
Where Does ChatGPT Get Its Information from? an Inside Look
Discover exactly where does chatgpt get its information from in 2026. Explore its data sources, fine-tuning, live search capabilities, and how brands shape its

Date: May, 2026
Most advice about AI visibility starts with the wrong model. It treats ChatGPT like Google with a chatbot interface. That framing fails because ChatGPT doesn't retrieve a single stored fact the way a search engine returns indexed pages. It generates answers from learned statistical patterns and, in some modes, supplements them with retrieved sources.
That distinction changes the entire visibility strategy for brands. If a marketing team still asks only how to rank a page, it is solving the last era's problem. The core problem is how an LLM assembles a believable answer from training data, instruction tuning, and selective retrieval.
The best question, to ask, is which parts of the information supply chain shape the answer a user finally sees.
Table of Contents
Executive Summary A New Architecture for Information
ChatGPT constructs answers instead of fetching them
Visibility now depends on information architecture
The Foundational Layer The Pre-Training Corpus
The Refinement Layer Fine-Tuning and Knowledge Cutoffs
Fine-tuning determines answer behavior, not just answer content
Knowledge cutoffs create a hidden lag in otherwise polished answers
The Dynamic Layer Retrieval-Augmented Generation
Traditional search returns options while AI search composes an answer
Our Framework Engineering Trust with Evidence Clusters
Evidence Clusters turn scattered mentions into machine-legible consensus
Semantic Density determines whether a claim survives retrieval
Tactical Implications for Generative Engine Optimization
The operating model has to change
The practical playbook is cross-functional
Conclusion From Information Retrieval to Reality Synthesis
The decisive question is how the model decides what is safe to say
Executive Summary A New Architecture for Information
The popular explanation is too shallow. ChatGPT does not pull facts from a single source, and it does not answer from a simple live index. It produces responses through an information supply chain with three distinct layers: pre-training, post-training refinement, and selective retrieval when the system needs fresher or better-supported material.
That architecture changes the visibility problem for brands.
A model does not need to "know" your company the way a person does. It needs enough repeated, legible, corroborated evidence to predict that your claims are safe to include in an answer. That is a different standard than classic SEO, where ranking one page for one query could carry most of the load.
ChatGPT constructs answers instead of fetching them
OpenAI has said the models behind ChatGPT are developed using publicly available internet content, third-party partnership data, and information from users, trainers, and researchers. The strategic implication is straightforward. An LLM is a synthesis system shaped by prior exposure, later behavioral tuning, and retrieval choices made at response time.
That distinction matters because answer quality is not determined only by whether a source exists. But by whether the model can assemble a response from evidence it has absorbed, patterns it has been trained to prefer, and sources it judges credible enough to use when retrieval is available.
For CMOs and content leaders, the consequence is immediate. Visibility in AI systems depends less on isolated publication and more on whether the same core narrative appears across enough contexts to form machine-readable consensus.
Practical rule: A claim published once is weak evidence. A claim repeated consistently across credible, topically related sources is safer for the model to synthesize.
Visibility now depends on information architecture
This is why "publish more content" often fails in generative search. Volume increases surface area. It does not automatically increase retrieval confidence, semantic consistency, or citation likelihood.
At Algomizer, we treat the problem as infrastructure. The harder question is how the system selects among competing fragments, resolves conflicts, and decides which claims are stable enough to present as an answer.
That is where the full supply-chain view becomes useful:
Foundational knowledge: Patterns learned before any user asks a question
Behavioral shaping: Post-training adjustments that affect summarization, refusal, prioritization, and tone
Dynamic retrieval: Source selection at answer time when the system seeks fresh, specific, or higher-confidence information
Once those layers are visible, the black box stops looking mysterious. It starts looking operational. Brands that want durable AI visibility need evidence that is repeated, citable, machine-legible, and aligned across the broader web.
Algomizer's assessment framework for AI visibility starts from that premise and turns it into a measurable operating model: strengthen the evidence environment, increase consistency across sources, and improve the odds that the model selects your version of reality.
The Foundational Layer The Pre-Training Corpus
ChatGPT does not begin with live research. It begins with exposure.
Before any user prompt arrives, the model has already absorbed patterns from a large pre-training corpus that includes public web content, licensed or partnered data, and selected human-produced examples used in model development, as noted earlier. That corpus forms the first layer in the information supply chain. It determines which concepts the model has seen often enough to represent with stability, which relationships it can reproduce, and which claims it can only approximate.
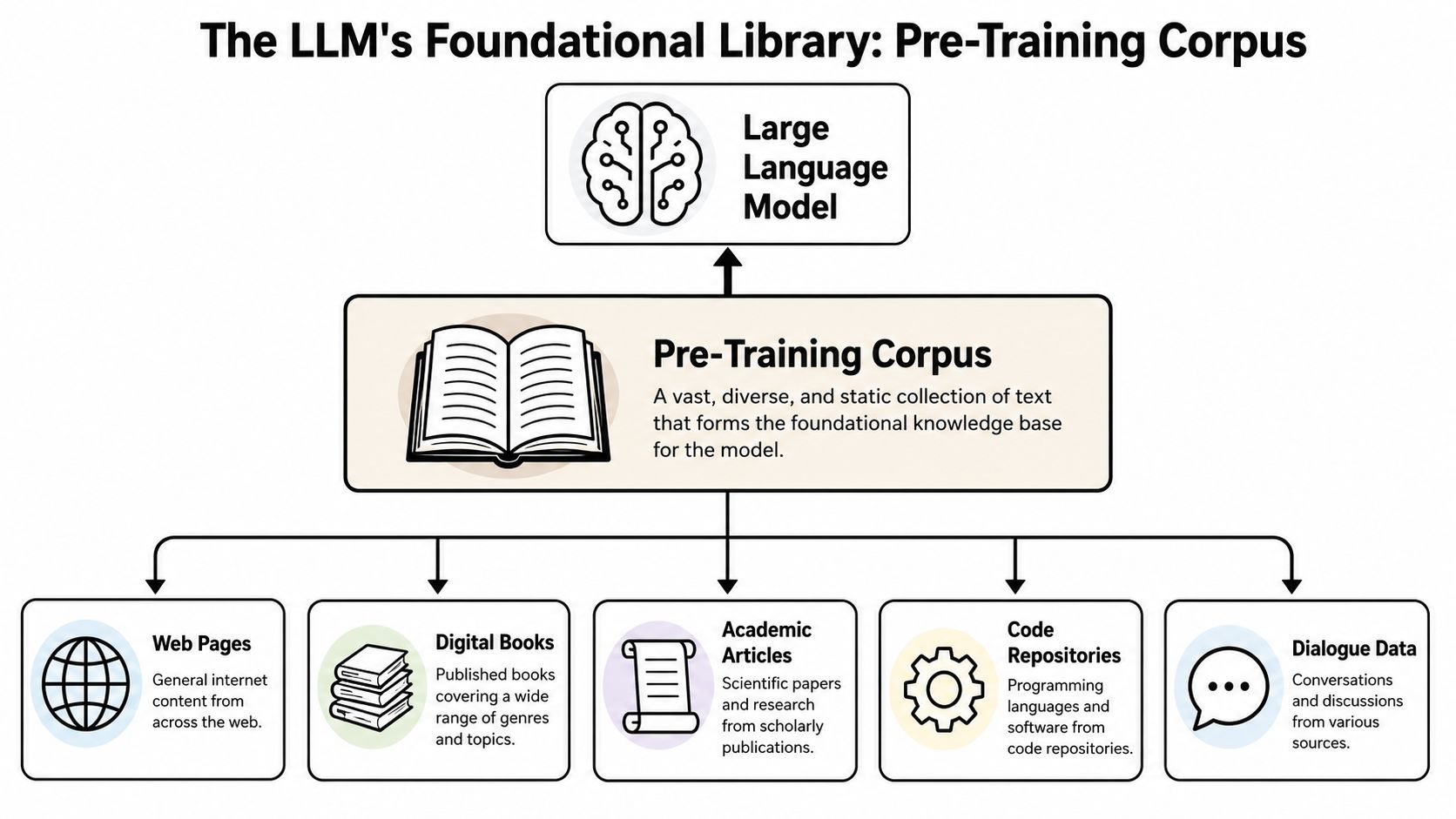
The right operating model is a frozen statistical memory, not a search engine. During pre-training, the system does not store neatly labeled facts the way a database does. It learns distributions. Which terms co-occur. Which explanations tend to follow which questions. Which entities are discussed together across many documents. That distinction matters because a model can sound informed about a topic long before it has a reliable internal representation of that topic.
For brands, the implication is sharper than "be online." Pre-training rewards repeated, machine-readable, cross-source consistency. A company with clear definitions, corroborating third-party mentions, and stable language across pages gives the model stronger raw material. A company that hides key details in gated assets, scattered PDFs, or inconsistent messaging leaves weak traces in the corpus.
This is the first place where visibility becomes an evidence problem.
A base model can only generalize from what the corpus made legible. If your category appears rarely, if your terminology conflicts across sources, or if your product claims exist mainly in sales collateral, the model has less signal to compress into durable knowledge. It may still generate a plausible answer. Plausibility is not the same as grounded representation.
That is why pre-training should be evaluated as supply-side exposure, not brand awareness. The question is whether the broader corpus contains enough aligned evidence for the model to internalize your category, your differentiators, and the factual boundaries around your claims.
At Algomizer, we treat this layer as upstream information infrastructure. Our Evidence Clusters framework starts here. A brand gains influence in model outputs when the same core facts appear in multiple credible, semantically related contexts. Pre-training does not guarantee citation or recency, but it does shape what feels native to the model versus what feels sparse, ambiguous, or absent.
The practical conclusion is simple. If knowledge is not publicly legible and repeated across the open information environment, it enters the model weakly or not at all.
Marketing teams that want an external assessment can book a complimentary AI visibility review through Algomizer.
The Refinement Layer Fine-Tuning and Knowledge Cutoffs
Fine-tuning is the control layer. It does not expand the model's world so much as rank which kinds of answers feel acceptable, helpful, and safe to produce.
That distinction explains why ChatGPT can sound authoritative even when its underlying information is old, incomplete, or weakly grounded. Post-training reshapes behavior. It teaches the system to follow instructions, organize responses, hedge in certain situations, and avoid classes of content that evaluators marked as risky or low quality. Users often read that polish as intelligence. Analysts should read it as optimization.
Fine-tuning determines answer behavior, not just answer content
A base model predicts plausible continuations. An assistant model has been pushed toward preferred response patterns through supervised examples, preference comparisons, and safety tuning. The result is a model that has learned more than syntax. It has learned presentation logic.
For brands, that changes the visibility problem. Inclusion in the training corpus is only one step in the information supply chain. The model also has to recognize your information as the kind of material it can reuse cleanly under post-training constraints. Content that is explicit, well-scoped, and easy to restate survives this layer better than copy built around slogans, unsupported superlatives, or vague category claims.
This is one reason our Evidence Clusters framework matters. Repetition across sources helps a fact enter the model at pre-training. Consistency in wording and scope helps that fact survive refinement without distortion.
Knowledge cutoffs create a hidden lag in otherwise polished answers
Fine-tuning does not solve recency. If retrieval is not activated, the assistant is still reasoning over a bounded historical snapshot, then expressing that snapshot with a more disciplined interface.
That creates a common failure mode. The answer sounds current because the delivery is clean. The informational substrate may still reflect an earlier version of the company, product, market, or terminology. In other words, refinement can mask staleness.
Brands should treat that as a formatting and evidence design issue. Material that holds up best through this layer usually has three traits:
Named entities stated plainly: product names, company names, and category labels appear in direct, repeatable language.
Claims with boundaries: the page specifies what is true, for whom, and under what conditions.
Paraphrase tolerance: the core meaning remains intact when the model compresses or restates it.
A sales page often fails here because its claims depend on tone. A source-of-truth page performs better because its claims depend on structure.
For teams examining the mechanics more closely, our analysis of how generative engine optimization works maps this refinement layer to the broader system that governs model visibility. Teams that want a category-level audit can book a complimentary AI visibility assessment with Algomizer.
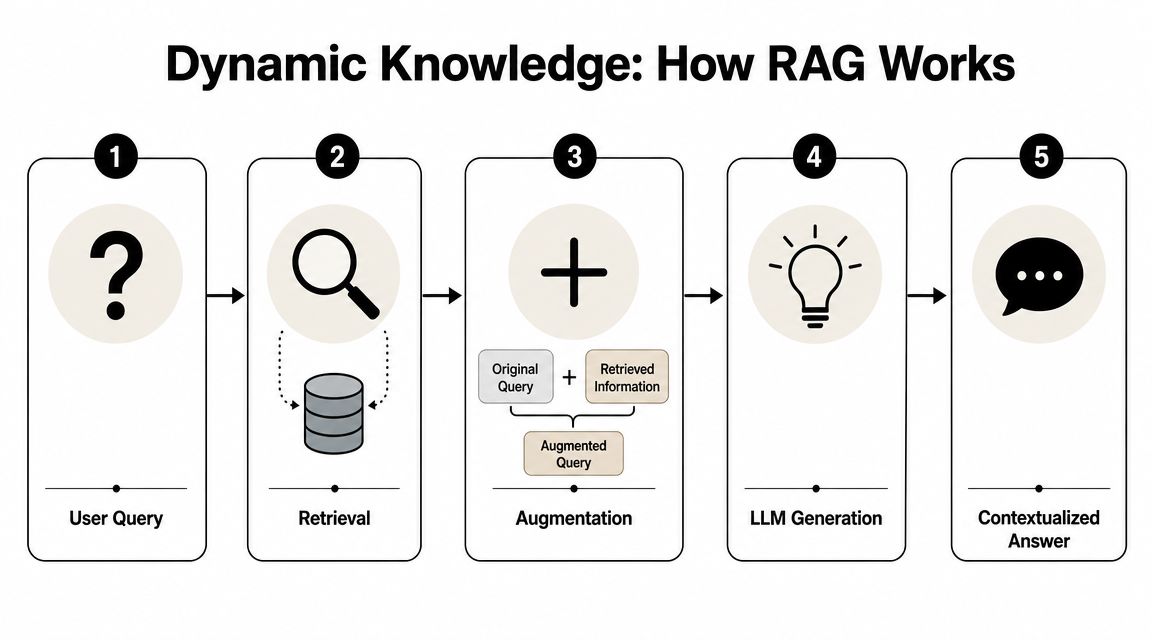
The Dynamic Layer Retrieval-Augmented Generation
The current answer is often assembled at query time, not recalled whole from training. That distinction explains why ChatGPT can sound static in one response and highly current in the next.
Retrieval-augmented generation, or RAG, is the system layer that makes that possible. The model first judges whether the prompt requires fresher facts, stronger grounding, or external verification. If that threshold is met, it issues retrieval requests, ranks candidate sources, extracts relevant passages, and then generates a response constrained by that evidence.
Independent analysis indexed on PubMed Central found that about 18% of conversations triggered at least one web search and that Wikipedia appears in nearly 1 in 6 cited conversations, according to this analysis of ChatGPT citation behavior on PubMed Central.
Those figures clarify the supply chain. Retrieval is conditional. Source selection is competitive. Citation is a downstream outcome of ranking, extraction, and synthesis, not a guaranteed reward for publishing a relevant page. For brands, the implication is sharp. Being accurate is necessary, but retrievable structure, corroboration, and passage-level clarity often determine whether the model uses your information at all.
A short explainer helps frame the mechanism in motion.
Traditional search returns options while AI search composes an answer
The operational difference between Google and ChatGPT with RAG shows up in what the system is optimizing for. Search engines rank documents. RAG systems assemble a response from fragments that survive retrieval, filtering, and synthesis.
Attribute | Traditional Search (Google) | AI Search (ChatGPT with RAG) |
|---|---|---|
Primary output | Ranked links | Synthesized answer |
User task | Choose a result | Evaluate a completed response |
Source visibility | Explicit and front-loaded | Often compressed into citations or supporting references |
Content unit | Whole pages | Extracted passages, facts, and claims |
Winning condition | Ranking position | Inclusion in the generated answer |
Failure mode | Low click-through | Omission, paraphrase drift, or citation loss |
That change in output changes the visibility strategy. A page can rank well and still contribute nothing to the final answer if its claims are diffuse, unsupported, or hard to extract cleanly. A less prominent source can outperform it if the wording is precise, the entity signals are stable, and the evidence is easy for the model to merge with other sources.
Algomizer's analysis of how GEO works in practice examines this shift from page competition to evidence competition in more detail.
For teams building AI visibility programs, a complimentary assessment is available through Algomizer.
Our Framework Engineering Trust with Evidence Clusters
The retrieval layer rewards corroboration. That is why single-asset SEO thinking collapses in AI search. One strong page can rank. It often cannot manufacture consensus.
Evidence Clusters turn scattered mentions into machine-legible consensus
Algomizer's framework for this problem is Evidence Clusters. The model is simple. A brand distributes factually consistent, topically aligned information across multiple surfaces that LLMs and retrieval systems are likely to encounter.
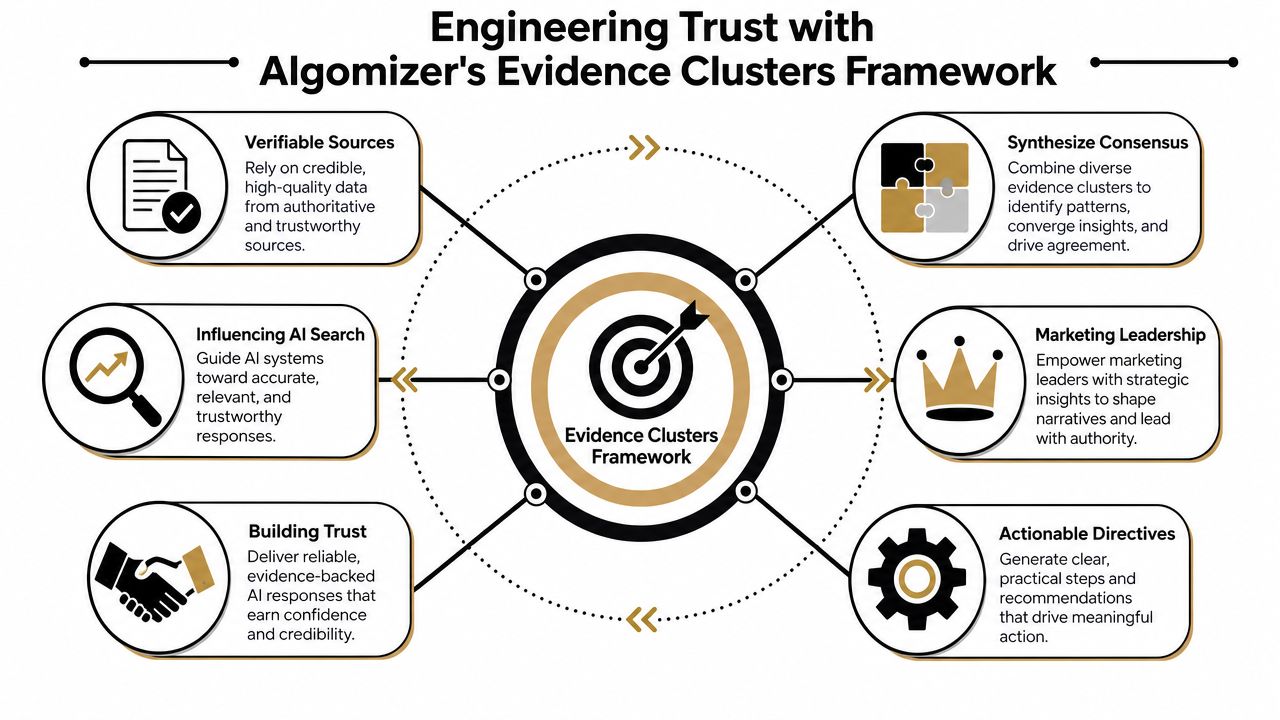
The cluster is controlled corroboration. A company website may define the offering. A product knowledge base may clarify terms. Partner content may validate integrations. Earned media may reinforce market framing. Neutral profiles may stabilize entity recognition. The model then encounters the same core narrative through independent-seeming paths.
This is the logical response to selective retrieval. If a system assembles answers from fragments, the brand must ensure the fragments agree.
A brand no longer wins by publishing the loudest page. It wins by making the safest answer easy to assemble.
For readers who want the underlying technical doctrine, Algomizer details it in Engineering Truth the technical framework for GEO.
Semantic Density determines whether a claim survives retrieval
Evidence Clusters work because they increase what this paper calls Semantic Density. That is the concentration of mutually reinforcing meaning around an entity, claim, or category position.
High Semantic Density has visible traits:
Entity consistency: The company name, product names, and category labels appear in the same form across assets.
Claim discipline: The same core assertions recur without contradiction.
Context breadth: The brand is described in multiple contexts, not only on a homepage.
Machine legibility: Definitions, FAQs, comparison pages, and knowledge-base entries reduce ambiguity.
Low Semantic Density looks familiar. A company says one thing in paid media, another in PR, and a third in product documentation. Human readers may tolerate that. LLMs interpret it as unstable evidence.
That is why brands must move from page optimization to evidence engineering. The task is no longer “rank this URL.” The task is “shape the source environment the model trusts.”
Teams that want operational help can use services that monitor prompts, surface citation patterns, and map source gaps. One option is Algomizer, which focuses on AI search visibility across systems such as ChatGPT, Claude, Gemini, and Perplexity.
Tactical Implications for Generative Engine Optimization
The strategic conclusion is clear. The execution model has to change inside content, PR, technical SEO, and measurement.
The operating model has to change
Many organizations still separate publishing, media relations, and technical implementation. Generative Engine Optimization doesn't permit that split. The model sees the final evidence field, not the org chart.
A practical GEO program starts by replacing traffic-first thinking with citation-first thinking. The question shifts from “Which keyword should this page target?” to “Which claim should the model be able to verify about this company?”
That shift affects four workstreams.
The practical playbook is cross-functional
Workstream | Old SEO instinct | GEO directive |
|---|---|---|
Content strategy | Publish many keyword pages | Build durable source-of-truth assets |
Digital PR | Chase mentions | Secure corroborating narratives |
Technical implementation | Improve crawl signals | Improve machine readability and entity clarity |
Measurement | Track rankings and clicks | Track mentions, citations, and answer accuracy |
The checklist below translates that into action.
Create source-of-truth pages: Publish canonical explanations for products, categories, use cases, pricing logic, and differentiators. These pages should answer direct questions in language that can survive quotation or paraphrase.
Standardize message architecture: PR teams, content teams, product marketers, and sales enablement teams should use the same entity names and category framing.
Structure information for machines: Use schema, clean heading hierarchy, concise tables, FAQs, and internal linking that clarifies relationships among concepts. Teams exploring this discipline further can review what generative engine optimization is.
Reduce ambiguity across the web: Update company descriptions on partner pages, software directories, executive bios, newsroom materials, and documentation hubs so the same core facts appear everywhere they should.
Measure answer quality directly: Prompt ChatGPT, Claude, Gemini, and Perplexity with category questions. Record whether the brand appears, how it is described, and which sources the system cites.
Field note: In AI search, accuracy is a visibility metric. If the model mentions a brand but describes it incorrectly, the evidence layer is still weak.
This is also where tooling matters. Some teams build internal prompt testing workflows. Others use managed platforms to monitor visibility and citation behavior. The important point is methodological: measurement has to happen inside generated answers, not only inside web analytics.
For a category-specific assessment, marketing leaders can book a complimentary review with Algomizer.
Conclusion From Information Retrieval to Reality Synthesis
Where does ChatGPT get its information from? From a supply chain that begins with pre-training, gets shaped by post-training, and may extend into retrieval when the system decides fresh evidence is needed.
The decisive question is how the model decides what is safe to say
That is the strategic frame. The model synthesizes a response from patterns and evidence that appear coherent enough to use. In other words, it constructs a version of reality that feels supported.
For brands, that changes the job. Search visibility used to mean winning a list position. AI visibility means becoming part of the evidence the model trusts when it composes the answer itself.
That is why isolated SEO tactics keep missing the point. The winning brand does this: it aligns the public record. It creates source-of-truth pages, reinforces them across external domains, reduces ambiguity, and makes its category narrative easy for retrieval systems to verify.
The next decade of discovery belongs to companies that understand this shift early. The question is no longer only where does ChatGPT get its information from. The question is whether the model finds enough consistent evidence to include a brand when it constructs the answer a buyer sees.
Brands that want to improve visibility inside ChatGPT, Claude, Gemini, Perplexity, and other AI systems can book a call with Algomizer to review their current evidence footprint, citation exposure, and generative search opportunities.