
Generative Engine Optimization GEO Services: The 2026 Guide
Explore Generative Engine Optimization (GEO) services. Our 2026 guide explains GEO vs. SEO, vendor selection, pricing, and how to win visibility in AI answers.

Subtitle: Generative engine optimization GEO services as an engineering category, not a content add-on
May, 2026
The market has framed GEO too narrowly. Many search programs still treat AI visibility as a publishing adjustment layered onto SEO, even though generative systems evaluate a different object entirely.
ChatGPT, Gemini, Claude, and Perplexity do not primarily reward pages. They assemble answers. They compress multiple sources, extract claims out of context, and cite selectively. Under that architecture, brand visibility depends less on rank position and more on whether a model can interpret, verify, and reuse the underlying evidence with low ambiguity.
Commercial interest has already moved in that direction. Industry forecasts cited earlier describe a fast-expanding GEO services category, which signals budget migration, vendor formation, and rising executive scrutiny. We interpret that pattern as a market structure change rather than a short-cycle services trend.
That distinction matters.
GEO belongs in the same decision frame as analytics instrumentation, conversion architecture, and paid acquisition measurement. It requires engineered content structures, explicit entity relationships, citation-ready evidence models, and controls that connect answer visibility to commercial outcomes. Editorial quality still matters, but editorial quality alone does not produce durable inclusion in generated answers.
We find that the strongest GEO programs are built like systems. They define machine-readable proof, measure retrieval fitness, and assign accountability to performance metrics that marketing leaders can audit. For that reason, investment decisions should move beyond deliverables such as content refreshes or prompt tracking. The strategic question is whether a partner can engineer answer eligibility, verify visibility gains, and tie that work to revenue-bearing demand.
Table of Contents
Executive Summary
Traditional authority signals are no longer sufficient
GEO changes the budget logic of search
From Page Ranks to Answer Ranks The New Search Architecture
The optimization target has changed
SEO and GEO operate on different units of value
The Algomizer Framework for Engineering Truth
Evidence Clusters create citation-ready structure
Semantic Density determines machine readability
Mapping the Five Pillars of GEO Services
How to Select a Verifiable GEO Partner
Most vendors can describe visibility but not prove business impact
The buying checklist should filter out vanity reporting
A Practical GEO Implementation Roadmap and Outcome Models
Verified Performance Metrics and Case Studies
The category is real. Proof quality is the differentiator.
What counts as verified performance
Case-study standards that withstand scrutiny
Executive Summary
Traditional authority signals are no longer sufficient
The market is misframing GEO. Many teams still treat generative engine optimization GEO services as a content extension to SEO, then evaluate vendors with traffic-era logic. That framing is too narrow for the systems now mediating discovery.
Generative search platforms such as ChatGPT, Gemini, Claude, and Perplexity assemble answers from evidence they can parse, attribute, and reuse. As noted in Contentful's explanation of generative engine optimization, that shift changes the reporting layer toward brand mentions, reference rates, and query coverage. It also changes the production layer. The winning asset is no longer merely a page that can attract a click. It is a source object engineered for extraction, interpretation, and citation.
That distinction has direct investment consequences. A page can retain strong search authority and still underperform in generative interfaces if its answer span is hard to isolate, its entities are weakly resolved, or its claims lack supporting context. A narrower asset can outperform a stronger domain when the underlying information architecture makes reuse easy for the model.
Traditional SEO asked whether a page could rank. GEO asks whether a model can safely reuse the page's meaning.
We therefore define GEO as an operating capability with measurable inputs and outputs. It combines content design, schema implementation, entity reinforcement, model testing, and answer-level observability. For marketing leaders, this shifts GEO from an experimental line item into an engineering discipline that can be scoped, benchmarked, and purchased against outcomes.
GEO changes the budget logic of search
The budget question is more important than the terminology question.
As answer interfaces absorb more discovery behavior, spend allocated only to traffic capture leaves a growing share of visibility unmanaged. Brands now need systems that influence whether they appear in the answer, how they are framed, and which claims are attached to their name. This is why demand is moving toward audits, content engineering, technical implementation, and monitoring across models instead of rank tracking alone.
We see three planning implications.
Visibility becomes compositional: Generative systems assemble responses from passages, entities, citations, and source attributes rather than from a single ranked page.
Authority becomes operationalized: Authorship signals, evidence structure, and machine-readable formatting increase the probability that content is selected for reuse.
Measurement requires a new control layer: Teams need observability into AI outputs and citation behavior, alongside session analytics.
The commercial consequence is straightforward. Organizations that govern search with rank reports alone will miss the interface layer where buyer perception is increasingly formed. Organizations that fund answer visibility as a measurable system can evaluate GEO with the same rigor they apply to paid media, conversion infrastructure, and revenue attribution.
Algomizer provides managed GEO visibility programs for brands that need answer-level measurement, technical implementation, and commercial accountability. Teams that want to assess current exposure can book a call with Algomizer.
From Page Ranks to Answer Ranks The New Search Architecture
The optimization target has changed
The market has been slow to price in a basic architectural fact. Generative search does not allocate visibility the way web search did.

Classic search engines evaluate pages and then rank URLs for a query. Generative systems process a prompt, retrieve supporting material, and compose an answer that may quote, compress, or blend multiple sources. The visible output is an answer object, not a results page. That shift changes where value is created and where it is lost.
A short technical walkthrough helps anchor the shift.
For operating teams, the immediate implication is practical. The content asset competing for inclusion is often a passage, claim block, entity definition, or citation-ready segment inside a page. If that unit is explicit, attributable, and low in ambiguity, it has a higher probability of surviving retrieval and synthesis.
We treat this as an engineering problem. The task is to design content and supporting signals so the model can extract a fact pattern with minimal transformation cost.
SEO and GEO operate on different units of value
The architecture shift becomes clearer when the systems are compared at the level of retrieval logic and commercial output.
Dimension | Traditional SEO | Generative Engine Optimization (GEO) |
|---|---|---|
Primary goal | Rank pages and earn clicks | Appear, get cited, and be framed favorably inside AI answers |
Core unit | URL or page | Answer span, content chunk, entity |
Main interface | Search results page | Direct-answer interface in ChatGPT, Gemini, Claude, Perplexity |
Key signals | Relevance, links, page-level authority | Extractability, entity clarity, reference worthiness, model-readable structure |
Primary output | List of links | Synthesized response with selective citations |
Measurement focus | Rankings, clicks, traffic | Mentions, reference rates, query coverage |
This comparison matters because budget decisions often lag interface changes. Many marketing organizations still fund search around page performance while buyer interpretation is increasingly shaped inside answer environments. A page can retain organic strength and still fail to supply reusable evidence to a model.
Practical rule: If a claim cannot be isolated, attributed, and understood by a model without surrounding page context, it is weak GEO material.
We also find that governance has to change. Answer visibility requires its own instrumentation, QA process, and vendor criteria because the system is optimizing for retrieval fidelity and synthesis utility rather than for page rank alone. That is the strategic rationale behind AI search engine optimization frameworks and why Algomizer scopes GEO work as a measurable operating layer, not a content add-on.
Teams evaluating implementation support can book a call with Algomizer.
The Algomizer Framework for Engineering Truth
Evidence Clusters create citation-ready structure
Generative systems don't reward persuasive prose. They reward structured meaning that can survive extraction.
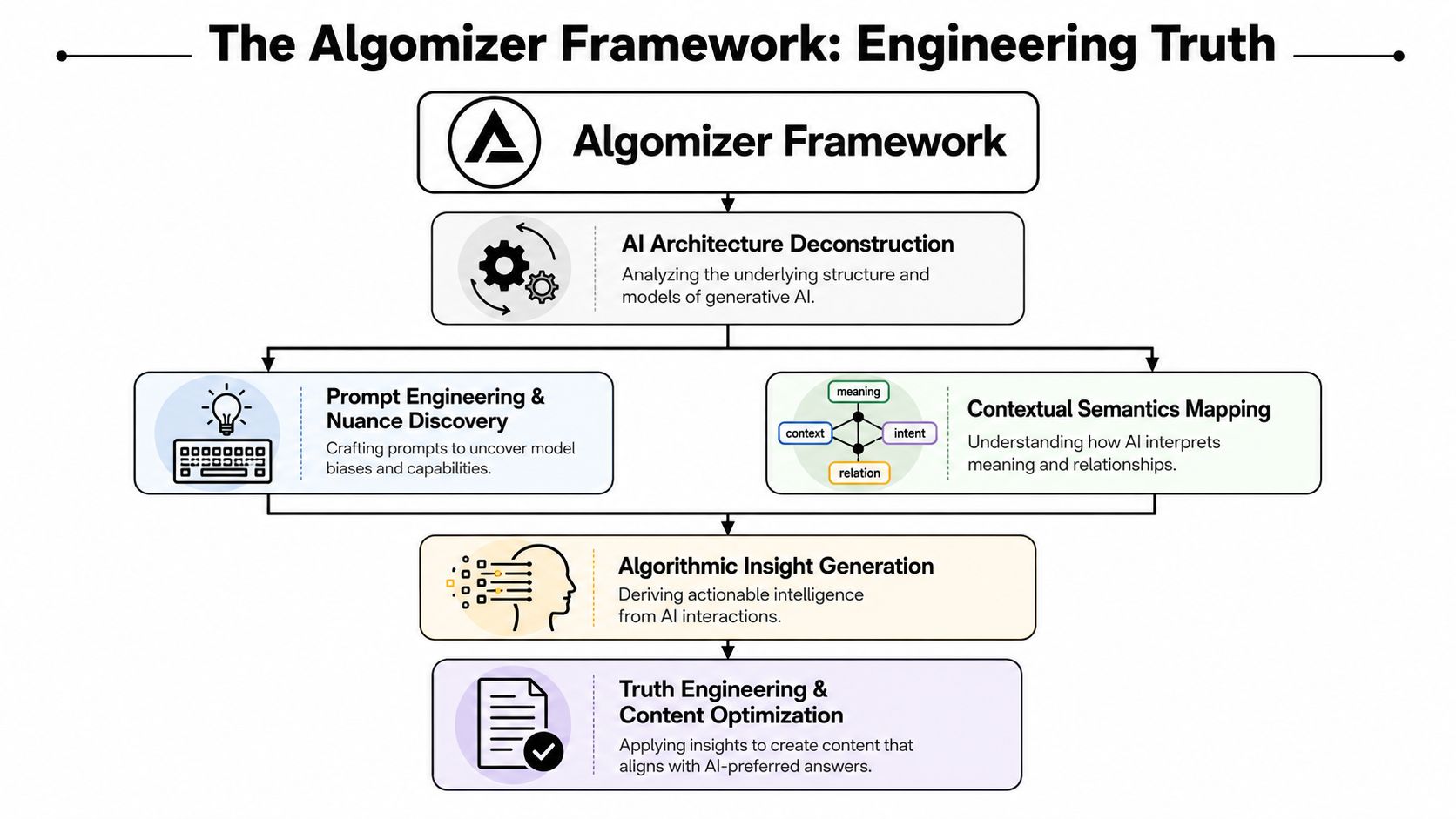
The first proprietary construct in this paper is Evidence Clusters. An Evidence Cluster is a bounded content unit that contains a direct answer, supporting context, clear entity references, and visible proof signals such as authorship or source framing. The purpose is simple. When a model retrieves a passage, it should encounter a complete, stable, low-ambiguity answer package.
That logic matches established GEO guidance. Content should be machine-extractable through direct-answer openings, Q&A blocks, and schema such as FAQ, How-To, Product, and Organization markup, as described by Optimizely's GEO glossary. Those elements are not cosmetic. They reduce uncertainty in retrieval and synthesis.
An Evidence Cluster usually contains these engineered traits:
Direct-answer lead: The first lines resolve the prompt without forcing the model to infer the conclusion.
Entity anchoring: Brand names, products, categories, and relationships appear explicitly.
Supportive context: The surrounding copy clarifies when the answer applies and why.
Attribution signals: Authorship, expertise framing, and organizational identity remain visible.
Semantic Density determines machine readability
The second construct is Semantic Density. This is the concentration of machine-usable meaning inside a content unit relative to its length.
High Semantic Density doesn't mean keyword stuffing. It means a passage contains crisp definitions, unambiguous nouns, explicit relationships, answer-first syntax, and markup that helps a model determine intent. Low Semantic Density reads smoothly to a human but forces the model to guess.
A simple editorial pattern illustrates the difference.
Low Semantic Density | High Semantic Density |
|---|---|
Broad introductory copy with implied subject | Direct answer naming the brand, offer, and use case |
Vague references such as “this solution” | Explicit entity references such as product, company, category |
Long paragraphs mixing many ideas | Distinct Q&A blocks and answer spans |
No structured markup | FAQ, How-To, Product, or Organization schema where relevant |
For teams redesigning their content libraries, the shift sees engineering replace folklore. A GEO program should score pages by extractability, entity resolution, answer span quality, and schema completeness, then revise content in that order.
A technical explainer on how AI search engine optimization works provides a useful companion for teams building internal process around these principles.
Truth engineering is operational when marketing can specify the answer units a model should find, verify that those units are parseable, and monitor whether they are reused. Teams that want that discipline operationalized can book a call with Algomizer.
Mapping the Five Pillars of GEO Services
GEO services are often sold as content support. That framing is too narrow to guide budget, staffing, or vendor selection. We find that a credible GEO program operates as an engineering system with distinct inputs, controls, and observable outputs.
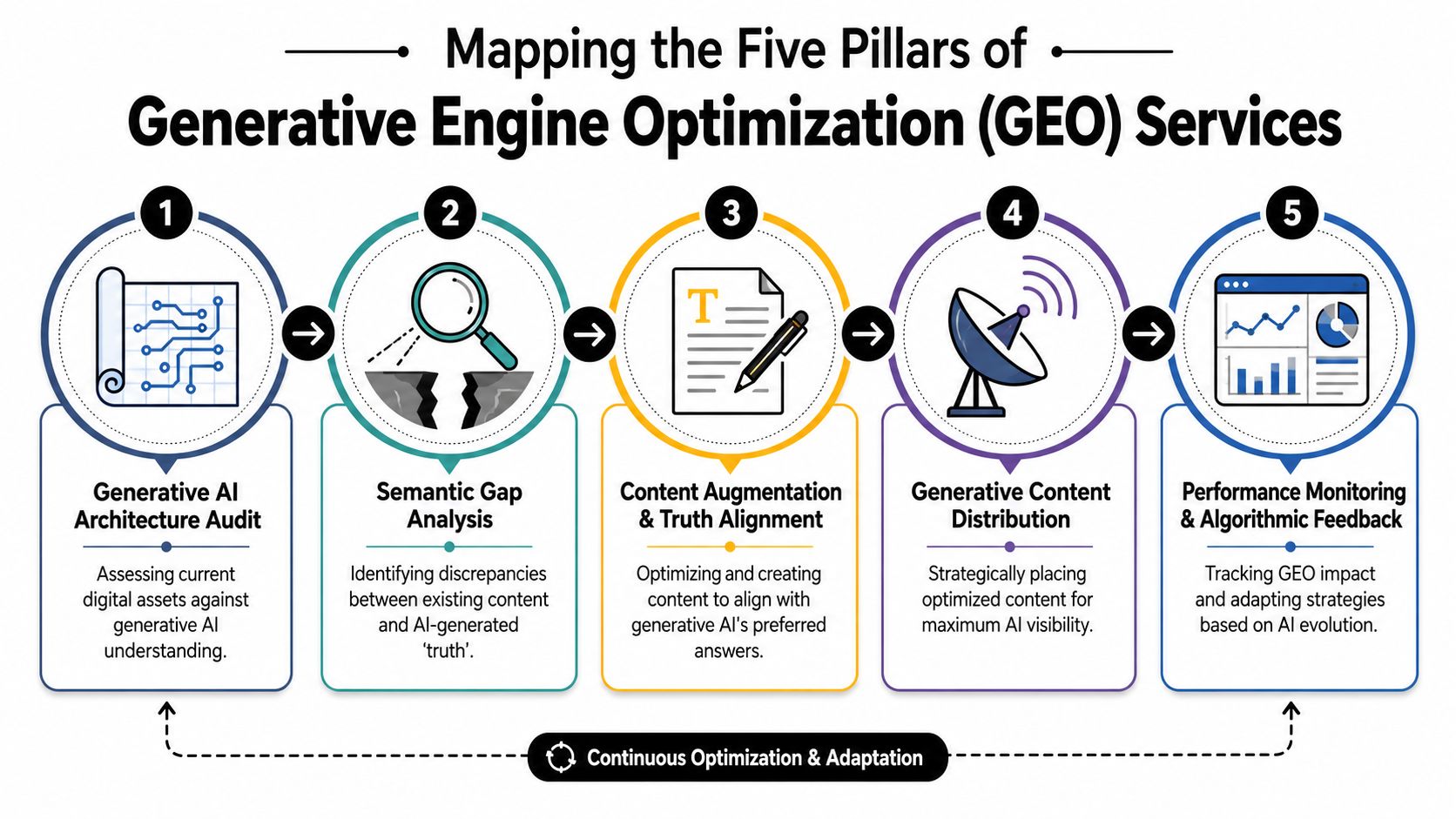
The work clusters into five pillars. Each pillar answers a separate operational question, and weakness in one tends to suppress returns from the others.
Visibility assessment and opportunity discovery
Teams test commercially relevant prompts across major AI interfaces, document whether the brand appears, and identify where publishers, review sites, or competitors currently shape the answer set. The output is a prompt universe tied to revenue themes, not a loose collection of screenshots.Content engineering and strategic media placement
Owned content is rebuilt into citation-ready answer units, while external placements strengthen the entities and claims that models repeatedly retrieve. This pillar determines whether a brand can supply machine-readable evidence at the moment an answer is assembled.Technical implementation
Schema, authorship signals, organizational identity, crawl accessibility, and internal content relationships are configured so retrieval systems can resolve who the brand is, what it offers, and which pages carry authoritative answers. Technical work reduces ambiguity. In GEO, ambiguity lowers inclusion rates.Verifiable measurement and calibration
Teams run repeated prompt tests, compare answer outputs across platforms, and monitor whether content changes affect mentions, citations, and source inclusion. This creates a feedback loop that supports resource allocation instead of intuition.Competitor intelligence and alerting
Programs track which domains gain citations, where answer framing shifts, and which prompt classes create emerging commercial exposure. The point is early detection. By the time a traffic report shows damage, the answer layer has often already moved.
A managed GEO service should deliver operating artifacts inside each pillar: prompt libraries, source-gap analyses, content specifications, schema requirements, test protocols, and decision rules for iteration. Advisory memos alone do not create answer visibility.
Measurement deserves separate scrutiny because it determines whether the program can be governed. Percepture's GEO services guidance reflects a broader industry shift toward direct observation of AI outputs, mention tracking, referral behavior, and browser-based validation. The implication is straightforward. Performance review must begin at the answer layer itself.
Two standards follow from that requirement.
Dashboards must inspect outputs directly: Reporting has to capture what ChatGPT, Gemini, Claude, or Perplexity display for priority prompts.
Optimization must map intervention to observed change: Content revisions, technical updates, and media placements should be evaluated against changes in mentions, citations, and answer coverage.
A rank report describes discoverability. A citation observability layer shows whether the brand is present inside AI-mediated buying research.
Algomizer operates in this category with headless-browser tracking, prompt discovery, competitor monitoring, and managed implementation for AI-answer visibility. Teams comparing service models can review what defines an SEO AI agency before deciding whether they need software, execution support, or an outcomes-based engagement.
How to Select a Verifiable GEO Partner
Most vendors can describe visibility but not prove business impact
The hardest buying question in GEO is whether that visibility can be tied to business outcomes in a way a finance team will accept.
Andreessen Horowitz argues that GEO is becoming the system of record for LLM interaction and notes that new tools are tracking presence, sentiment, and source influence across AI answers. The unresolved issue is attribution: most services still struggle to tie AI citations to pipeline and revenue in an independently auditable way, as discussed in a16z's analysis of GEO over SEO.
That gap matters most in categories where budgets are scrutinized. If AI answers reduce clicks, a dashboard showing mentions alone won't settle the investment case. A partner has to show how answer visibility connects to branded search behavior, qualified visits, assisted conversions, or downstream demand signals without asking buyers to trust a black box.
The buying checklist should filter out vanity reporting
A procurement team should use disqualifying questions, not broad capability decks.
What to ask | Why it matters |
|---|---|
Can the vendor verify citations across multiple AI platforms directly? | GEO happens in outputs, not in slideware summaries |
Do reports separate mentions, references, and referral behavior? | Conflating them hides whether the brand is actually being used as a source |
Is attribution independently auditable? | Finance and compliance teams need defensible evidence |
Does the commercial model align to retained visibility or only activity delivered? | Incentives shape execution quality |
Can the vendor operate without direct system access or PII? | Enterprise adoption depends on controlled risk |
A second screen should test technical depth. Ask how the vendor handles answer-span engineering, schema deployment, headless-browser measurement, and prompt-set design. If the answer remains at the level of “better content” or “AI-friendly blogs,” the operating model is too shallow.
The decision framework described in Algomizer's article on what an SEO AI agency should actually prove is a useful benchmark for this diligence process.
A credible GEO partner should behave less like an agency selling output and more like an engineering function selling observable control. Teams that need that standard can book a call with Algomizer.
A Practical GEO Implementation Roadmap and Outcome Models
GEO programs fail when teams treat production as progress. The sequence that works starts with instrumentation, because answer visibility must be measured before it can be improved or priced.
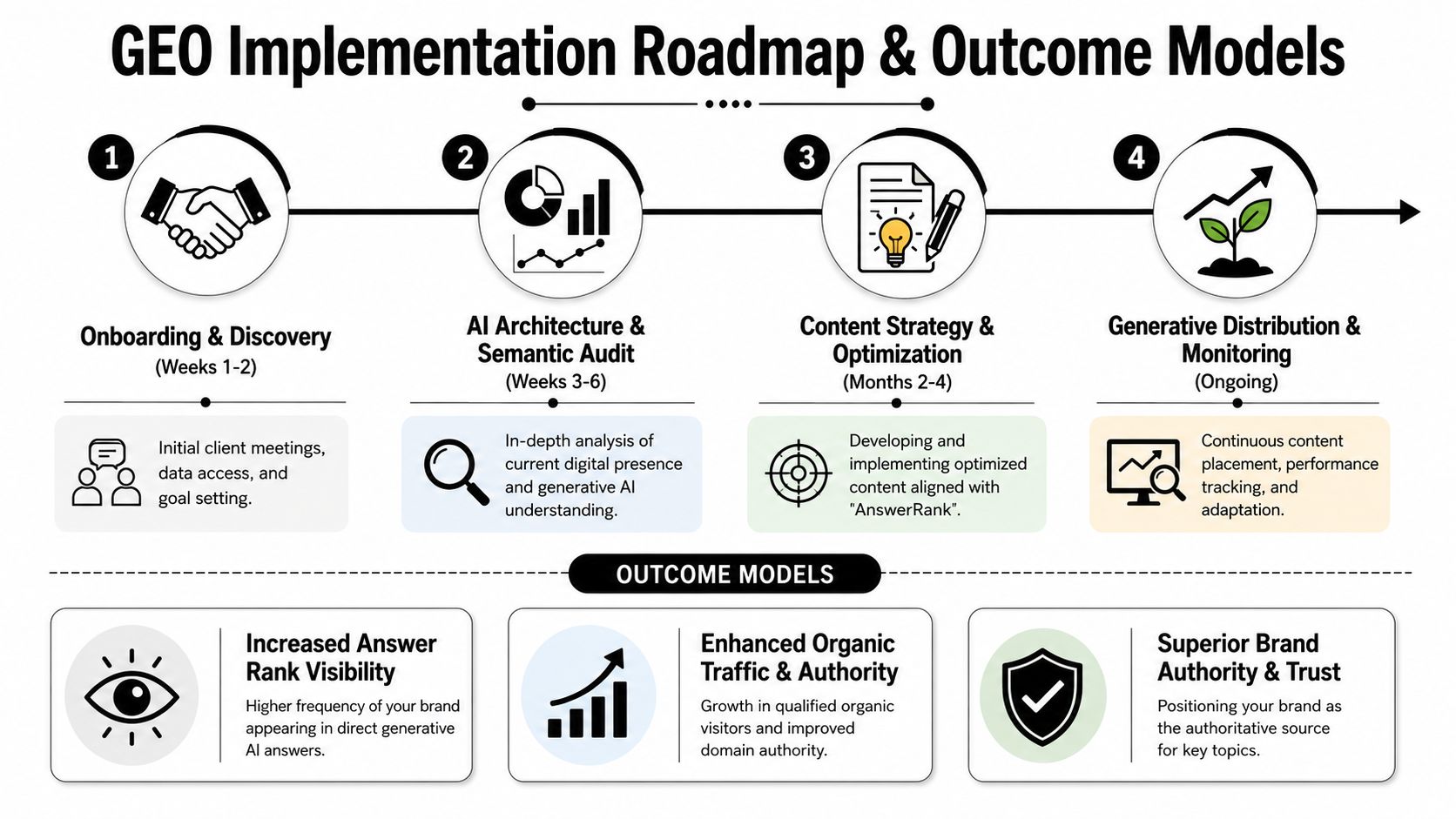
The first phase is prompt-market mapping. We define the prompt universe by commercial intent, entity type, and model behavior. That set should include branded questions, category questions, comparison prompts, implementation queries, and objection-driven prompts across the AI systems buyers already use. The output is a test environment.
The second phase establishes a control baseline. Teams should record whether the brand appears, whether it is cited directly or paraphrased, how the answer frames the company, and which competing sources shape the response. This is the point where GEO becomes an engineering discipline. Without a baseline, there is no valid way to separate real answer-share gains from normal model variance.
Measurement quality matters as much as execution quality. Teams that need a repeatable method should study reliable citation analysis for AI search engines, because weak attribution design produces false confidence and poor budget decisions.
The third phase is remediation. We have found that the highest-yield work usually sits at the intersection of entity clarity, extraction readiness, and source trust. That means rewriting answer spans for direct retrieval, reducing ambiguity in product and company naming, improving schema coverage, tightening authorship and evidence signals, and restructuring pages so models can extract a coherent claim without guessing across scattered paragraphs.
Then comes retesting.
Retesting is the operating loop. AI systems change retrieval preferences, citation behavior, and answer formatting regularly, so GEO teams need scheduled re-measurement against the same prompt sets and competitors. That creates a closed system: observe, modify, verify, repeat. Marketing leaders should expect this cadence if they want controlled outcomes rather than intermittent wins.
A practical implementation roadmap usually includes four workstreams:
Prompt environment design: A prioritized prompt set tied to pipeline value, brand risk, and buyer-stage relevance.
Baseline observability: Output logging for mentions, citations, source overlap, and answer framing across target engines.
Content and technical remediation: Answer-span rewrites, schema and authorship updates, entity normalization, and extraction-oriented page structure.
Verification cycles: Scheduled reruns, competitor comparisons, and revision queues based on observed answer changes.
Commercial models should follow the same logic. GEO should not be sold primarily as hours, blog volume, or generalized “AI content” activity. Those inputs are too far removed from the business outcome. A stronger model ties compensation to retained visibility across a defined prompt set, verified citation presence, or other auditable answer-level indicators. That structure improves incentives on both sides. Vendors are pushed toward measurable control, and internal teams can explain spend in terms that finance can inspect.
The mature buying posture is straightforward. Purchase GEO as a monitored system with baselines, intervention logs, and outcome definitions. Teams that want operator support can book a call with Algomizer.
Verified Performance Metrics and Case Studies
The category is real. Proof quality is the differentiator.
Market adoption no longer needs a defense. As noted earlier, external market coverage already establishes that GEO services have moved into formal budget discussions. The unresolved question is narrower and more important. Which interventions produce repeatable gains in AI answer visibility, and which reporting methods can survive procurement review?
That distinction separates GEO as content activity from GEO as an engineering discipline.
In our review of vendor claims across the category, the pattern is consistent. Public case studies often describe visibility gains at a high level but omit the measurement design needed to verify causality. Screenshots without prompt sets, citation counts without rerun intervals, and traffic narratives without answer-level logs do not meet the standard required for strategic investment. Marketing leaders should treat those materials as directional evidence, not operating proof.
What counts as verified performance
A credible GEO measurement system tracks the output layer first, then connects that output to commercial indicators with explicit assumptions. We recommend four evidence classes.
Answer-level visibility records: Time-stamped logs showing whether a brand appears, how it appears, and which sources the model cites across a fixed prompt set.
Citation stability analysis: Repeated measurement of source inclusion across engines, prompts, and test windows to distinguish persistent presence from one-off mentions.
Intervention traceability: A revision record linking specific content, schema, authorship, or entity changes to subsequent answer shifts.
Commercial attribution logic: A documented method for relating answer visibility to pipeline metrics without overstating certainty.
This standard is stricter than traditional SEO reporting because the object being measured is different. Rankings are ordered lists. AI answers are synthesized outputs with variable phrasing, selective citation, and model-specific retrieval behavior. Performance evaluation therefore has to measure retrieval, extraction, framing, and citation retention together.
That is also why proprietary metrics matter when they are transparent in design. At Algomizer, we treat measures such as Semantic Density as operational metrics only if they can explain observed answer changes and be tested against competitor controls. A metric that cannot predict or explain output movement is branding.
Case-study standards that withstand scrutiny
Executives evaluating GEO partners should ask for case evidence in a format that resembles an experiment log more than a sales narrative.
Useful case documentation includes the target prompt cluster, baseline answer snapshots, the exact site or entity changes made, the elapsed time to re-evaluation, and the observed change in mentions or citations across engines. It should also specify what did not change. Without that counterfactual discipline, vendors can claim success during periods when model updates or news cycles altered answers for unrelated reasons.
For teams building internal review criteria, our framework for reliable citation analysis for AI search engines provides a practical reference point. The key test is simple. Can the partner show how visibility was measured, why the metric was chosen, and how the result was checked against noise?
Algomizer helps brands build verifiable visibility inside AI-generated answers across platforms such as ChatGPT, Claude, Gemini, and Perplexity. Marketing leaders that need prompt-level observability, technical implementation, and outcomes-based GEO execution can book a call with Algomizer.