Generative Engine Optimization Services: Unlock AI Search
Explore generative engine optimization services. Learn GEO vs. SEO, components, measurement & vendor selection for AI search visibility.

Subtitle: An Algomizer Research Paper on AI-first visibility engineering
May, 2026
Traditional SEO advice is now the wrong default for brand discovery. The commercial battlefield has shifted from blue-link rankings to inclusion inside synthesized answers, cited summaries, and model-generated recommendations.
That shift isn't theoretical. A 2026 market forecast projects the global Generative Engine Optimization market at USD 1,089.3 million in 2026, growing at a 40.6% CAGR to USD 17,148.6 million by 2034, with North America holding about 38.4% share in 2026 and the U.S. projected at USD 365.4 million in 2026 and USD 6,359.6 million by 2034 according to Dimension Market Research's GEO market forecast. That is a new budget category, not a renamed SEO retainer.
Most public guidance still tells teams to add schema, tighten headings, and preserve existing SEO workflows. That advice misses the architectural change. Generative engines don't reward pages merely because they rank. They reward sources that are easy to parse, easy to trust, and easy to cite.
The decisive question is no longer “Where does this page rank?” It is “When ChatGPT, Perplexity, Gemini, or Google AI Overviews answers the query directly, does the model rely on this brand as evidence?”
Table of Contents
The Inevitable Shift to Generative Engine Optimization
Executive summary rejects the legacy playbook
A new budget category has already formed
How Generative Engines Find and Rank Information
Machine interpretability beats page authority
Retrieval changes the unit of competition
A Comparative Analysis GEO Versus SEO
Clicks collapse when answers absorb demand
GEO and SEO optimize different objects
The Algomizer Framework Evidence Clusters And Semantic Density
Evidence Clusters make claims citable
Semantic Density determines extractable value
Anatomy Of A GEO Services Engagement
A real engagement follows four operating phases
Continuous calibration is part of the service
Measuring GEO Success And The Outcomes Based Model
Cross-model measurement is the market failure
An outcomes model fixes incentive misalignment
Vendor Evaluation Criteria And Your Next Steps
Enterprise buyers need auditable criteria
The next move is controlled visibility testing
The Inevitable Shift to Generative Engine Optimization
Executive summary rejects the legacy playbook
The market is already treating answer engines as a primary distribution channel. Buyers increasingly get product comparisons, vendor shortlists, and implementation guidance from AI interfaces before they visit a site. That behavior changes the economics of visibility. The contest is no longer limited to who ranks. It includes who gets extracted, cited, and repeated inside generated answers.
The old search model rewarded pages that accumulated authority and captured clicks. Generative retrieval changes the unit of value. A brand can lose the visit and still shape the decision, or lose both if its claims are absent from the model's evidence pool. That is why generative engine optimization services should be treated as a separate operating function, not as a renamed SEO package.
A new budget category has already formed
Procurement behavior reflects that shift. CMOs and growth leaders are starting to fund AI visibility work as its own line item because the reporting question has changed. The issue is no longer just rank, traffic, and conversion by page. The issue is whether the company appears in model outputs for commercial prompts that influence pipeline.
That distinction separates professional GEO services from repurposed SEO tactics. Traditional SEO improves the probability of discovery in legacy search interfaces. GEO improves the probability that a model can extract and reuse the right claims under the right query conditions. Those are different optimization targets, different workflows, and different measurement systems.
A serious program does not stop at metadata, page templates, or backlink acquisition. It audits whether a brand's core claims are packaged as Evidence Clusters, whether those claims have enough Semantic Density to survive summarization, and whether they appear consistently across high-intent prompts and model environments. Our research on the weight of authority in GEO shows why authority still matters, but in a narrower and more conditional form than SEO teams assume.
The practical rule is simple. If a buyer gets a complete answer without clicking, value shifts from rank position to source inclusion.
That shift has commercial consequences. Teams that still optimize for sessions alone will undercount influence, misread declining clickthrough as a content problem, and miss the channel where category preference is now formed. Teams that adopt an outcomes-based GEO model can measure the right object instead: share of presence inside generated answers, citation frequency, message accuracy, and downstream revenue impact.
Algomizer offers visibility assessments for teams that need a factual baseline before committing budget.
How Generative Engines Find and Rank Information
Machine interpretability beats page authority
Generative engines prioritize content they can interpret cleanly. The winning source is often the one that is easiest to extract and trust, not the one with the strongest traditional ranking profile.
That principle sits at the core of modern GEO. According to Optimizely's definition of generative engine optimization, AI overviews and chatbot answers synthesize from sources that are easiest to interpret and trust, rather than necessarily choosing the highest-ranking pages in traditional search results. This is the operational meaning of source extractability.
Most executives still think of search as a crawl-and-rank system. Generative retrieval works differently. A model answers by pulling from already processed material, selecting relevant passages, and assembling them into a response that appears native to the interface.
That changes what “optimized” means.
Self-contained passages matter: A section must answer a question without depending on surrounding filler.
Entity relationships matter: Products, categories, use cases, and claims must be tied together explicitly.
Structural signals matter: Schema and technical markers help systems parse what a passage is, who it refers to, and why it can be trusted.
Retrieval changes the unit of competition
In classic SEO, the web page is the unit of competition. In generative retrieval, the competitive unit is often the chunk, claim set, or citation-ready paragraph.
That is why vague long-form content underperforms. It may read well for humans and still fail for retrieval because the facts are buried, the relationships are implicit, and the answer is spread across too many paragraphs.
A model can't cite what it can't isolate.
A modern GEO workflow therefore starts with decomposition. Teams break a topic into retrievable statements, connect each statement to a clear entity, and reduce ambiguity so the engine can lift the content into a synthetic answer with minimal transformation.
The practical implication is severe. Editorial quality alone won't secure citations. Technical and semantic formatting become part of the commercial stack. Retrieval is not reading in the human sense. Retrieval is selection under machine constraints.
A useful companion analysis of this shift appears in this explanation of authority in GEO, which frames authority as a machine-readable property rather than a purely link-derived one.
For CMOs, the operational takeaway is simple. Generative engine optimization services aren't content refresh packages. They are retrieval engineering services for public knowledge surfaces.
Book a call with Algomizer for a visibility assessment.
A Comparative Analysis GEO Versus SEO
Clicks collapse when answers absorb demand
When AI answers appear, informational click behavior drops sharply. That makes citation visibility a revenue-defense issue, not a speculative channel test.
The business case is already visible in user behavior. In a statistics roundup published by Wellows, click-through rates for informational queries fell from 1.41% to 0.64% when AI-generated answers appeared, a drop of more than 54%, and zero-click searches reached nearly 60% of Google searches in the U.S. and EU during 2024 according to the Wellows GEO statistics roundup.
The same source reports that 31% of Gen Z users use answer engines or chatbots alongside traditional search, 67% of digital marketers say GEO tracking is important to their strategy, Perplexity processes 780 million searches per month, and ChatGPT crossed 900 million weekly active users by early 2026. Those are no longer fringe interfaces.
GEO and SEO optimize different objects
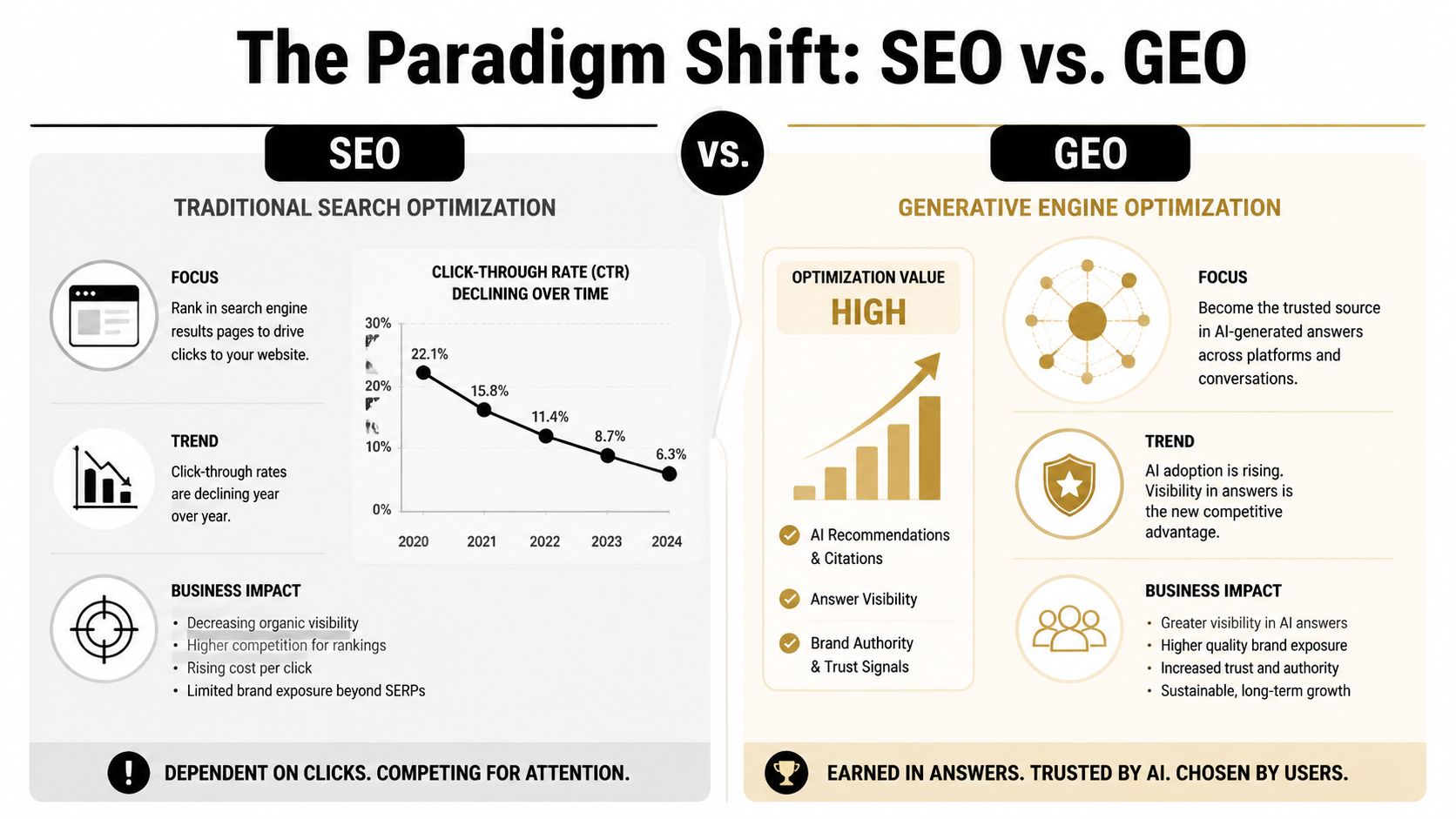
Treating GEO as repackaged SEO causes strategic errors. The systems pursue different outputs, measure different units, and require different service design.
Dimension | Traditional SEO | Generative Engine Optimization (GEO) |
|---|---|---|
Primary goal | Ranking in result pages | Citation and inclusion inside generated answers |
Unit of optimization | Web page | Content chunk, claim, entity relationship |
Main success event | Click | Mention, citation, recommendation, answer presence |
Core tactic set | Keyword targeting, internal links, backlinks | Evidence Clusters, extractable statements, machine-readable structure |
Reporting logic | Rankings, sessions, traffic | Citation frequency, share of voice, brand mentions, sentiment |
Failure mode | Lower rank | Omission from synthesized answers |
This difference is visible even in adjacent tooling. Legal and research teams experimenting with AI-assisted discovery often find that a purpose-built system such as new AI tool Leges GPT is useful because the interface is optimized around retrieval and synthesis, not around a list of links. GEO operates in that same answer-centric environment.
A brand that funds only SEO is still buying exposure in a list-based system while users migrate toward answer-based interfaces. That spend can still work. It just won't protect the brand where decision journeys now begin.
Key implication: SEO competes for the click. GEO competes for the answer itself.
Generative engine optimization services matter because they formalize that distinction. The service is not a vocabulary shift. It is a change in optimization object, channel mechanics, and measurement model.
Book a call with Algomizer for a visibility assessment.
The Algomizer Framework Evidence Clusters And Semantic Density
Evidence Clusters make claims citable
Generic AI-optimized content fails because it blends into the model's prior knowledge. Winning content gives the model something worth citing.
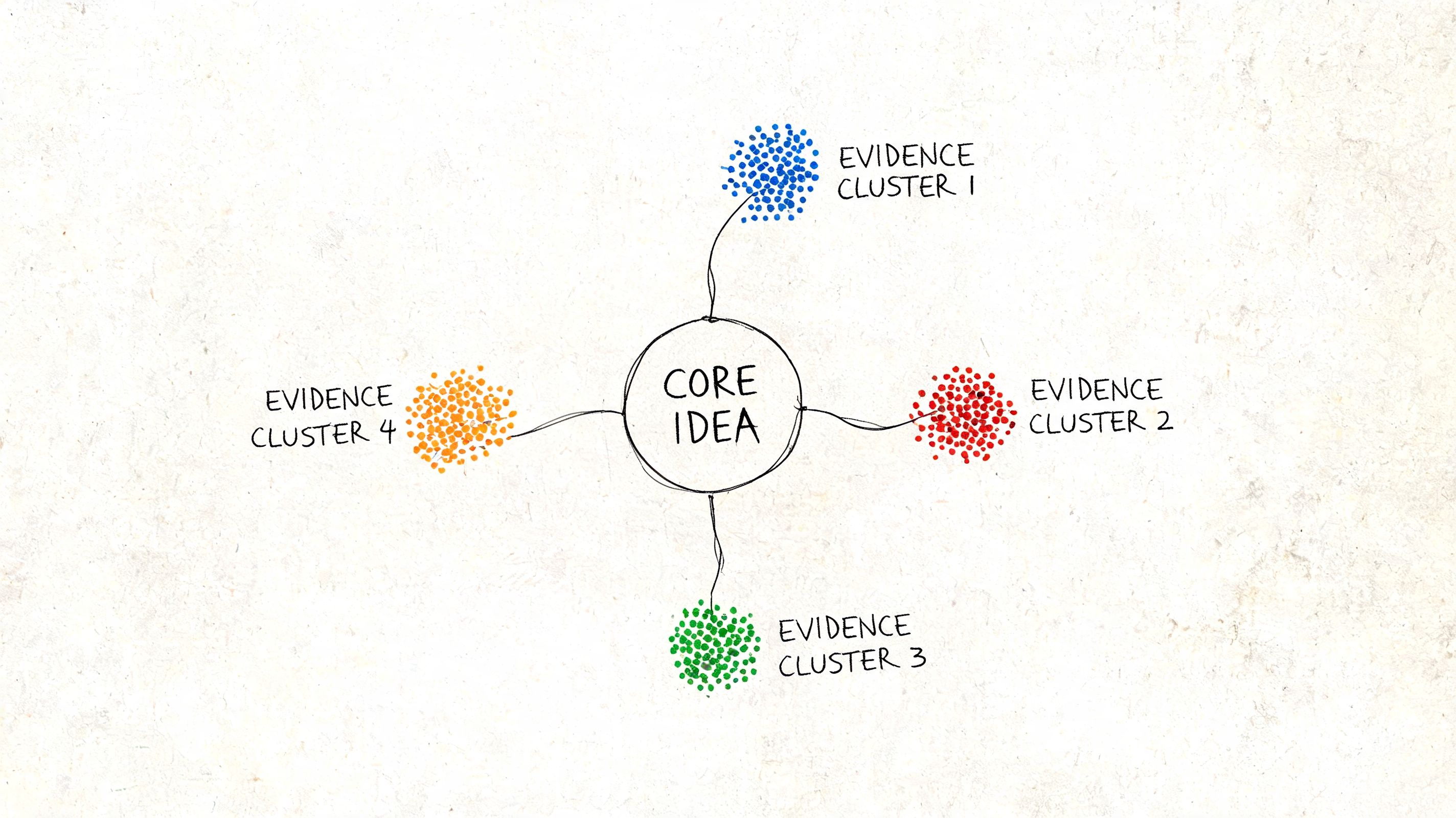
That is the logic behind Evidence Clusters. An Evidence Cluster is a set of tightly connected, verifiable statements arranged so a model can extract a claim, understand its scope, and preserve attribution with minimal loss. It is not decorative formatting. It is evidence architecture.
The underlying principle is supported by LSEO's discussion of information gain in GEO. In the AI era, the goal is to complement existing knowledge. Generative systems cite sources that provide information gain, and inclusion is highly competitive because models may cite only a small number of sources.
A strong Evidence Cluster usually contains several elements working together:
A scoped claim: One assertion with clear boundaries.
Named entities: The company, product, category, or concept is explicit.
Supporting proof: Original analysis, specific comparisons, or proprietary observations.
Retrievable framing: The passage can stand alone when quoted or summarized.
Semantic Density determines extractable value
The second term is Semantic Density. This is the amount of unique, decision-useful information packed into each retrievable segment.
Low-density content repeats consensus. High-density content advances the answer. That can come from original comparisons, sharper definitions, unconventional framing, or a synthesis that organizes fragmented knowledge into a more useful structure.
Models don't need another average summary. They need a reason to pull one source over another.
This is why “use bullet points and add schema” is inadequate as a service promise. Those are formatting primitives. They don't create differentiated evidence.
A more technical treatment of this engineering problem appears in this framework for technical GEO implementation. The commercial lesson is direct. Generative engine optimization services must build content that increases machine confidence and answer quality at the same time.
That is an engineering brief, not a copywriting brief. The asset being produced is not merely content. It is a citation-ready knowledge object.
Book a call with Algomizer for a visibility assessment.
Anatomy Of A GEO Services Engagement
A real engagement follows four operating phases
Professional generative engine optimization services follow a repeatable operating cycle. The work is continuous because model outputs shift as engines update retrieval layers, refresh inputs, and adapt their source preferences.
Industry guidance summarized by Walker Sands identifies four operational phases: source analysis, optimization, assessment, and refinement, alongside metrics such as citation frequency, share of voice, brand mentions, and sentiment in its GEO operations overview.
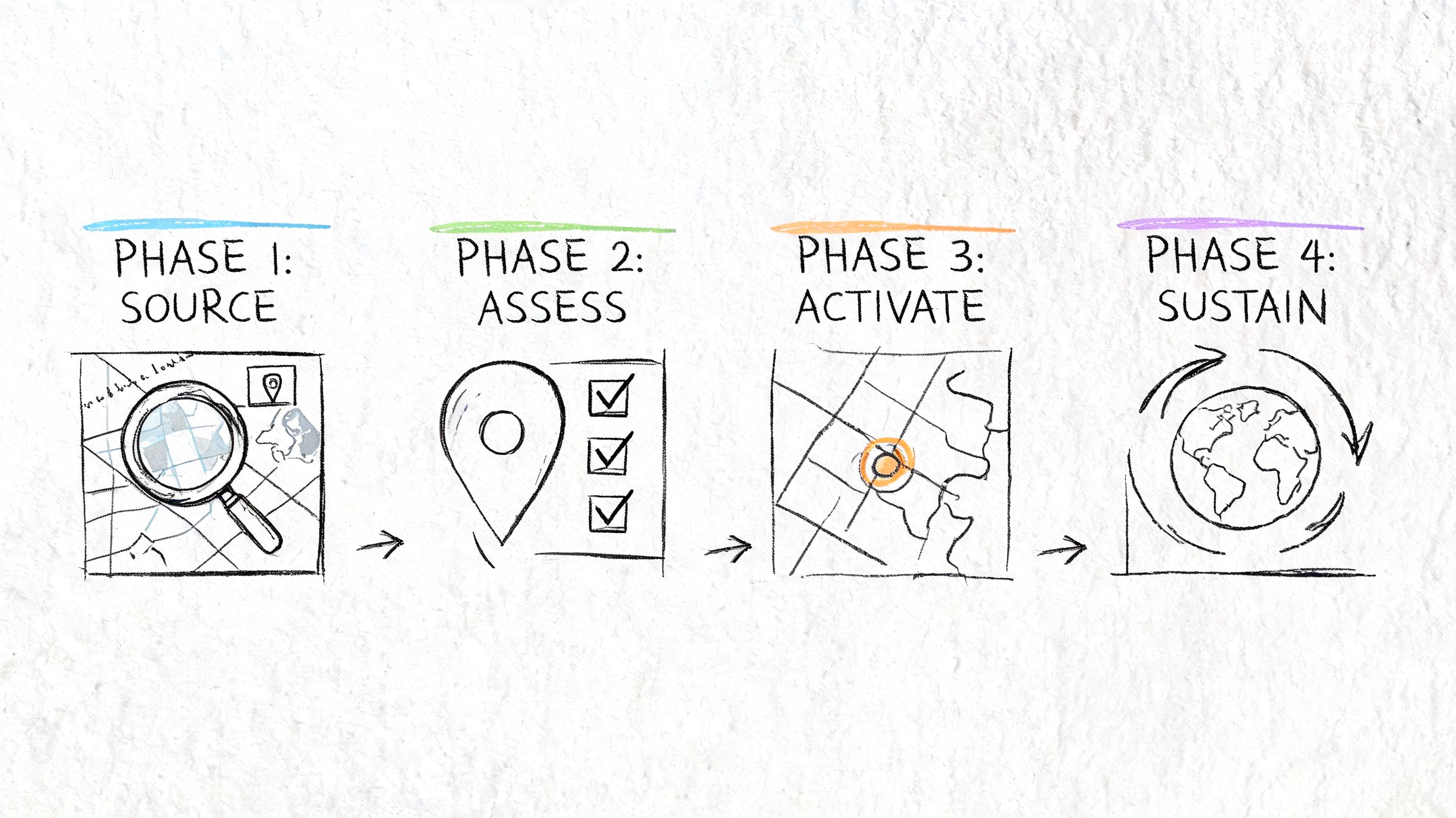
Those four phases translate into a practical engagement model.
Source analysis and prompt discovery
Teams map the prompts, entities, and competitor sources that shape answer visibility. The point isn't just to identify keywords. The point is to discover where the model already has a stable answer and where it still needs stronger evidence.Content engineering and evidence clustering
Existing assets are reworked into citation-ready structures. New assets are built around missing claims, undercovered comparisons, and answer formats the engines can reuse.
Continuous calibration is part of the service
Technical implementation and markup
Structured signals, entity clarity, and page architecture are aligned so retrieval systems can parse the content more reliably. This phase often determines whether good ideas become usable sources.
A useful illustration of how teams think through these mechanics appears below.
Assessment and refinement
Prompt sets are re-run, visibility shifts are logged, and competitor displacement is tracked. This is not optional maintenance. Walker Sands notes that ongoing monitoring and iteration are core service requirements because outputs change over time.
A CMO evaluating a proposal should expect deliverables across all four phases. A vendor offering only content edits is selling a partial system.
The durable asset in GEO is not a page. It is a calibrated feedback loop between prompts, sources, outputs, and revisions.
This is also the point where one factual option in the market is relevant. Algomizer offers managed AI-search visibility work that includes prompt discovery, content engineering, technical implementation, and cross-platform tracking using headless browsers. That is the shape of a full-service engagement, not a repackaged SEO sprint.
Book a call with Algomizer for a visibility assessment.
Measuring GEO Success And The Outcomes Based Model
Cross-model measurement is the market failure
The central reporting problem in GEO is fragmentation. A brand can appear differently across ChatGPT, Perplexity, Gemini, and AI Overviews, yet many service providers still report performance as if one dashboard could summarize all model behavior.
That limitation is now well recognized. Busy Like's analysis of answer engine optimization services notes a major gap in the market: most providers do not explain how to measure GEO outcomes reliably across models, how attribution should work, or how visibility can be compared in an auditable way across systems such as ChatGPT, Perplexity, and AI Overviews.
The implication is larger than reporting inconvenience. If optimization effects differ by engine and prompt type, then any single-platform metric can mislead budget allocation. A team may think it is “winning AI search” while only appearing in one environment and disappearing in another.
An outcomes model fixes incentive misalignment
A mature measurement stack therefore needs several layers:
Prompt-set tracking: The same strategic prompts must be tested repeatedly across platforms.
Citation logging: Teams need a record of whether the brand is cited, mentioned, or excluded.
Share-of-voice analysis: Visibility only matters in relation to competing sources.
Sentiment and framing review: A mention is not always a favorable mention.
Implementation details matter. Browser-based testing can reveal rendered answers and cited sources in ways that simplified reporting often misses. The point is not a flashy dashboard. The point is independent verification.
A related enterprise issue appears in this discussion of rank tracking for large organizations, where auditability and repeatability are treated as operating requirements rather than optional reporting polish.
The commercial consequence is straightforward. Fee structures should reflect measurable outcomes, not vague activity. If a GEO vendor can't define how visibility is observed across models, the client is being asked to fund process without proof.
Measurement is the service boundary. Without it, “optimization” is just unverified editing.
An outcomes-based model aligns incentives because it ties vendor compensation to achieved and retained visibility. That model also disciplines strategy. It forces everyone involved to define the prompts that matter, the entities that matter, and the answer surfaces that influence pipeline.
Book a call with Algomizer for a visibility assessment.
Vendor Evaluation Criteria And Your Next Steps
Enterprise buyers need auditable criteria
Most buyers don't need another GEO explainer. They need a way to distinguish a real service from an SEO package with updated vocabulary.
The first test is methodological clarity. A qualified vendor should explain how it measures brand presence across multiple AI systems, how it handles attribution, and how it validates outputs over time. If the answer stays abstract, the methodology likely doesn't exist at production depth.
The second test is technical scope. Enterprise teams should ask whether the service covers prompt discovery, source analysis, content engineering, implementation support, and calibration. A narrow editorial service won't hold up in a shifting retrieval environment.
A practical shortlist looks like this:
Measurement discipline: Ask how citation frequency, share of voice, brand mentions, and sentiment are captured across models.
Security posture: Ask whether the engagement requires access to PII or internal systems. Enterprise-ready services should minimize both.
Iteration model: Ask what changes after the first optimization pass and how often prompt benchmarks are rerun.
Evidence strategy: Ask how the team creates information gain rather than generic AI-friendly formatting.
Audit trail: Ask what an independent reviewer could verify without relying on the vendor's own claims.
The next move is controlled visibility testing
The strongest next step is a visibility assessment, not a full retainer. That lets a team evaluate where the brand appears now, where competitors dominate, and which prompts represent the clearest commercial openings.
Content operations should also be reviewed through an AI-first lens. For instance, teams repurposing expert interviews or webinars into citation-ready assets may find tools that turn video ideas into professional content useful because the raw material can be converted into structured source material faster. The important point isn't the tool itself. It is the discipline of converting proprietary knowledge into retrievable evidence.
The strategic conclusion is now unavoidable. Generative engine optimization services are not a side tactic inside search marketing. They are the operating layer for brand discovery in answer-led environments.
A company that wins those environments doesn't just gain visibility. It shapes the narrative users receive before a click, before a shortlist, and often before a vendor comparison even begins.
Book a call with Algomizer to request a complimentary visibility assessment and review how the brand currently appears across AI-generated answers.