
Generative Engine Optimization Tools: Win AI Search in 2026
Explore generative engine optimization tools. Discover capabilities, evaluation criteria, and a strategic framework to win AI search in 2026.

Subtitle: A Strategic Framework for Visibility in AI Search
May, 2026
Most advice about generative engine optimization tools starts in the wrong place. It starts with dashboards, mention tracking, and prompt scraping. That advice mistakes observation for control.
The harder truth is simpler. Brands don't win AI visibility because a tool noticed a citation. They win because the underlying content system gave a model enough evidence to retrieve, trust, and reuse the brand in an answer. Monitoring matters, but monitoring alone is a forensic activity.
That distinction is why Generative Engine Optimization has to be treated as an engineering problem, not a reporting layer.
Table of Contents
Executive Summary
Defining the GEO Tool Landscape
Four capability quadrants define the stack in practice
Our Framework for Engineering Trust
Semantic Density determines retrieval fitness
Evidence Clusters determine citation confidence
A Contrast of GEO Philosophies
Passive monitoring reports symptoms
Active optimization changes the source environment
Tactical Implications for Enterprise Teams
Indexability is the foundational gate
Governance determines whether GEO can scale
The Managed Service Workflow in Action
A six-week operating model makes GEO concrete
The output is measurable visibility, not activity volume
Conclusion The Shift to Answer Engineering
The unit of competition is now the answer
Executive Summary
The prevailing GEO tool category is built on the wrong assumption. Visibility counts are treated as if they were stable signals of authority, even though generative engines retrieve, rank, and synthesize information under different conditions.
That mismatch creates a measurement problem before it creates an optimization problem.
As discussed in Jakob Nielsen's GEO analysis, citation behavior varies across AI systems. A mention in one interface cannot be treated as equivalent to a mention in another. Prompt phrasing, retrieval settings, model updates, and answer formatting all affect whether a source appears. Teams that collapse those differences into a single score produce reports that look precise and behave unpredictably.
Practical rule: A citation metric becomes decision-grade only when the team can explain the retrieval conditions that produced it.
We therefore reject the conventional framing of GEO as a monitoring exercise. Monitoring has value, but it measures symptoms. Enterprise teams need a model for influence.
Our view is stricter. Generative visibility is the output of source engineering. The work starts with the conditions that make an answer retrievable, citable, and repeatable across engines. For readers who need a baseline definition, our guide to what generative engine optimization is and how it works establishes the operating context.
This is the core shift. The competitive unit is no longer the page alone. It is the answer assembly process itself.
We formalize that process through two constructs. Evidence Clusters describe whether a claim is supported across enough corroborating, machine-readable sources to merit citation confidence. Semantic Density describes whether a document carries enough precise, relevant, and well-structured information to survive retrieval and synthesis without being diluted. Together, they explain why some brands appear consistently while others appear only sporadically, even when both publish heavily.
The implication is practical. A team can buy every dashboard in the market and still fail to improve answer inclusion if the underlying source environment is weak. A smaller team with disciplined content architecture, clear entity signals, and dense evidence can outperform larger competitors because generative engines reward coherence before they reward volume.
That principle also explains a broader tooling pattern. Products built for observation help teams detect volatility. Products and services built for intervention change the probability of citation by changing the evidence base itself. Product leaders confronting adjacent workflow questions often streamline product management with AI. GEO requires the same discipline, but applied to retrieval systems, source structures, and model-facing trust signals.
We use that distinction throughout this article. The relevant question is which system helps a brand become easier for generative engines to trust.
Defining the GEO Tool Landscape
The GEO software market now exists as a distinct buying category, but buyers still misclassify what they are purchasing. Many teams evaluate GEO tools as reporting software, even though answer visibility depends on a chain of retrieval, entity resolution, evidence selection, and synthesis decisions that reporting alone cannot change.
A clearer market definition emerged as publishers and software vendors began grouping these products into a dedicated category, including tool roundups such as Contently's review of GEO tools in 2025. The significance is that buyers can now compare products by operational role instead of treating GEO as a vague extension of SEO.
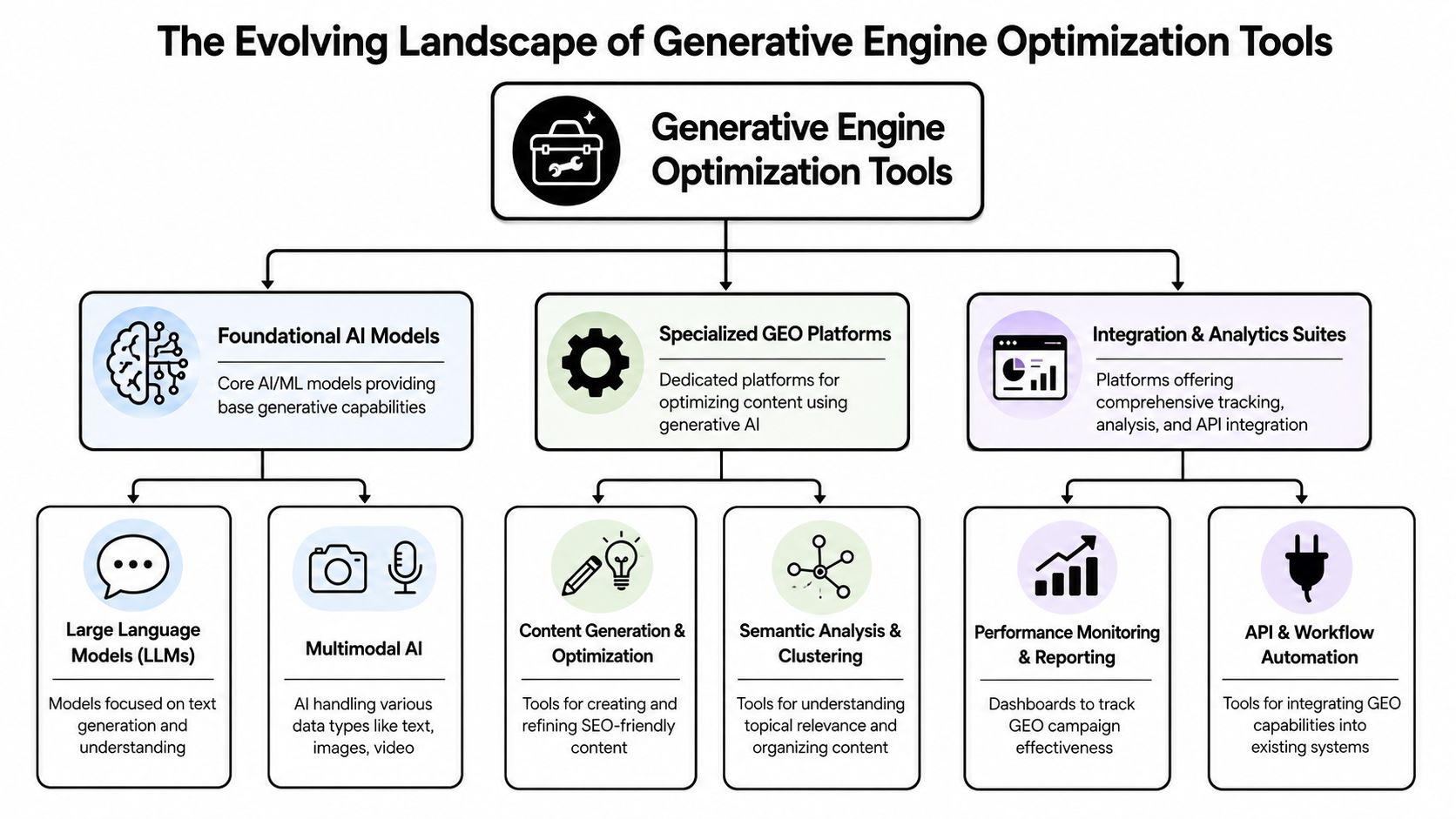
Four capability quadrants define the stack in practice
Enterprise buyers often ask for a single platform that can diagnose, plan, and change answer inclusion. The market does not work that way. In practice, the stack is better understood as four capability quadrants.
Quadrant | Answer-first definition |
|---|---|
Monitoring and Measurement | These tools track where a brand appears across AI answers, compare prompts across engines, and report visibility patterns. They rarely explain the source conditions that produced inclusion. |
Source and Entity Engineering | These tools or workflows strengthen entity clarity, improve source consistency, and align owned assets with the evidence structures generative systems can retrieve and reuse. |
Prompt Engineering and Discovery | These tools identify high-value prompts, reveal competitor presence, and map where engines ask for comparisons, explanations, or category definitions. |
Citation Shaping and Content Deployment | These tools or services convert strategy into publishable assets, revise document structure, and deploy machine-readable content that increases the probability of answer inclusion. |
The distribution across these quadrants is uneven. Monitoring products are common because measurement is easier to package. Intervention systems are less common because they require content operations, entity modeling, structured publishing, and editorial control.
That asymmetry produces a predictable buying error. Teams purchase observability, then expect causality. Product leaders have seen the same pattern in adjacent software categories, where teams try to streamline product management with AI and find that analytics, orchestration, and execution remain separate system layers.
We therefore classify GEO tools by whether they observe answer generation or alter its upstream inputs. That distinction matters more than vendor positioning. A dashboard can show citation volatility. It cannot, by itself, strengthen an Evidence Cluster, increase semantic precision, or make a brand easier for a model to trust.
For buyers comparing vendors, this survey of top Generative Engine Optimization platforms for AI is a useful category reference. The stronger conclusion is structural. No single platform consistently covers all four quadrants, which is why effective GEO programs are usually assembled as systems, not purchased as software alone.
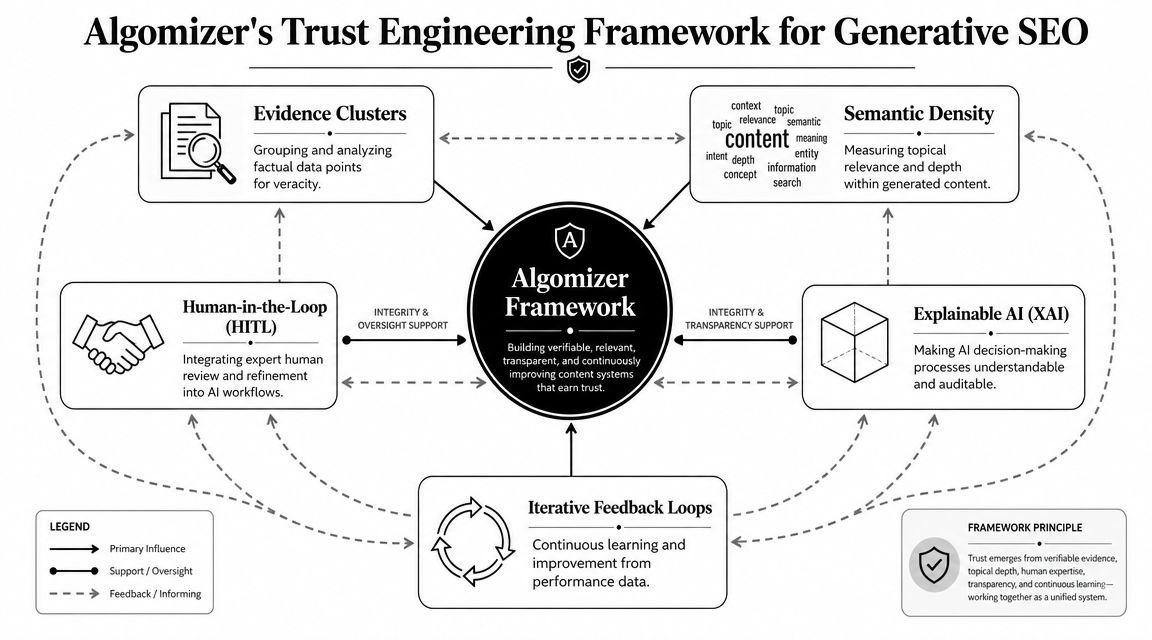
Our Framework for Engineering Trust
Generative engines don't reward content for sounding optimized. They reward content that behaves like a trustworthy source under retrieval and synthesis.
Semantic Density determines retrieval fitness
Independent GEO research points to entity and source-authority engineering as the highest-value optimization lever. Winning visibility in ChatGPT, Claude, Gemini, and similar systems depends on improving the likelihood that a brand is both retrieved and selected as a cited entity, as argued in Evergreen Media's GEO guide.
That principle leads to the first component of the Algomizer framework: Semantic Density.
Semantic Density is the concentration of verifiable facts, named entities, unambiguous claims, and context-rich explanations inside a content asset. A semantically dense page gives a model more usable material per passage. It reduces interpretive ambiguity. It increases the odds that retrieval systems find relevant spans and that generation systems can safely reuse them.
A sparse page can still rank in traditional search if other signals carry it. A sparse page struggles in generative retrieval because the model needs extractable evidence, not merely topical relevance.
Three properties define high Semantic Density:
Verifiable statements: Claims are precise enough to be attributed, checked, and reused.
Named entities: People, products, categories, standards, and platforms are clearly identified.
Context integrity: Each section stands on its own without forcing the model to infer missing meaning.
Evidence Clusters determine citation confidence
The second component is Evidence Clusters. A single article rarely creates durable AI trust on its own. Generative systems infer authority from patterns across documents, domains, mentions, and corroborating references.
An Evidence Cluster is a network of supporting proof around a topic. It includes the brand's core page, related supporting assets, consistent terminology, and credible third-party references that reinforce the same entity-topic relationship. The cluster matters because models don't just retrieve facts. They evaluate whether those facts fit a coherent external reality.
Conventional GEO advice collapses. Schema, headings, and FAQ blocks improve readability, but they don't establish truth by themselves. Truth in AI search is an engineered consensus signal.
A brand becomes citable when multiple signals agree on what it is, what it knows, and why that knowledge is credible.
That framework shifts the operating model for generative engine optimization tools. The tool is no longer the center of the system. The content graph is. Monitoring remains useful, but it becomes an audit layer on top of a trust architecture built for retrieval, selection, and synthesis.
A Contrast of GEO Philosophies
Two philosophies dominate the category. One records AI behavior. The other changes the conditions that produce AI behavior.
Passive monitoring reports symptoms
Passive monitoring treats GEO as a visibility score problem. The team watches prompts, logs citations, charts share of voice, and waits for movement.
That approach helps establish baselines. It reveals competitor presence. It can identify category-level prompt patterns. But it stops at observation.
Active optimization changes the source environment
Active optimization treats GEO as a systems problem. The team improves source material, strengthens entities, fixes technical blockers, and shapes answer-ready evidence that models can effectively use.
The difference becomes obvious when the two methods are compared directly.
Criterion | Passive Monitoring | Active Optimization |
|---|---|---|
Primary goal | Record brand mentions across AI interfaces | Increase the probability of trusted inclusion across AI answers |
Core metric orientation | Citation counts, sentiment snapshots, prompt logs | Retrieval readiness, entity strength, answer inclusion quality |
Main activity | Observe outputs after models respond | Engineer inputs before models respond |
Analytical depth | Surface-level reporting on where mentions happened | Structural diagnosis of why a brand is or isn't selected |
Technical scope | Usually limited to mention tracking | Includes content architecture, authority shaping, and technical eligibility |
Decision value | Useful for awareness and benchmarking | Useful for changing performance and allocating investment |
Expected outcome | Better reporting | Better visibility |
This contrast clarifies a mistake many leadership teams make. They ask whether a GEO tool can prove value before they ask whether the tool can create value.
The answer determines budget logic. Monitoring belongs in analytics spend. Optimization belongs in growth infrastructure.
Tactical Implications for Enterprise Teams
Enterprise GEO programs rarely fail because the team chose the wrong dashboard. They fail because the organization treats answer visibility as a reporting problem after the underlying retrieval and trust conditions have already broken down. We find the first enterprise question is not, "Which tool tracks citations?" It is, "Which system conditions allow a model to retrieve, parse, and reuse our evidence at all?"
Indexability is the foundational gate
Google states that its AI features depend on content that is crawlable, indexable, and eligible for Search features, as explained in Google's AI optimization guide. For enterprise teams, that point has direct operational consequences. A GEO platform that reports missing visibility without diagnosing retrieval blockers leaves the core failure mode untouched.
This is why citation monitoring alone is a weak procurement lens.
If a high-value page is excluded by robots directives, fragmented by poor canonical control, or buried in presentation-heavy templates, the model sees a degraded evidence surface. The problem is that the brand did not present machine-usable proof in a form the system could reliably ingest. That distinction matters because it shifts GEO from brand mention tracking to truth engineering.
We use a short audit sequence to test whether a brand's source environment can support answer inclusion:
Index coverage: Priority pages are indexed and available for downstream reuse.
Crawl access: Retrieval agents can access the assets that carry commercial and factual claims.
Canonical integrity: Duplicate or conflicting versions do not split authority across multiple URLs.
Parseability: Layout, schema, and copy structure preserve meaning for machines, not only for human readers.
Evidence density: Core claims are supported by adjacent facts, entities, and context rather than isolated marketing language.
A service-based operating model can close this gap when technical SEO, content operations, and AI visibility work sit with different owners. Our analysis of managed GEO services for AI visibility shows why enterprises often need workflow coordination more than another standalone interface.
Governance determines whether GEO can scale
The second constraint is organizational, not algorithmic. Enterprise teams often assume GEO requires broad platform access, customer data, or direct connections to sensitive systems. In practice, much of the work should rely on public outputs, public-facing assets, controlled testing, and implementation processes that fit existing security review.
That requirement changes vendor evaluation. The strongest GEO operating model is auditable and narrow in scope. It does not depend on personally identifiable information. It does not ask legal and security teams to accept unclear data flows in exchange for vague visibility scores.
The right diligence questions are procedural:
What data is required? Requests for customer records or unrelated internal systems usually signal poor scoping.
Can findings be reproduced? If prompt observations and visibility changes cannot be checked through repeatable methods, confidence is misplaced.
Who implements the fixes? Insight without deployment ownership turns GEO into an analytics artifact.
What is being optimized? Teams should distinguish between citation presence, source eligibility, and the harder problem of inclusion in answers grounded in strong evidence clusters.
The enterprise bottleneck is cross-functional approval for a method that engineering, legal, search, and content teams can each verify.
The procurement implication is straightforward. Enterprise teams should buy GEO capabilities the way they buy other technical infrastructure. Reliability, controlled access, reproducible measurement, and source-level remediation matter more than interface novelty.
The Managed Service Workflow in Action
Generative engine optimization fails in practice when teams treat it as a reporting cadence. The work only produces durable visibility when measurement, source revision, deployment, and validation run as one controlled system.
A six-week operating model makes GEO concrete
As noted earlier, market observations suggest that citation and answer-level visibility can shift on a short operational horizon when teams change the underlying evidence structure rather than publish generic net-new content. That makes a six-week cycle a useful unit of execution. It is long enough to implement source changes and short enough to isolate cause and effect.
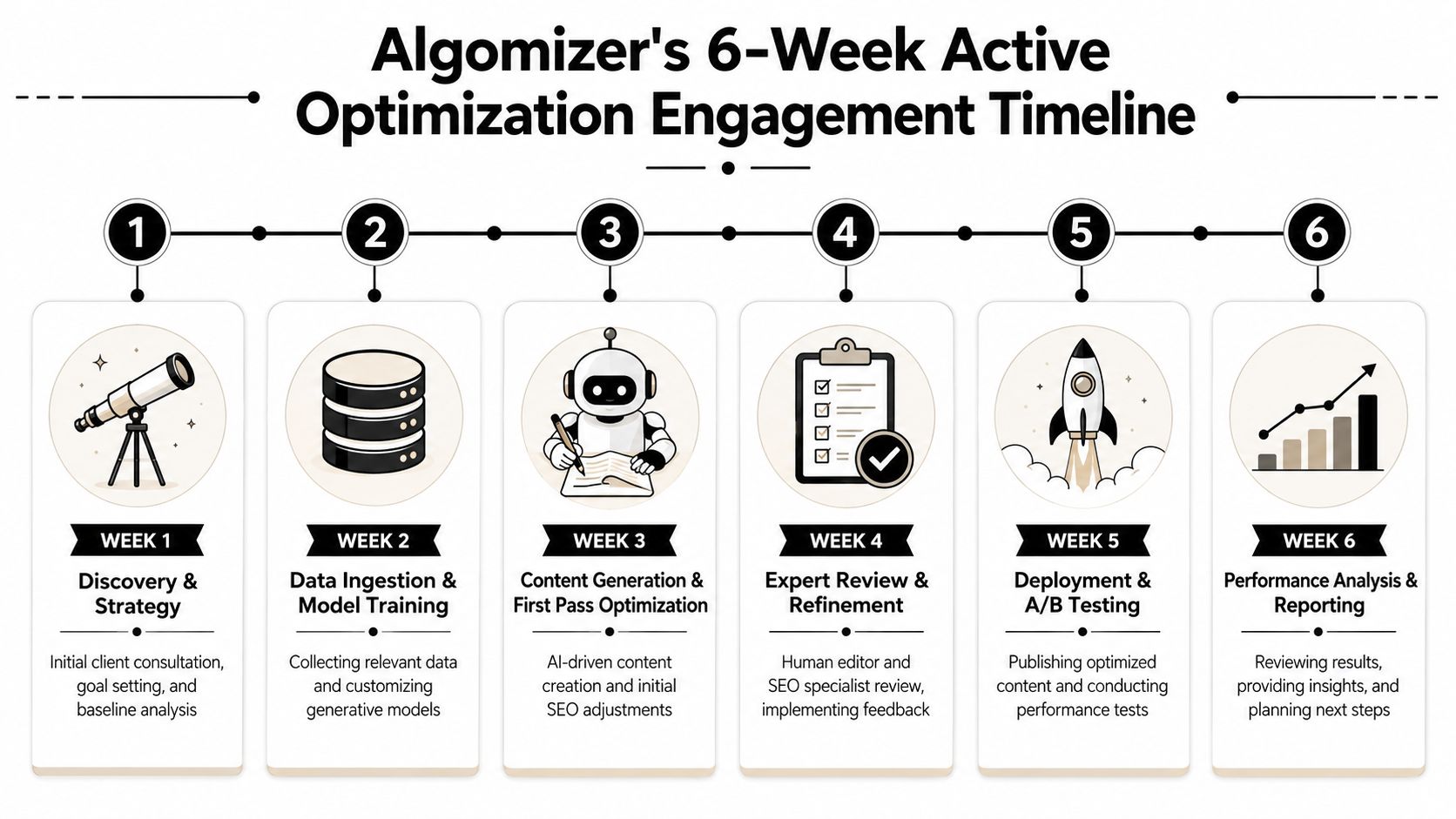
The sequence matters more than the calendar. A managed workflow should begin with retrieval and answer-surface diagnosis, then move into source engineering, then test whether the revised assets change inclusion patterns across target prompts and models.
A typical cycle looks like this:
Week 1: Visibility assessment across priority prompts, competitor source mapping, and failure analysis on missing or weak answer inclusion.
Weeks 2 and 3: Evidence Cluster design, entity clarification, citation path improvement, and revision of priority assets to increase retrieval fitness and synthesis confidence.
Weeks 4 and 5: Deployment, schema and structure calibration, supporting asset publication, and controlled prompt monitoring to check directional movement.
Week 6: Performance review, anomaly analysis, and reprioritization based on which source changes produced measurable gains.
This is an engineering loop for truth construction. The objective is to make the brand easier for generative systems to retrieve, verify, and reuse.
A visual overview helps illustrate the rhythm of that loop.
The output is measurable visibility, not activity volume
A managed service model changes the unit of evaluation. Teams should judge the program by movement in answer inclusion, citation quality, and source reuse across the selected market surface. Prompt counts and recommendation volume are process artifacts. They are not outcomes.
That distinction exposes a common flaw in conventional GEO programs. Many vendors monitor citations after the model has already formed a preference set. Fewer intervene upstream by improving Semantic Density, tightening entity relationships, and building Evidence Clusters that increase the probability of inclusion during retrieval and synthesis. Measurement without source-level remediation describes the problem with precision but rarely changes it.
Managed services persist because the tooling market is still fragmented. One platform may measure cross-model visibility. Another may identify content gaps. A third may support implementation. Enterprise teams usually need all three functions coordinated inside one operating method, with clear ownership and repeatable testing.
Within that context, Algomizer is one option that combines visibility assessment, media and content engineering, technical implementation, and ongoing calibration around AI-generated answers. The significance is operational. A managed model can reduce the distance between what generative engine optimization tools report and what enterprise teams can change.
Conclusion The Shift to Answer Engineering
The unit of competition is now the answer
The ten-blue-links mindset no longer explains how brands win discovery. Generative systems compress markets into answers, and those answers are assembled from sources that appear trustworthy under retrieval, selection, and synthesis.
That is why the phrase optimization is no longer sufficient. The operative discipline is Answer Engineering.
The paper's central conclusion is straightforward. Most generative engine optimization tools emphasize reporting because reporting is easier to productize than influence. But the durable advantage sits elsewhere. It sits in Semantic Density that improves retrieval fitness. It sits in Evidence Clusters that increase citation confidence. It sits in technical eligibility that keeps core assets crawlable and usable. And it sits in governance models that let enterprise teams execute without creating avoidable risk.
The strategic mistake is to confuse visibility measurement with visibility creation. A reactive posture can describe irrelevance with precision. It can't reverse it.
Marketing leaders need a different mental model. They are no longer competing to rank a page. They are competing to become the source material from which an answer is built. That shift changes tool evaluation, content architecture, measurement standards, and team design.
Readers who need the foundational background can revisit Chapter 1 concepts through Algomizer's earlier explainer on generative engine optimization. The important next step is operational adoption.
Brands that need an evidence-led visibility assessment can book a call with Algomizer. The practical starting point is a complimentary review of where the brand appears across major answer engines, what technical or entity gaps are blocking inclusion, and which prompts are worth engineering first.