AI Search Engine Optimization The Algomizer Framework
Master AI search engine optimization (AEO/GEO) with our proprietary framework. Learn to reverse-engineer LLMs and win citations in AI-generated answers.

Subtitle: Reverse-engineering citation visibility in answer engines
May, 2026
An Algomizer Research Paper
Executive summary: Traditional SEO no longer defines visibility. AI search engine optimization now decides whether a brand is retrieved, summarized, and cited inside Google AI Overviews, ChatGPT, Perplexity, and related answer engines.
The popular advice is wrong. Publishing “helpful content” and tightening standard on-page SEO won't reliably earn citations in AI answers, because answer engines don't reward pages the way classic search did. They assemble evidence, compress it, and cite selectively.
That changes the operating model for every CMO, SEO lead, and growth team. Search is no longer a ranking problem first. It is a recall, selection, and synthesis problem.
Table of Contents
Beyond Ten Blue Links Why AI Search Requires a New Discipline
Traditional SEO no longer defines the win condition
AI visibility is a citation market
How AI Search Engines Recall and Rank Information
Retrieval comes before generation
Algomizer uses Evidence Clusters as the unit of authority
AEO vs Traditional SEO A Side-by-Side Comparison
The optimization target has changed completely
The old playbook still matters but it no longer leads
Engineering Trust With Evidence Clusters and Semantic Density
Evidence Clusters create machine-verifiable trust
Semantic Density increases citation readiness
Information gain is the forcing function
Activating Your AEO Strategy A Practical Roadmap
The first month is diagnostic not editorial
Execution requires content, media, and observation together
Measurement has to observe the answer surface
Your Next Move in the Age of AI Search
The new objective is source status
Technical access remains the gate
Beyond Ten Blue Links Why AI Search Requires a New Discipline
AI search engine optimization exists because search interfaces now answer the query directly, which means brands lose visibility if they aren't selected as sources inside the answer.
Google's AI Overviews launched publicly in May 2024, and the old assumption that ranking equals traffic broke immediately. Industry reporting summarized by McKinsey on the age of AI search notes that over 45% of searches end in zero-click results by 2026, because AI-generated summaries increasingly satisfy intent inside the interface.
That single shift creates a new discipline. Traditional SEO was built to win a click from a ranked list. AI search engine optimization is built to win inclusion in a generated answer.
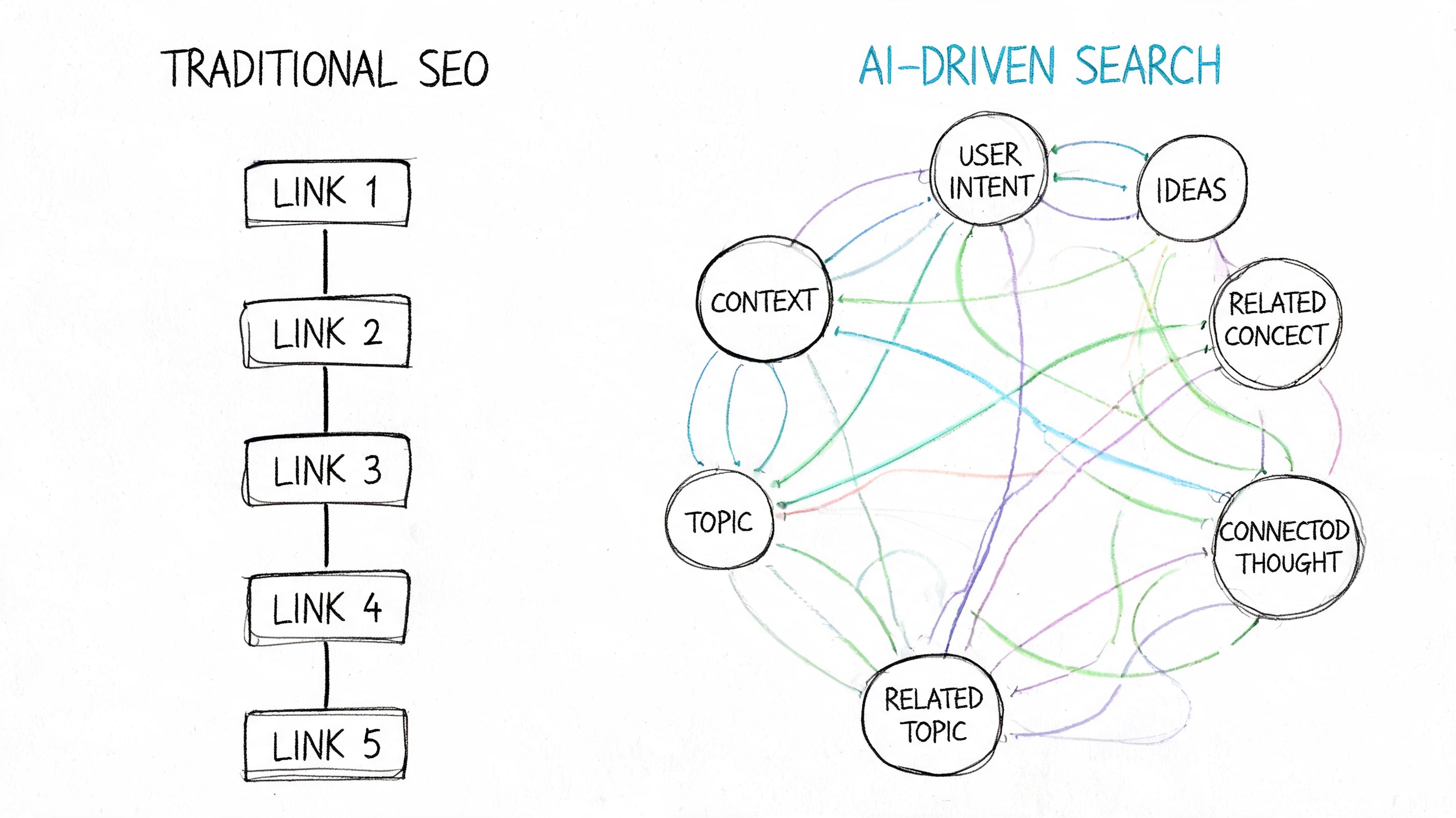
Traditional SEO no longer defines the win condition
Traditional SEO strategies still optimize as if the SERP is the product. It isn't. The answer layer is now the product for a growing share of queries, and that means the winning asset isn't always the page with the strongest blue-link ranking. It is the source that the model can retrieve, interpret, trust, and compress.
This is why conventional advice feels incomplete. Strong title tags, backlinks, and topical coverage still matter, but they now function as input signals into a retrieval system rather than as the end state.
Practical rule: If the strategy only asks “How do we rank this page?”, it is solving the previous search era.
A useful external complement to this shift is Big Moves Marketing's AI Overviews playbook, which frames how teams should adapt content planning for Google's answer surfaces. The larger point is sharper: AI visibility isn't a ranking extension. It is a retrieval architecture problem.
AI visibility is a citation market
The most important mental reset is this. AI systems don't just find documents. They assemble evidence from multiple documents and then decide which sources deserve attribution.
That turns search into a citation market. Brands aren't competing only for rank position. They are competing to become the source a model remembers and cites when synthesizing an answer.
For leaders still sorting the terminology, this explanation of LLMO helps distinguish language-model optimization from older search workflows. The distinction matters because answer engines reward structured authority, not just discoverable pages.
Three consequences follow:
Traffic becomes a lagging signal: A brand can be visible inside an answer without receiving the click.
Authority becomes distributed: Your website, third-party mentions, and corroborating references all shape recall.
Content must survive compression: If a claim loses meaning when summarized, it loses citation probability.
The operational implication is direct. AI search engine optimization is now the discipline responsible for making a brand machine-legible, source-worthy, and citation-ready.
Back to Chapter 1. Book a complimentary visibility assessment at algomizer.com.
How AI Search Engines Recall and Rank Information
Answer engines retrieve candidate evidence first, evaluate relevance and authority second, and synthesize a response third, which is why structure determines recall before prose influences persuasion.
The history of search points to this exact outcome. Google's PageRank in 1998 moved retrieval beyond simple keyword matching, and later systems such as BERT in 2019 pushed search further into semantic interpretation. The acceleration into AI search is now visible in usage patterns, with one industry report summarized by Amsive's SEO evolution analysis reporting 527% year-over-year growth in traffic from AI search platforms.
That growth isn't random. It reflects a different architecture.
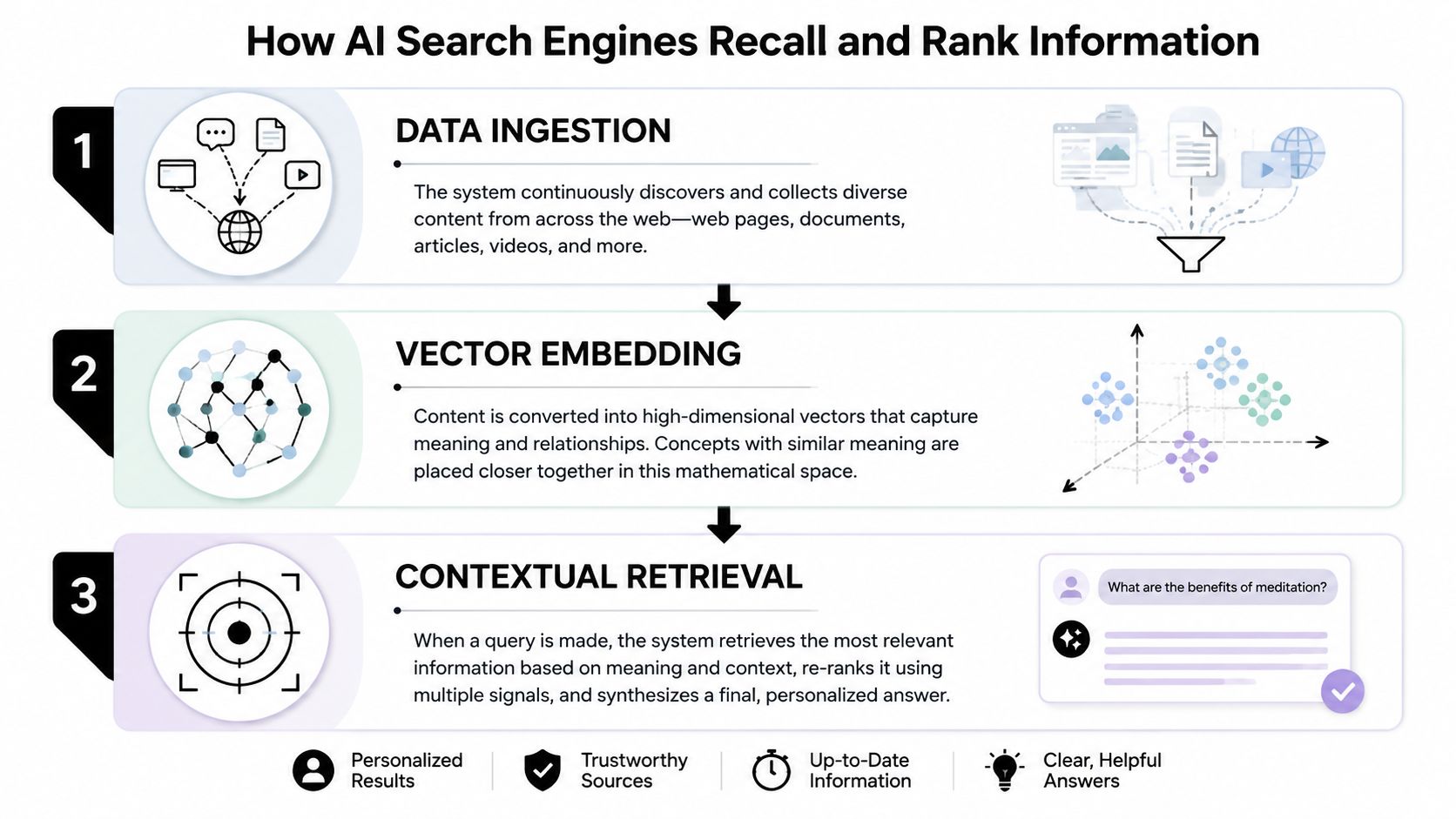
Retrieval comes before generation
Teams often treat ChatGPT, Perplexity, Gemini, and Google AI Overviews as black boxes. That's a strategic mistake. Their behavior becomes easier to influence once the mechanics are separated into three layers.
Candidate retrieval
The system pulls possible source material from indexed pages, knowledge stores, and associated references. If the page can't be fetched, parsed, or mapped clearly to the query, it often never enters the candidate set.Source selection and ranking
The engine evaluates which passages best satisfy the question. Relevance matters, but so do clarity, corroboration, and how well the source fits entity and topic understanding.Synthesis and citation
The model composes the final answer. It compresses multiple inputs into a single response and cites only a subset.
The key insight is that most content fails before generation begins. It never earns retrieval confidence.
AI engines don't “prefer great content” in the abstract. They prefer accessible evidence that fits the retrieval and synthesis workflow.
Algomizer uses Evidence Clusters as the unit of authority
The page is no longer the only unit that matters. In AI search engine optimization, the functional unit of authority is what this paper calls an Evidence Cluster. That is a network of aligned claims, passages, entities, and corroborating mentions that collectively improve recall and citation odds.
An Evidence Cluster usually includes:
Component | Function in recall and ranking |
|---|---|
Primary page | Holds the canonical explanation or claim |
Supporting passages | Provide concise answerable chunks that models can lift |
Entity signals | Clarify who the brand, product, person, or category is |
Third-party references | Corroborate trust and reduce ambiguity |
Technical accessibility | Ensures retrieval systems can fetch and parse the asset |
This is why isolated content campaigns underperform. A single article may rank, but fragmented evidence won't produce durable AI citations if the model can't validate and connect the claim set.
The operating principle is mechanical. Retrieval systems need semantically coherent material. Ranking systems need confidence. Synthesis systems need compressible language.
Back to Chapter 1. Book a complimentary visibility assessment at algomizer.com.
AEO vs Traditional SEO A Side-by-Side Comparison
AEO replaces the old objective of rank acquisition with a new objective of source selection, so the optimization target changes from pages and positions to passages and citations.
Most organizations still budget for AI search as if it's a bolt-on to SEO. That framing obscures the true transition. The underlying assumptions have shifted: what counts as authority, how visibility appears, and which assets truly drive discovery.
The optimization target has changed completely
The cleanest way to see the break is side by side.
Dimension | Traditional SEO (The Old Playbook) | AI Engine Optimization (The New Reality) |
|---|---|---|
Core goal | Rank pages in a list of results | Earn selection, summary inclusion, and citation in generated answers |
Primary visibility surface | Blue links on a SERP | Google AI Overviews, ChatGPT, Perplexity, Gemini, and related answer layers |
Unit of optimization | Full web page | Information chunk, answer passage, entity relationship, corroborating mention |
Dominant success signal | Ranking movement and click-through | Citation frequency, answer inclusion, and cross-platform mention consistency |
Authority model | Domain strength and link profile | Recall readiness, evidence alignment, machine-readable trust, and corroboration |
Content method | Topic coverage and keyword targeting | Content engineering for retrieval, compression, and synthesis |
Measurement approach | Search console, rankings, traffic | Direct observation of answer surfaces and source attribution |
Failure mode | Lower rank | No retrieval, no selection, or unattributed synthesis |
This comparison isn't semantic. It changes work allocation. Editorial teams need to think in passages. PR teams need to think in corroboration. Technical SEO teams need to think in crawl and render integrity for answer systems.
For teams formalizing that transition, this overview of answer engine optimization is a useful definitional baseline.
The old playbook still matters but it no longer leads
Traditional SEO still supplies infrastructure. Crawlable pages, sound information architecture, and authority signals remain useful inputs. But they no longer define the finish line.
A simple decision test clarifies the difference:
If the question is about rank position, that's old-playbook thinking.
If the question is about source eligibility, that's AI-first thinking.
If the content is optimized for clicks rather than extraction, it will often underperform in answer engines.
The shift isn't from SEO to “better SEO.” The shift is from ranking logic to citation logic.
That distinction changes staffing, reporting, and expectations. A team can improve rankings and still lose AI visibility if the content isn't structured for retrieval and summary. Conversely, a team can gain answer-surface presence before traditional analytics fully register the impact.
Back to Chapter 1. Book a complimentary visibility assessment at algomizer.com.
Engineering Trust With Evidence Clusters and Semantic Density
Winning citations requires engineered trust, not generic quality, and that trust emerges when claims are corroborated, chunked clearly, and differentiated with information other sources don't provide.
The market is saturated with vague advice about expertise and quality. That advice misses the machine layer. LLM-driven search doesn't reward content because it sounds authoritative. It rewards content that can be verified, compared, and compressed with low ambiguity.
This paper uses two operating concepts for that work: Evidence Clusters and Semantic Density.
Evidence Clusters create machine-verifiable trust
An Evidence Cluster is the distributed proof set around a claim. It includes the canonical page, supporting pages, entity references, and third-party corroboration that allow an answer engine to treat the claim as stable rather than isolated.
That model changes content planning. The task isn't to write a definitive post. The task is to create a cluster of mutually reinforcing assets.
A strong cluster usually has these properties:
Canonical clarity: One page states the core definition, method, or position plainly.
Distributed corroboration: Other pages and external references restate the idea in compatible language.
Entity consistency: Product names, brand descriptors, category labels, and authorship stay stable.
Technical readability: The material is easy for crawlers and parsers to fetch and interpret.
Editorial and off-site strategy converge at this point. Teams that separate them often weaken recall because the evidence never coheres.
Semantic Density increases citation readiness
Semantic Density describes how much precise, extractable meaning a passage contains relative to its length. Dense passages answer one question clearly, define the terms they use, and avoid ornamental language that degrades compression.
In practice, higher Semantic Density often comes from format decisions more than style decisions. Passage design matters.
Passage trait | Effect on AI citation readiness |
|---|---|
Direct definition near the top | Improves answer extraction |
Stable terminology | Reduces entity confusion |
Short explanatory blocks | Increases passage portability |
Clear relationship between claim and support | Improves synthesis reliability |
Semrush's findings, summarized in its study on technical SEO's impact on AI search, reinforce the technical side of this model. The study found that cited pages frequently used Organization, Article, and BreadcrumbList schema, and that cited URLs often had concise descriptive slugs in the 17 to 40 character range. The implication isn't that schema “ranks” content by itself. It reduces ambiguity, which helps entity recognition and citation selection.
For teams evaluating source-level citation behavior, citation analysis for AI search engines is directly relevant to this layer of execution. A practical companion on trust signaling is Humantext.pro's AI content and Google EEAT guide, especially for teams aligning editorial standards with machine-readable authority.
Information gain is the forcing function
Most AI search advice overemphasizes completeness. Completeness is table stakes. Differentiation drives selection.
Animalz's analysis of information gain in AI search content argues that content becomes more valuable when it adds a contrarian or alternative angle that other sources don't already contain. That matters because AI Overviews and related engines synthesize from multiple documents. If a page merely restates consensus language, it becomes replaceable inside the synthesis step.
A page earns citation leverage when removing it would reduce the answer's distinctiveness.
This is the practical test for novelty. Not “Is the content good?” but “Does the answer become weaker without this source?” That is the threshold for engineered trust in AI search engine optimization.
Back to Chapter 1. Book a complimentary visibility assessment at algomizer.com.
Activating Your AEO Strategy A Practical Roadmap
AEO execution works when teams sequence diagnosis, deployment, and observation correctly, because answer-engine visibility depends on evidence design and direct measurement of the answer surface.
The first move isn't publishing more. It is identifying where the brand already appears, where competitors are being cited, and which topics trigger answer synthesis across platforms.
The first month is diagnostic not editorial
The strongest programs begin with observation.
A practical roadmap looks like this:
Weeks 1 to 4, assessment and discovery
Teams map brand, product, and category prompts across Google AI Overviews, ChatGPT, and Perplexity. They identify recurring citation sources, weak entity associations, and missing answer formats.Weeks 5 to 10, content and media execution
Editorial assets are rebuilt into answerable passages, evidence gaps are filled, and corroborating mentions are pursued through media and reference placements.Weeks 11 to 12 and beyond, calibration
Teams compare citation patterns across platforms, isolate prompts that changed, and refine pages or proof points that still fail retrieval.
This roadmap is more reliable than volume-first publishing because it starts with the retrieval environment. A useful complementary read for internal team workflows is Prompt Builder's guide to optimizing SEO with AI, especially for content operations adapting to AI-assisted production.
Execution requires content, media, and observation together
The implementation stack has three moving parts.
Content engineering: Pages need direct definitions, answer blocks, stable terminology, and machine-readable structure.
Media placement: Third-party corroboration strengthens evidence clusters and improves source confidence.
Technical implementation: Rendering, crawlability, and snippet controls have to support retrieval rather than block it.
One option in this category is Algomizer, which offers AI visibility assessment, cross-platform citation tracking, and managed optimization for answer engines. The operational point is broader than any single vendor. Teams need a system that can observe AI outputs directly and tie changes back to content and evidence decisions.
A short explainer helps clarify why observation has to happen at the answer layer:
Measurement has to observe the answer surface
Traditional analytics miss a large share of AI visibility because the exposure often happens without a click. Guidance summarized by The Repp Group on being found in AI prompts stresses that effective measurement requires tracking citations across platforms such as Google AI Overviews, ChatGPT, and Perplexity, and using headless browser observation rather than depending on standard analytics APIs that don't capture the answer experience itself.
That changes reporting. Teams should track:
Measurement layer | What to watch |
|---|---|
Prompt coverage | Which priority prompts produce AI answers |
Citation share | Which domains are cited repeatedly |
Brand inclusion | Whether the brand appears, how it's described, and in what role |
Answer drift | How wording and cited sources change over time |
Visibility without a click still changes preference, recall, and shortlist formation. Measurement has to capture that exposure directly.
Back to Chapter 1. Book a complimentary visibility assessment at algomizer.com.
Your Next Move in the Age of AI Search
The strategic objective now is becoming the source an AI system trusts to answer the market's most valuable questions, not merely appearing somewhere in a ranked list.
That reframes AI search engine optimization as more than a marketing tactic. It is now part of reputation control. When Google AI Overviews, ChatGPT, Gemini, or Perplexity summarize a category, they compress market perception into a few cited sources and a short narrative. Brands that shape that narrative gain disproportionate influence.
The new objective is source status
This is the core shift. The question isn't “How does the brand rank?” It is “When the model explains this category, does the brand appear as a source, a recommendation, or a reference point?”
That standard forces sharper prioritization:
Own the claims that matter most: Define categories, methods, comparisons, and decision criteria clearly.
Build corroboration outside owned media: A claim repeated consistently across trusted surfaces is easier for machines to reuse.
Design for compression: If a passage can't survive summarization, it won't drive answer-layer visibility.
Technical access remains the gate
None of that strategic work matters if answer engines can't fetch the content. Google's guidance, summarized in its post on succeeding in AI search, makes the prerequisite explicit: pages blocked by robots.txt, noindex directives, or rendering issues are far less likely to appear in AI-generated answers.
That has a simple implication. Foundational technical SEO is still mandatory, but its purpose has changed. It is no longer just about being indexed for search results. It is about being accessible enough to become source material for AI synthesis.
The brands that move first will define the language the models reuse. Everyone else will compete inside narratives written by other sources.
Back to Chapter 1. Book a complimentary visibility assessment at algomizer.com.
Brands that need a clear read on how they appear inside AI-generated answers can book a complimentary visibility assessment with Algomizer. The assessment maps citation presence across major answer engines, identifies retrieval gaps, and shows where technical, editorial, and corroboration work is most likely to improve AI search visibility.