ChatGPT Rank Tracker: Why "Rank" Is the Wrong Metric
Ditch outdated methods. Our guide to the modern ChatGPT rank tracker explains why 'rank' is misleading and reveals the metrics that truly measure AI visibility.

An Algomizer Research Paper: The Measurement Crisis
May 2026
Executive summary. The market for the chatgpt rank tracker exists for a valid reason, but the label itself is wrong. As Rankability's analysis of ChatGPT rank tracking notes, vendors emerged quickly as ChatGPT usage became commercially significant, with ChatGPT processing “over a billion searches a week.” That demand created a tooling layer for monitoring brand mentions, source citations, and placement inside answers. The error is conceptual, not commercial. Marketing leaders borrowed the word “rank” from SEO and applied it to a system that doesn't produce stable rankings.
That mismatch now creates reporting noise at the executive level. A CMO asks where the brand ranks. The dashboard returns a pseudo-position. The model, meanwhile, is generating a probabilistic answer that may cite different brands, different sources, and different evidence on another run.
The correct question isn't “Where do we rank?” It's “How often does the model treat this brand as credible enough to surface?” That is a measurement problem, a retrieval problem, and a content-structure problem.
This paper argues that AI visibility must be measured as citation frequency and semantic influence. That shift changes tooling, reporting, and strategy. It also changes how teams should think about GEO. For foundational context on that discipline, see this explainer on generative engine optimization.
Table of Contents
Introduction The End of Rank Tracking as We Know It
The category exists. The metric needs to change
Why LLM Visibility Defies Traditional SEO Metrics
ChatGPT doesn't produce a stable results page
Visibility is the usable metric
Testing discipline matters more than keyword discipline
The Algomizer Framework Evidence Clusters and Semantic Density
Semantic Density measures narrative concentration
Evidence Clusters give models defensible material to cite
The framework changes optimization priorities
Deconstructing Modern Tracking Methodologies
Two citation systems require two measurement lenses
Single snapshots distort reality
Industrial collection beats lightweight polling
A Comparative Analysis DIY Tooling vs Managed Service
Tool pricing proves the category is now operational
The primary difference lies in interpretation capacity
The Enterprise Playbook for AI Visibility Measurement
Stage 1 starts with prompt economics
Stage 2 and Stage 3 turn brand claims into retrievable evidence
Stage 4 keeps the program honest
Conclusion From Tracking Ranks to Engineering Truth
Introduction The End of Rank Tracking as We Know It
The market adopted the phrase chatgpt rank tracker before it defined the object being measured. That shortcut made commercial sense. It made analytical sense only if LLMs behaved like search results, and they do not.
A ranked list assumes fixed inventory, visible ordering, and repeatable placement. A generated answer has none of those properties. The output is assembled at response time, shaped by prompt wording, retrieval conditions, model policy, and compression choices inside the answer itself. Treating that system like a SERP creates a measurement error at the start of the workflow.
The practical mistake is subtle. Teams ask, "Where do we rank in ChatGPT?" The more useful question is, "How often does the model pull our brand into the answer, and what source material makes that inclusion defensible?" That shift moves the program away from vanity snapshots and toward evidence quality, citation frequency, and semantic influence across prompt sets.
This is the operating logic behind generative engine optimization. The goal is to increase the probability that the model treats your brand, your claims, and your supporting documents as valid material for synthesis.
The category exists. The metric needs to change
Vendors were right to build monitoring products around AI answers. Buyers need observability. But "rank tracking" imports assumptions from classic SEO that break under probabilistic generation.
For a CMO, that distinction affects budget, reporting, and attribution. A dashboard that logs one observed answer can look precise while hiding the underlying question, which is whether the brand appears consistently across prompt variants, sessions, and models. An analyst would not call one generation a trend. A brand team should not call it visibility.
A better framework starts with two measurements. First, citation frequency. How often does the model reference your sources or source class across relevant prompts? Second, semantic influence. How often do your core claims shape the answer even when your brand name is absent? Brands that win in AI often control both layers. Brands that chase position usually control neither.
That is why adjacent disciplines matter. The retrieval and evaluation discipline described in AI driven testing strategies for startups applies here as well. If you cannot test response variance at scale, you cannot separate a durable visibility pattern from a lucky output.
Core principle: In LLM systems, a single observed mention is an anecdote. Repeated citation across prompt variation is a signal.
The rest of this article treats visibility as a probabilistic measurement problem, not a ranking problem with new branding. That change sounds semantic only until reporting starts to improve.
Why LLM Visibility Defies Traditional SEO Metrics
The old SEO frame fails because ChatGPT doesn't return a fixed ordered list. Ahrefs' research on ranking in ChatGPT states that ChatGPT has no traditional rankings, its responses are probabilistic, and a reliable “#1” position isn't achievable. The meaningful metric is visibility, defined as the percentage of relevant prompts where a brand is mentioned or cited.

ChatGPT doesn't produce a stable results page
A search engine results page is index-first and layout-constrained. An LLM answer is synthesis-first and response-variable. That distinction changes the unit of analysis from “position of URL” to “frequency of inclusion in the generated answer.”
That also explains why many brands with strong SEO footprints still fail to appear in AI outputs. Traditional authority signals can help, but they don't guarantee extraction, citation, or mention. The model isn't just finding pages. It's assembling a plausible answer from what it can retrieve, compress, and defend.
A practical implication follows. If a team runs one prompt once and logs a position, the team hasn't measured visibility. It has documented a single generation.
Visibility is the usable metric
Visibility works because it matches the architecture. It asks how often a brand is surfaced across a representative prompt set over time. That can be observed, trended, and compared.
A stronger evaluation layer usually includes:
Brand mention frequency: How often the model names the brand in relevant answers.
Citation footprint: Which URLs or domains appear as supporting evidence when the answer is grounded.
Answer placement: Whether the brand appears centrally in the answer or at the edge of the response.
Competitive co-occurrence: Which competing entities repeatedly appear in the same answer environment.
The winning brand in AI search is the one the model keeps retrieving into truth-shaped answers.
Adjacent testing disciplines offer significant value in this context. Teams building AI driven testing strategies for startups already understand that probabilistic systems require repeated runs, controlled prompts, and output comparison. AI visibility measurement needs that same rigor.
Testing discipline matters more than keyword discipline
Marketers trained on keyword tooling often assume that prompt tracking is just keyword tracking with a different interface. It isn't. Prompt phrasing changes entity recall, source selection, and answer composition more dramatically than a conventional SERP query shift.
That is why “rank” creates bad executive shorthand. It turns a probabilistic system into a deterministic report. Visibility, by contrast, keeps the analyst honest. It acknowledges variance and measures the thing that matters: repeatable inclusion.
For more on the foundational logic behind this shift, refer back to Chapter 1. Ready to measure what matters? Book a complimentary visibility assessment with the team at Algomizer contact.
The Algomizer Framework Evidence Clusters and Semantic Density
Once static rank is removed from the model, a new framework is required. The useful lens is not where a page sits, but how strongly a brand's verifiable narrative occupies the answer space. That is the basis of Semantic Density and Evidence Clusters.
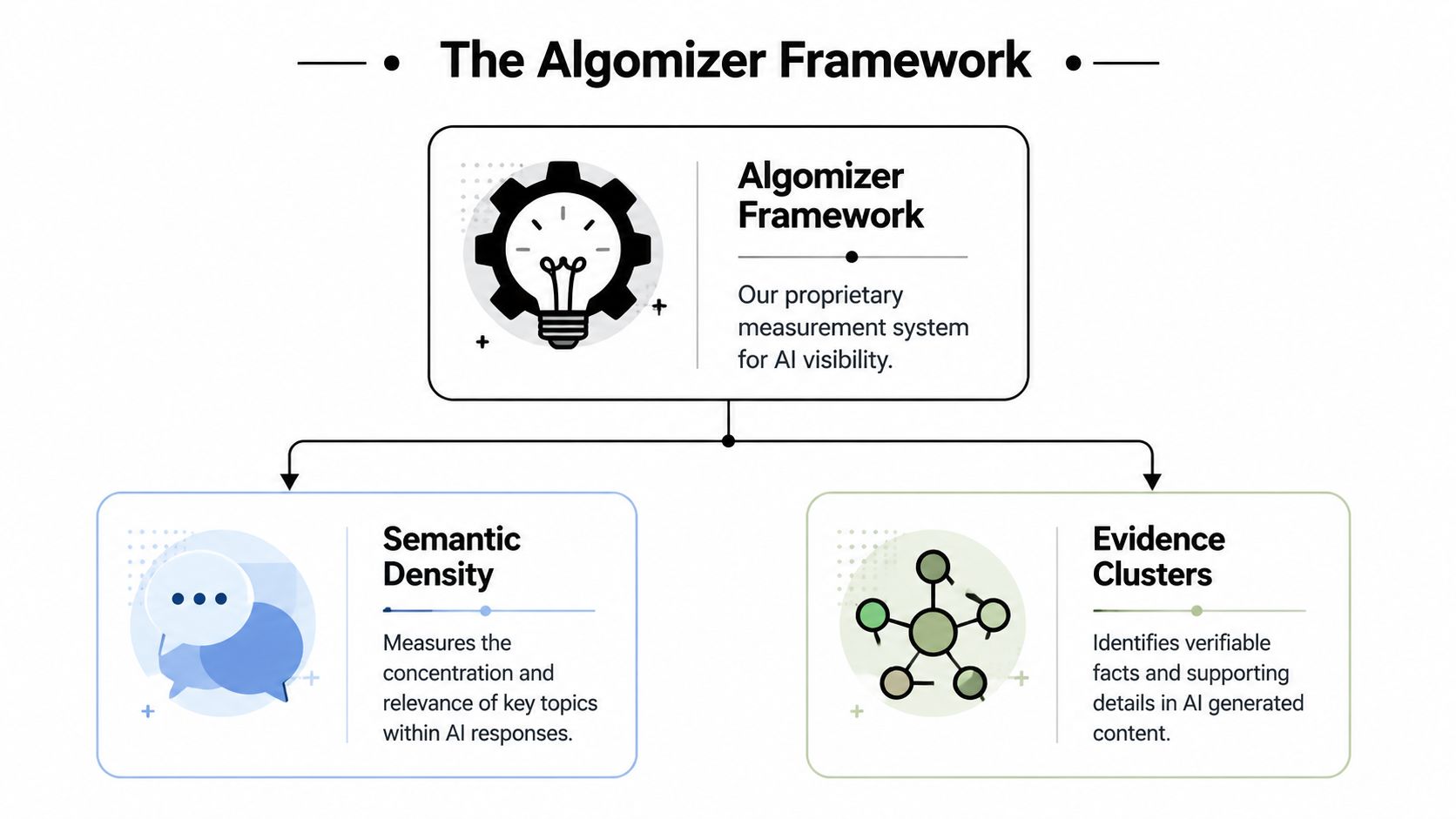
Semantic Density measures narrative concentration
Semantic Density measures how concentrated, consistent, and retrievable a brand's core claims are across the knowledge environment an LLM can access. Thin coverage creates weak recall. Contradictory coverage creates unstable recall. Dense, aligned coverage improves the odds that the model can assemble a coherent answer around the brand without semantic friction.
This is not keyword stuffing with a new label. It is narrative engineering. A dense semantic profile contains clear category positioning, repeated attribute associations, and consistent framing across owned and third-party surfaces.
An effective external companion to this analysis is the selection of top-rated LLM visibility tools, because the category increasingly reflects the need to measure entity presence rather than classic ranking outputs.
Evidence Clusters give models defensible material to cite
Evidence Clusters are structured groups of facts, references, and corroborating statements that make a claim easier for an LLM to retrieve and synthesize. Brands lose visibility when their narrative exists as scattered marketing copy. They gain visibility when claims are published in forms the model can reconcile.
An effective cluster tends to include:
Clear entity definition: What the company is, in plain language, without category ambiguity.
Claim support: Verifiable statements that can be corroborated by source material or structured references.
Topical adjacency: Supporting content around the same subject area so the model sees the claim in context.
Source compatibility: Formats that are easy for retrieval systems and summarization layers to extract.
Operational rule: LLMs don't reward the loudest claim. They reward the claim they can reconstruct with the least uncertainty.
The technical logic behind this approach is developed further in this framework on engineering truth for GEO.
The framework changes optimization priorities
Under a rank-first model, teams ask which keyword to target. Under an evidence-first model, teams ask which claims the model can safely repeat. That leads to different work. More source harmonization. More structured explanation. Less fixation on isolated rankings.
The consequence is strategic. AI visibility is not won by forcing a page upward in a list. It is won by making the brand the most retrievable and supportable answer candidate in its category.
For more on the foundational logic behind this shift, refer back to Chapter 1. Ready to measure what matters? Book a complimentary visibility assessment with the team at Algomizer contact.
Deconstructing Modern Tracking Methodologies
Measurement quality depends on collection quality. Dageno AI's analysis of ChatGPT search rank tracking software identifies two citation mechanisms that serious tracking must separate: parametric knowledge from training data and real-time retrieval via Bing. The same analysis argues that single snapshots are statistically invalid, and that reliable tracking requires high-frequency prompt aggregation.
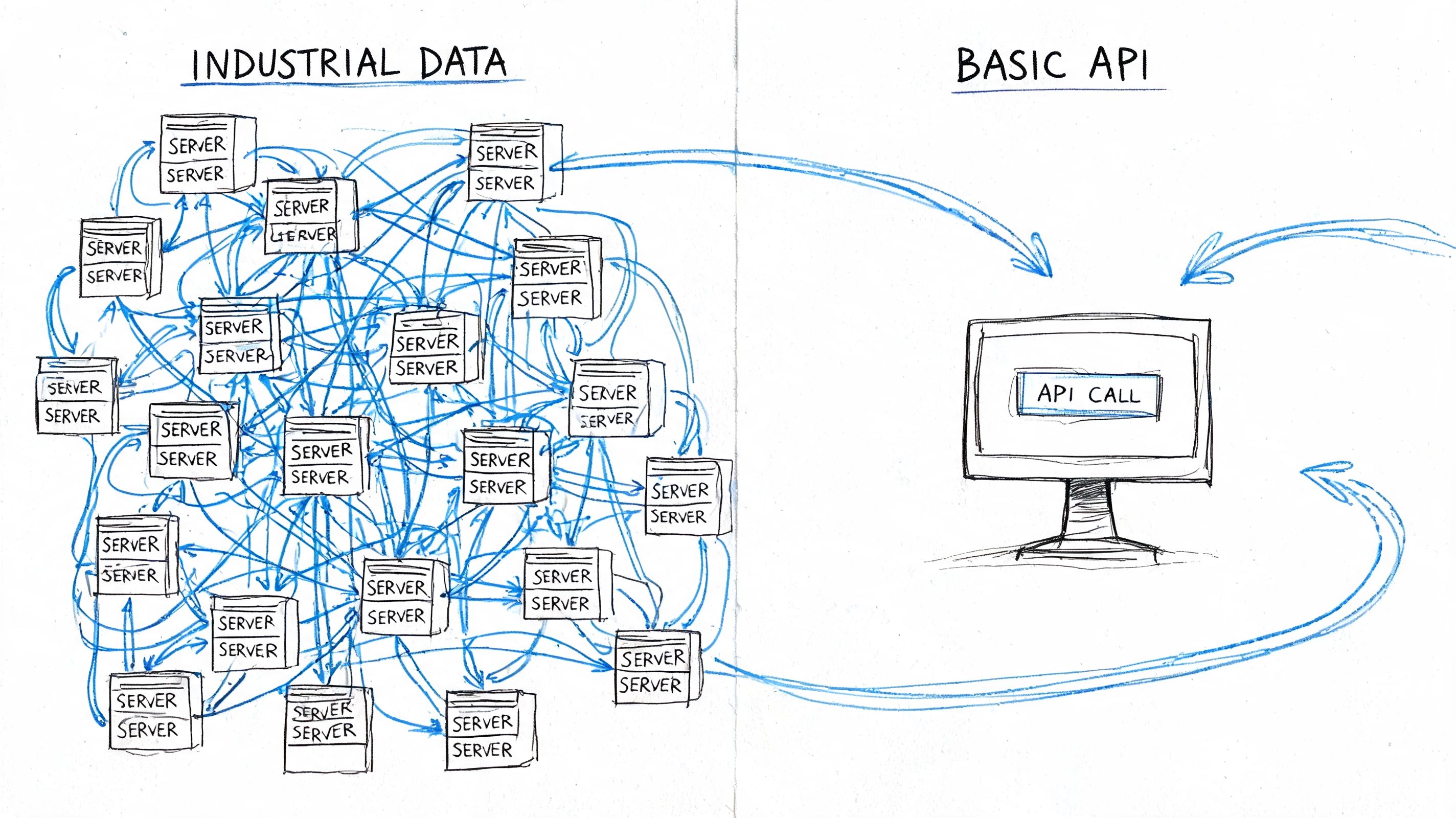
Two citation systems require two measurement lenses
Parametric knowledge and live retrieval behave differently. Parametric knowledge reflects what the model has internalized as stable brand context. Retrieval reflects what the model can pull from the current web environment when grounding an answer.
That distinction explains a recurring executive complaint. A page can perform well in Google and still remain absent from ChatGPT. The issue is often not discoverability in the classical search sense. The issue is compatibility with how the model interprets, extracts, and trusts information.
Single snapshots distort reality
One-run checks are easy to sell because they produce a clean screenshot. They are poor measurement instruments because they flatten variance into certainty.
Reliable methodology requires a prompt library that spans buyer intent, repeated execution on a schedule, and response capture at the answer level. Teams exploring tactical tools to check how pages rank in chatgpt often discover this limitation quickly. A one-off checker can reveal whether something happened once. It cannot establish whether the pattern is durable.
A disciplined workflow usually records:
The prompt and its intent class.
The full model response.
Any cited domains or URLs.
Competitor entities present in the answer.
Repeated runs over time to compare answer variability.
Good AI measurement treats each response as a sample, not a verdict.
Industrial collection beats lightweight polling
The strongest programs use browser-based observation rather than relying purely on narrow API abstractions. Headless browsers capture what an actual user would see, including citations, formatting, and answer composition. That matters because answer presentation is part of influence, not just a cosmetic layer.
This is also where service architecture starts to matter more than software branding. Some firms use a stack of standalone tools. One option in that market is Algomizer, which tracks visibility across major LLMs using headless-browser measurement and independently verifiable reporting. The key point is methodological, not promotional. If the collection layer cannot distinguish retrieval from parametric recall, the reporting layer will mislead.
Further enterprise implications are covered in this guide to agency rank tracking for enterprise companies.
For more on the foundational logic behind this shift, refer back to Chapter 1. Ready to measure what matters? Book a complimentary visibility assessment with the team at Algomizer contact.
A Comparative Analysis DIY Tooling vs Managed Service
Price is the easy part. Measurement error is the true cost.
SE Ranking's guide for 2026 on ChatGPT rank tracking tools shows that the software market now spans low-cost trackers, mid-tier visibility products, and add-on AI monitoring modules. That matters because it confirms category demand. It does not prove that "rank tracking" is a stable measurement model for LLMs.
A CMO should read this market in two layers. The first layer is procurement. You can buy a dashboard. The second layer is inference. You still need to decide whether repeated appearances reflect durable influence, temporary retrieval behavior, or prompt-specific variance. In probabilistic systems, those are different phenomena.
Tool pricing proves the category is now operational
Software pricing signals operational maturity, not analytical sufficiency. The visible expense sits in subscriptions. The hidden expense sits in query set design, repeated sampling, answer review, citation normalization, and competitive interpretation.
That distinction changes the buy-versus-build decision. Traditional SEO teams often assume the tracker is the system. In AI visibility work, the tracker is only the collection layer. The system includes a measurement philosophy, a sampling protocol, and a way to separate noise from actual movement.
The primary difference lies in interpretation capacity
DIY can work for teams with research discipline, statistical caution, and enough time to maintain prompt libraries as models shift. Enterprise marketing teams often underestimate that workload because they import assumptions from deterministic rank reporting. LLM outputs are conditional and variable. A single observed answer is weak evidence. A pattern across many prompts, runs, and citation environments is stronger evidence.
That is why the practical comparison is less about software features and more about who owns methodological risk.
Factor | DIY Tooling Approach | Algomizer Managed Service |
|---|---|---|
Core input | Buy standalone trackers and build the workflow internally | Outsource collection, interpretation, and calibration to a managed partner |
Known software cost | Subscription costs vary by vendor and feature set, as noted earlier | Bundled into service scope rather than split across multiple tools |
Measurement model | Often defaults to position-style reporting, even when outputs are probabilistic | Built around repeated sampling, citation frequency, and semantic influence |
Prompt governance | Internal team defines prompt sets, updates them, and checks for bias | Managed as part of the service workflow |
Data quality risk | Higher if sampling is thin or analysts treat single outputs as trend data | Lower when methodology is standardized and reviewed continuously |
Speed to interpretation | Slower when collection, QA, and analysis live in separate tools | Faster when collection and analysis sit in one reporting loop |
Model-shift response | Internal team absorbs recalibration work after interface or behavior changes | Provider updates the method as part of ongoing execution |
Executive reporting | Team must convert volatile outputs into a defensible narrative | Reporting is framed around share of citation, answer inclusion, and competitive influence |
A low-cost tracker can become an expensive internal research project if the team treats probabilistic outputs like fixed rankings.
This does not make DIY a bad choice. It makes the tradeoff clearer. If a company already has an in-house research function that can validate prompts, review outputs at scale, and interpret citation patterns, software may be enough. For brands without that capability, a managed service reduces analytical drift and produces a measurement system that better matches how LLMs generate answers.
For more on the foundational logic behind this shift, refer back to Chapter 1. Ready to measure what matters? Book a complimentary visibility assessment with the team at Algomizer contact.
The Enterprise Playbook for AI Visibility Measurement
Enterprise AI visibility programs fail when they begin with tooling instead of measurement design. The stronger sequence starts with prompts, moves into evidence engineering, then builds a repeatable monitoring cadence. That creates a system executives can trust.
Stage 1 starts with prompt economics
The first task is selecting prompts that matter to revenue, category perception, and shortlist formation. Generic prompts create vanity visibility. Commercial prompts reveal influence.
A useful benchmark set includes a mix of branded, comparative, category, and problem-oriented prompts. The goal is not volume for its own sake. The goal is representativeness across decision contexts.
Stage 2 and Stage 3 turn brand claims into retrievable evidence
Discovery alone doesn't change outcomes. Teams then need to convert weak brand messaging into evidence the model can work with. That usually means cleaning category language, reducing claim ambiguity, and publishing support in formats that retrieval systems can parse.
The deployment layer then focuses on discoverability and structural clarity. Pages, entity descriptions, and corroborating sources need to align semantically. If they don't, the model sees fragments instead of a stable narrative.
A practical enterprise sequence often looks like this:
Map answer-critical prompts: Prioritize prompts tied to buying decisions, vendor comparisons, and category trust.
Audit source reality: Identify which domains and narrative patterns repeatedly shape AI answers in the category.
Build evidence assets: Publish concise, supportable explanations rather than diffuse campaign language.
Align external references: Reduce mismatch between how the brand describes itself and how the wider web describes it.
Enterprise teams shouldn't ask whether they have content. They should ask whether the model can reconstruct a credible answer from that content.
Stage 4 keeps the program honest
The final stage is calibration. Tracking has to be continuous because model behavior changes, citation patterns change, and new competitors enter the answer set.
Mature teams differ from reactive teams in this regard. Reactive teams celebrate isolated appearances. Mature teams study whether visibility persists across time, prompt classes, and answer contexts. They treat AI visibility as an operating system for market perception, not a campaign report.
For more on the foundational logic behind this shift, refer back to Chapter 1. Ready to measure what matters? Book a complimentary visibility assessment with the team at Algomizer contact.
Conclusion From Tracking Ranks to Engineering Truth
The term chatgpt rank tracker will remain useful as market shorthand, but it describes the wrong object. ChatGPT does not offer a stable ranking environment, so position-based reporting creates confidence without validity. The right unit of analysis is visibility, reinforced by citation patterns, evidence quality, and answer-level consistency.
That reframing changes strategy. Brands should stop trying to “win rank” inside a probabilistic system and start building the kind of structured, supportable presence that an LLM can repeatedly surface. The durable advantage is not louder content. It is defensible presence.
For CMOs, the mandate is straightforward. Replace pseudo-rank reporting with a measurement system that reflects how language models generate answers. Ask not where the brand appears once, but how often it becomes part of the model's answer logic.
For more on the foundational logic behind this shift, refer back to Chapter 1. Ready to measure what matters? Book a complimentary visibility assessment with the team at Algomizer contact.
Brands that want a practical way to measure AI visibility can start with Algomizer. The company helps marketing teams analyze how they appear across major LLMs, identify citation gaps, and structure content for stronger retrieval and answer inclusion.