. Generation only begins after that gating process. If your content does not enter the model context, no amount of brand authority or stylistic polish can recover the loss.
This is why reverse-engineering LLM architecture is the only credible foundation for AEO services. Tactical advice such as adding schema, refreshing timestamps, or expanding FAQs can help at the margins, but those actions have value only when they improve retrieval eligibility, chunk resolution, and citation fitness. An AI-first visibility program starts with those mechanics because they determine answer inclusion probability.
The unit of competition has changed.
In classic search, the page was the commercial asset. In AI search, the citable passage is the operational asset. Retrieval systems segment documents into chunks, score each chunk against the query, then pass a narrow set of candidates into synthesis. Pages with diffuse claims, delayed definitions, or ambiguous entity references create resolution costs. Models tend to exclude high-cost evidence when lower-friction alternatives exist.
Pages hidden behind complex UX, weak authorship signals, or diffuse claims create retrieval friction. Systems built to minimize uncertainty tend to cite cleaner evidence.
That shift overturns a central SEO assumption. Visibility no longer follows rank position alone. It follows what our lab calls Context Admission Rate, the frequency with which a source is selected into the evidence set that the model can use. AEO services that cannot diagnose this layer are optimizing downstream artifacts while ignoring the gate that controls them.
The video below gives a visual explanation of how synthesis models assemble answers from retrieved chunks.
Synthesis rewards citable chunks not pages
Synthesis is a compression task under uncertainty. The model prefers passages that preserve meaning when shortened, paraphrased, and attributed. That preference favors answer blocks with explicit claims, stable terminology, and nearby support. It penalizes content that relies on narrative buildup, implied context, or scattered definitions across the page.
Superficial AEO advice often fails upon closer examination. It treats AI systems as improved crawlers. They are probabilistic answer constructors with strict context limits and measurable confidence thresholds. The service model that performs in this environment is the one built around architecture-aware implementation.
That implementation has four recurring requirements:
Answer placement: Put the direct claim early so retrieval can surface it without scanning through setup.
Entity clarity: State products, companies, services, and concepts in explicit, repeated language that reduces ambiguity.
Corroboration paths: Place supporting context close to the primary claim so ranking systems can validate it quickly.
Retrieval cleanliness: Remove layout and copy patterns that interrupt parsing or break the semantic continuity of a chunk.
Analysts who still frame AEO as a layer on top of SEO miss the structural break. The model does not read a website the way a prospect does. It assembles a temporary evidence graph from selected fragments, then writes from that graph. Effective answer engine optimization services are therefore architecture programs first, content programs second.
The Algomizer Framework Evidence Clusters and Semantic Density
Legacy SEO treated visibility as a page-level ranking problem. LLM-mediated search does not. It evaluates whether a claim can survive retrieval, compression, and synthesis without losing meaning. That architectural shift is the basis of the Algomizer framework.
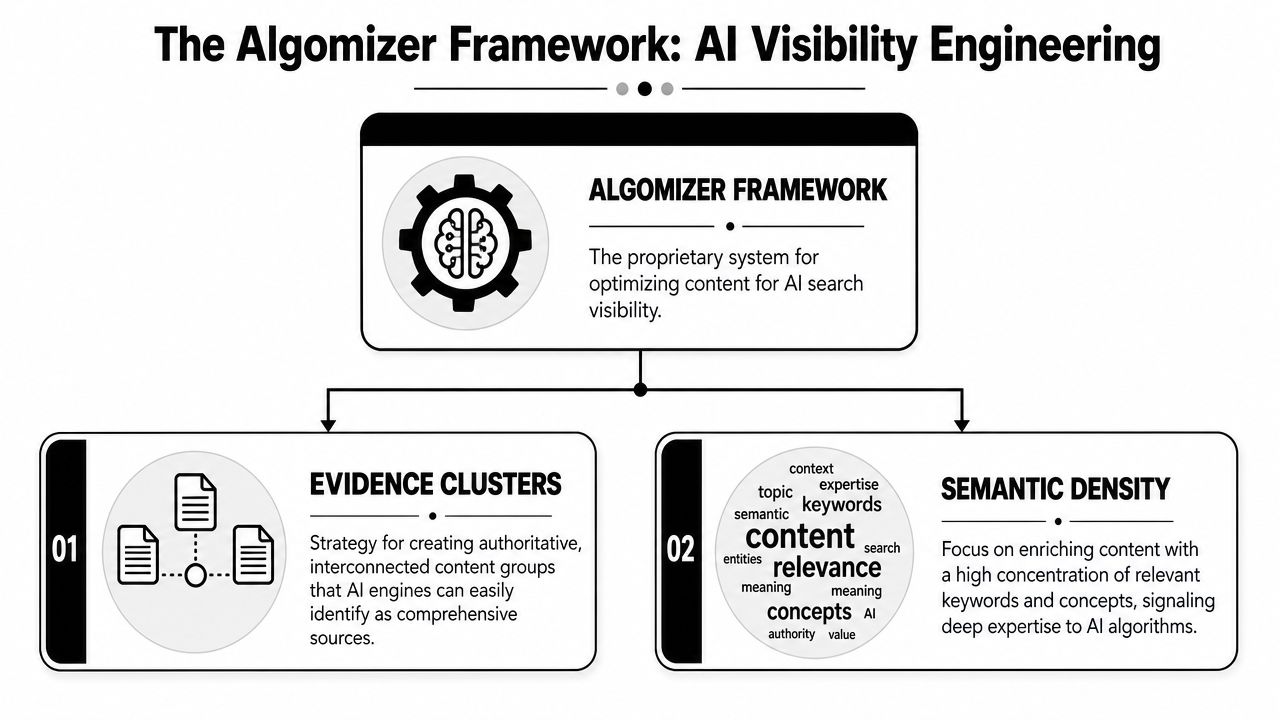
The framework measures two variables that legacy SEO largely ignored. The first is corroboration strength across related assets. The second is semantic efficiency inside the passage most likely to be extracted. Together, they determine whether a brand appears as source material or disappears during model synthesis.
Evidence Clusters create machine-verifiable consensus
Evidence Clusters are corroboration systems built for answer engines. They organize supporting signals around a specific entity, claim, or commercial topic so the model encounters agreement instead of fragmentation.
A high-functioning cluster usually includes owned pages, structured data, author attribution, repeated terminology, and credible third-party references that align on the same interpretation. The point is not volume. The point is convergence. If a model retrieves a service page, a documentation page, an executive byline, and an external mention, those assets should reinforce one another with minimal semantic drift.
This changes how authority should be built.
For a B2B SaaS company, an Evidence Cluster may center on a product category claim and connect the product page, implementation documentation, pricing language, comparison content, organization schema, and executive commentary. For a law firm, the cluster may connect practice area pages, attorney bios, jurisdiction-specific explainers, and references that confirm expertise in the same legal question set. In both cases, the model is not rewarding breadth by itself. It is rewarding aligned evidence that can be assembled into a stable answer state.
Operating principle: Citation frequency rises when claim consistency survives across multiple retrieval paths.
Semantic Density replaces keyword density
Semantic Density measures how much usable meaning a passage delivers per token. That is the metric that matters in answer environments with finite context windows and aggressive compression.
A semantically dense passage resolves the query early, names the relevant entities directly, states the relationship between them, and places qualification close to the claim. It does not rely on narrative buildup or scattered context. It is built for extraction fidelity.
Our lab uses a simple test. Remove the surrounding page chrome, shorten the passage, paraphrase it, and ask whether the main claim still holds. If the answer degrades, semantic density is low. If the claim remains intact and attributable, the passage is structurally fit for model reuse.
Semantically dense passages usually contain four elements:
A direct answer block: The claim appears at the start, not after orientation copy.
Explicit entities and relationships: Brands, services, categories, and outcomes are named in plain language.
Local support: Definitions, caveats, and proof points sit near the primary statement.
Parsing-friendly structure: Headings, lists, and schema reinforce interpretation without adding noise.
This is the break with older optimization doctrine. Keyword density tried to influence ranking signals through repetition. Semantic Density improves extraction reliability under LLM constraints. One approach chases term frequency. The other improves citation eligibility.
For Chapter 1 context, see Return to Chapter 1. To discuss application, book a complimentary AI visibility assessment with a utm_source=blog3 reference.
The Four Pillars of Answer Engine Optimization Services
Traditional SEO services were built for ranking documents. Answer engine optimization services are built for influencing model selection. That difference changes the service model, the work product, and the measurement system.
At our lab, we treat AEO as an architecture problem. A provider cannot improve answer visibility by adding surface-level tactics to an SEO retainer. The work has to mirror how large language models retrieve, compress, compare, and cite source material. Four pillars define whether that work is real or cosmetic.
Visibility assessment comes first
The first pillar is baseline retrieval analysis. The goal is to map where a brand appears across AI answer surfaces, which entities the models associate with the category, and which competitors are repeatedly selected as supporting sources.
This baseline is more specific than a rank report. It functions as a retrieval map. It shows missing entity associations, weak answer candidates, thin evidence coverage, and citation patterns that block inclusion. It also creates the benchmark for later measurement. Without that benchmark, AEO services cannot separate actual retrieval gains from normal model variation.
Teams that need the category-level distinction can review this comparison of AEO, SEO, and GEO models.
Content engineering changes the source material
The second pillar is source reconstruction. Pages are revised so the model can extract a coherent answer block without guessing at context or stitching together claims from multiple sections.
That work usually affects service pages, product pages, comparison pages, glossary entries, support documentation, and category hubs. The objective is not longer content. The objective is higher extraction fidelity. Each priority passage should state the claim early, name the entities directly, keep qualification close to the claim, and preserve meaning when lifted out of the page.
Some organizations support that workflow through internal editorial systems, CMS controls, and specialist software. Algomizer is one example used for AI-search visibility tracking and optimization across answer engines.
AEO content must survive extraction, not just pageview reading.
Technical implementation makes answers extractable
The third pillar is implementation discipline. Many vendors stop at copy revisions. That misses the systems layer that affects whether answer engines can parse, classify, and reuse the material with confidence.
Pages built for answer retrieval usually share the same technical traits. They use semantic HTML, clear heading hierarchy, stable internal linking, and schema that reinforces entity and content type interpretation. They reduce parsing noise and remove avoidable barriers between the model and the answer candidate.
A strong technical pillar usually covers:
Schema deployment: FAQPage, HowTo, Product, and Organization where the content supports those types.
Markup hygiene: Clean heading structure, parsable components, and predictable section boundaries.
Access conditions: Limited friction from overlays, script-heavy rendering, or other crawl suppressors.
Link architecture: Internal pathways that strengthen entity relationships and topical adjacency.
These are not formatting preferences. They are implementation choices that affect retrieval confidence.
Measurement and calibration keep the program alive
The fourth pillar is calibration. Model behavior shifts. Retrieval layers update. Citation patterns drift by engine, prompt type, and topic cluster. AEO services fail when they treat publication as the finish line.
Measurement has to track citation frequency, answer share, competitor displacement, entity coverage, and downstream commercial impact. Our lab refers to this as Answer Presence Calibration. The service loop is simple. Observe selection behavior, identify the passage or evidence failure, revise the source, then test again. That cycle is the only reliable way to maintain visibility in AI-mediated search.
For Chapter 1 context, see Return to Chapter 1. To discuss application, book a complimentary AI visibility assessment with a utm_source=blog4 reference.
A Direct Comparison SEO vs AEO
SEO was built for ranked documents. AEO is built for model selection. That architectural difference changes what gets measured, what gets produced, and what wins.
A more detailed taxonomy appears in this comparison of AEO vs SEO vs GEO.
The old SEO assumption was simple. If a page ranked, visibility followed. AI retrieval broke that chain. Large language models do not treat the page as the atomic unit of value. They evaluate passages, entities, corroborating signals, and answer fitness under retrieval constraints. An AEO program that starts with keyword placement or page-level ranking reports starts too late in the process.
Criterion | Traditional SEO | Answer Engine Optimization (AEO) |
|---|---|---|
Primary goal | Rank a URL in search results | Earn citation or mention in an AI-generated answer |
Unit of value | Web page | Content chunk tied to an entity |
Core activity | Keyword targeting, link acquisition, on-page optimization | Evidence clustering, answer engineering, citation calibration |
Success condition | User clicks the result | Model selects and reuses the source |
Primary visibility surface | Blue-link SERP | AI Overviews, ChatGPT, Gemini, Perplexity, Copilot |
Measurement emphasis | Position, CTR, sessions | Share of answer, citations, mentions, assisted conversions |
Authority model | Ranking signals infer relevance | Retrieval confidence and corroboration enable inclusion |
Editorial style | Long-form page depth | Dense, extractable, self-contained answer blocks |
The non-obvious shift sits in the middle rows. SEO rewards pages that accumulate relevance signals at the document level. AEO rewards source material that survives chunking, retrieval, and synthesis without losing factual integrity. Those are different optimization targets.
That distinction overturns two decades of search practice.
A ranking strategy asks, "How do we get this URL above another URL?" An answer engine strategy asks, "Which evidence block will the model trust enough to reuse?" The first model of visibility is positional. The second is compositional. Brands that confuse the two keep producing longer pages when the system is selecting tighter answer units.
Strong organic performance still matters because it improves the odds that a source enters the retrieval set. It does not settle the outcome. Inclusion in the candidate pool and inclusion in the generated answer are separate events, governed by different mechanisms. That is why AEO services built on SEO checklists underperform. They optimize exposure to crawlers without engineering for selection by language models.
Our lab treats this as a systems problem, not a content marketing variation. Reverse-engineering the retrieval and generation stack shows why superficial tactics fail. The winning source is usually the one with the clearest entity framing, the highest evidence density, and the lowest transformation cost between retrieved passage and final answer. SEO can support those conditions. It cannot substitute for them.
For Chapter 1 context, see Return to Chapter 1. To discuss application, book a complimentary AI visibility assessment with a utm_source=blog5 reference.
Measuring Business Impact and True ROI
Traffic is a lagging indicator. In AI search, commercial impact starts earlier, at the moment a model selects one source and excludes another.
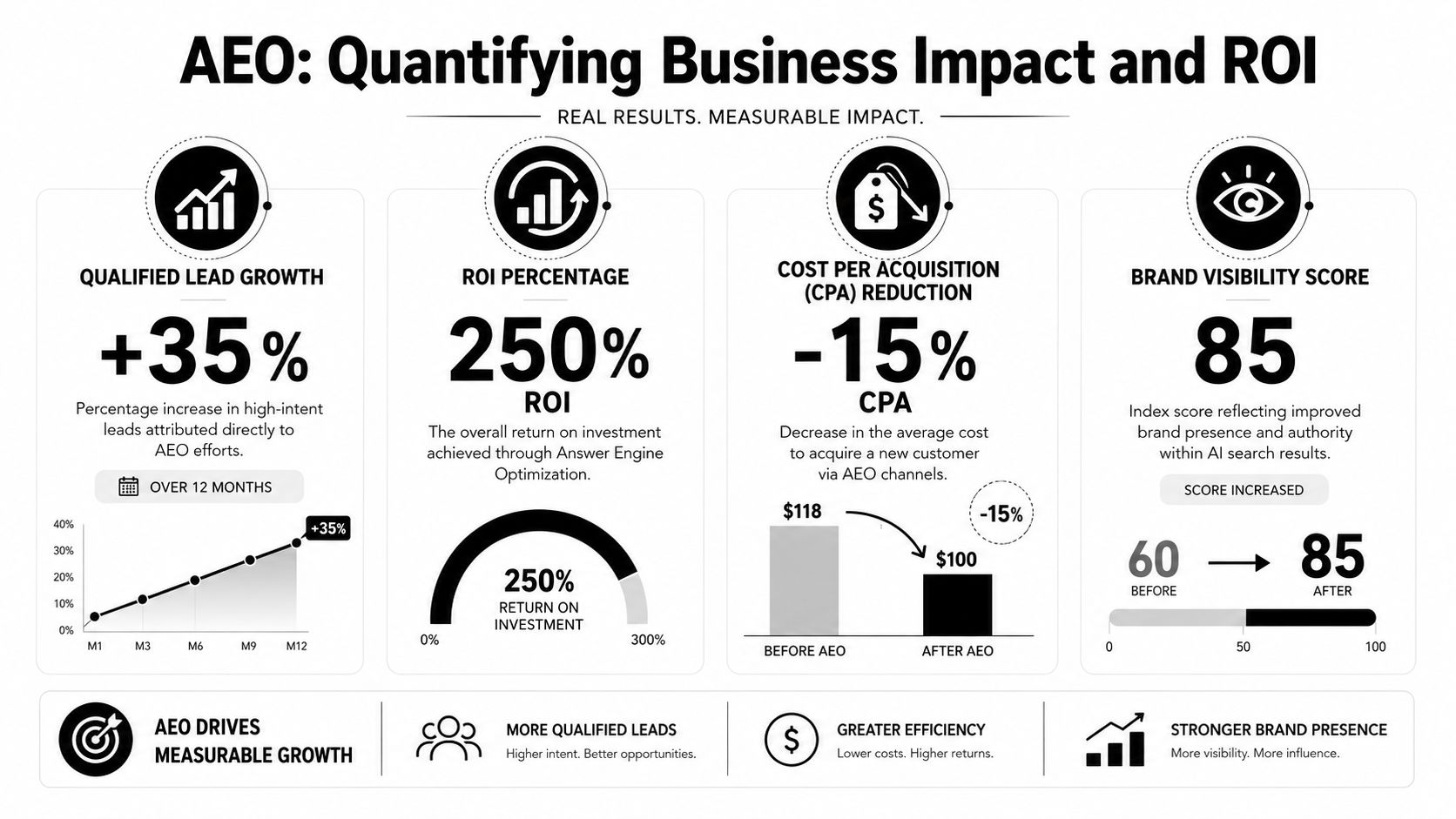
Citation metrics are business metrics
Our lab measures this with a simple premise. Answer visibility creates pre-click persuasion. If a brand is repeatedly named, cited, or structurally reused inside generated responses, it captures authority before the visit, before the demo request, and often before the buyer sees a competitor.
That is why the KPI stack for answer engine optimization services must begin with answer-surface performance rather than session volume. The useful question is not whether a page received traffic. The useful question is whether the model treated the brand's evidence as reusable.
A disciplined measurement model tracks four operating signals:
Citation frequency: how often the brand is used as a named or linked source across target prompts
Share of answer: how much of the answer surface is occupied by the brand's claims, data, or framing
Competitive displacement: which competing sources are being selected in high-intent answer environments
Assisted conversions: whether answer-surface visibility correlates with branded search, direct visits, lead creation, and pipeline progression
This framework reflects how LLM systems allocate attention. Retrieval gets a source into consideration. Generation assigns narrative control. ROI appears when a brand shifts from being merely retrievable to being consistently incorporated into final answers.
The measurement implication is straightforward. A page can retain strong organic exposure and still lose machine-mediated influence. Standard dashboards miss that decay because analytics platforms record the click, not the citation event that shaped buyer judgment upstream.
Enterprise teams still need adjacent reporting systems, including enterprise rank tracking for agency reporting. Those systems remain secondary here. Position data describes discoverability conditions. Answer-surface data describes whether the model used the brand.
If reporting starts with clicks, the organization measures distribution and misses selection.
Independent verification is now a buying requirement
AEO measurement fails when the provider controls the definitions, the sampling, and the proof standard. That model produces attractive dashboards and weak executive confidence.
Our research team uses a stricter standard called verification-grade visibility. A reported gain counts only if the client can inspect the prompt set, review the answer outputs, understand how citation or mention status was assigned, and validate changes outside the vendor's interface. Anything weaker belongs in a sales deck, not in a board report.
This is the procurement test that matters. Can the service explain how prompts are selected, how often answer surfaces are re-tested, how competitive baselines are maintained, and how business outcomes are mapped to observed answer presence? If those mechanics are vague, the ROI model is also vague.
The strongest AEO programs do not begin with attribution software. They begin with repeatable evidence that the brand is appearing in the answers that shape demand, then connect that visibility to branded search lift, qualified traffic patterns, lead velocity, and revenue influence through the wider analytics stack.
For Chapter 1 context, see Return to Chapter 1. To discuss application, book a complimentary AI visibility assessment with a utm_source=blog6 reference.
Conclusion The New Mandate for Enterprise Marketing
Enterprise marketing has crossed a systems boundary. Visibility is now determined inside model inference, retrieval layers, and answer selection logic, not only inside ranked link inventories.

A buyer checklist separates real services from surface tactics
This changes the procurement standard. An AEO service should be judged by its model logic, measurement discipline, and implementation method. Tactical content refreshes, schema patching, and prompt anecdotes do not meet that bar because they do not explain how a brand becomes retrievable, extractable, and citable across shifting answer environments.
Our lab treats reverse-engineering of LLM behavior as the only reliable foundation for answer engine optimization services. That means examining retrieval triggers, passage selection patterns, citation propensity, semantic compression, and failure modes by platform. Services built without that layer usually optimize for visible artifacts while ignoring the architecture that produces them.
A practical enterprise checklist follows:
Cross-engine observation: Does the provider track answer presence across multiple AI systems instead of reporting from a single surface?
Metric definitions: Can the provider define citation, mention, answer share, and saturation in operational terms that another analyst could reproduce?
Architecture model: Can the provider explain how its work changes retrievability, extractability, and answer eligibility at the document level?
Independent validation: Can the client inspect prompts, outputs, and scoring rules outside the vendor interface?
Recalibration process: Is there a documented method for retesting as model behaviors, retrieval sources, and answer formats change?
This is the new mandate. Enterprise teams need an AI visibility program built on architecture analysis, evidence clustering, and verification-grade measurement.
The old SEO assumption was simple: publish more, rank more, win more. AI systems break that chain. They compress, synthesize, and select. Brands gain visibility when their information is structured for model uptake and repeated under competitive prompt conditions, not when they merely expand content volume.
For Chapter 1 context, see Return to Chapter 1. To discuss application, book a complimentary AI visibility assessment with a utm_source=blog7 reference.
Algomizer helps brands improve visibility inside AI-generated answers across systems such as ChatGPT, Gemini, Claude, Perplexity, and Google AI Overviews. Teams that want a practical assessment of current AI-answer visibility can book a call with Algomizer.