What Is LLMO: The AI Search Visibility Guide for Brands
What is LLMO? Learn how Large Language Model Optimization works, why it's different from SEO, and the strategic roadmap brands need to get cited in AI answers.

AI Search Visibility Is No Longer Won at the Page Level. It Is Won at the Evidence Level.
Traditional SEO still matters for websites. It no longer defines discoverability inside AI systems. That shift started when ChatGPT reached 100 million users in two months after its November 30, 2022 launch, accelerating the move from blue links to synthesized answers, as documented by Evergreen Media’s guide to large language model optimization.
The practical consequence is sharper than most marketing teams admit. A search result used to be a ranked destination. An AI answer is a probabilistic composition. The machine doesn’t need a full page. It needs extractable facts, stable entities, and verifiable structure. That is what what is llmo asks at a strategic level. It asks how a brand becomes retrievable, reusable, and citable inside a model.
This paper treats LLMO as an engineering discipline, not a content trend. The analysis follows the mechanics of answer engines, isolates the signals that survive model retrieval, and translates those mechanics into operating rules for brand teams. For organizations evaluating AI-first visibility, Algomizer sits in the category of providers focused on answer engine optimization and cross-model brand visibility.
Executive summary: LLMO is the discipline of shaping content so large language models can identify, trust, and cite it during answer generation.
Table of Contents
An Algomizer Research Paper on LLMO
LLMO starts where ranking stops
The market has already shifted
Deconstructing the AI Answer Engine
The unit of visibility is the content chunk
RAG behaves like a research assistant
The LLMO vs SEO Showdown
How the optimization model changes
The Algomizer Framework The Four Pillars of LLMO
Entity clarity removes identity loss
Semantic density raises extractable value
Verifiability signals reduce model hesitation
Answerability structure turns content into reusable output
LLMO in Action Use Cases and Measurement
The KPI is citation share not raw ranking
Three operating scenarios show how measurement changes
The CMOs Strategic Roadmap for LLM Dominance
Audit first because visibility is often mismeasured
Optimization must become an operating system
Scale turns citation into market perception
An Algomizer Research Paper on LLMO
LLMO starts where ranking stops
Brand visibility in AI is now an engineering problem. Large language models do not reward a page as a single asset. They assemble answers from entities, claims, corroborating passages, and retrieval-friendly fragments that survive compression into a finite context window.
That mechanical shift changes how visibility is won. In search, competition centered on position. In AI answer systems, competition centers on citation, inclusion, and narrative control inside the generated response. A model can exclude the click and still shape vendor consideration, category language, and perceived market leaders.
Many executive dashboards still track sessions, rankings, and click-through rate. Those measures describe browser behavior. They do not explain whether a model can identify a brand, verify its claims, and reuse its content under answer-generation constraints.
The market has already shifted
User behavior has moved toward conclusion-first interfaces. People ask for a recommendation, summary, comparison, or shortlist and expect the system to synthesize the answer immediately. That changes the target of optimization. The objective is no longer limited to getting the visit. The objective is getting selected as evidence.
This is the premise behind Algomizer’s AI visibility research and optimization methodology. The relevant question is not whether a page exists or even whether it ranks. The relevant question is whether the brand has produced enough machine-legible proof, in enough consistent forms, for a probabilistic model to cite it with low hesitation.
A useful definition follows from that shift:
LLMO defines the entity so the model can resolve who the brand is, what it offers, and which claims belong to it.
LLMO organizes evidence into reusable units so product facts, category descriptions, and differentiators can be retrieved without distortion.
LLMO raises citation probability by increasing semantic density, source consistency, and verifiability across the open web.
AI visibility is a retrieval and evidence design discipline.
That conclusion has operational consequences. Content strategy, technical SEO, digital PR, structured data, and brand governance now affect the same output surface. If those functions publish conflicting claims, weak attribution, or vague category language, the model does not reconcile the inconsistency in the brand’s favor. It often excludes the brand from the answer or mentions it with reduced confidence.
Traditional search optimization is insufficient because it optimizes the page, while LLMO optimizes the evidence unit. That distinction sounds narrow. It changes the entire workflow. Teams must build Evidence Clusters that reinforce the same entity and claim across multiple retrievable contexts, then increase Semantic Density so each passage carries enough information to survive truncation and still remain quotable.
For CMOs, the budget question follows directly from the mechanism. Spend should move toward a structured citation program with clear entity definitions, evidence engineering, and independent verification of how often AI systems mention the brand in commercially relevant prompts.
Back to Chapter 1. To discuss how a brand appears across AI-generated answers, book a call with Algomizer.
Deconstructing the AI Answer Engine
The unit of visibility is the content chunk
AI answer engines surface snippets, not pages. That single mechanical fact explains why old optimization habits break when a user asks ChatGPT, Claude, Copilot, Gemini, or Perplexity for a recommendation.
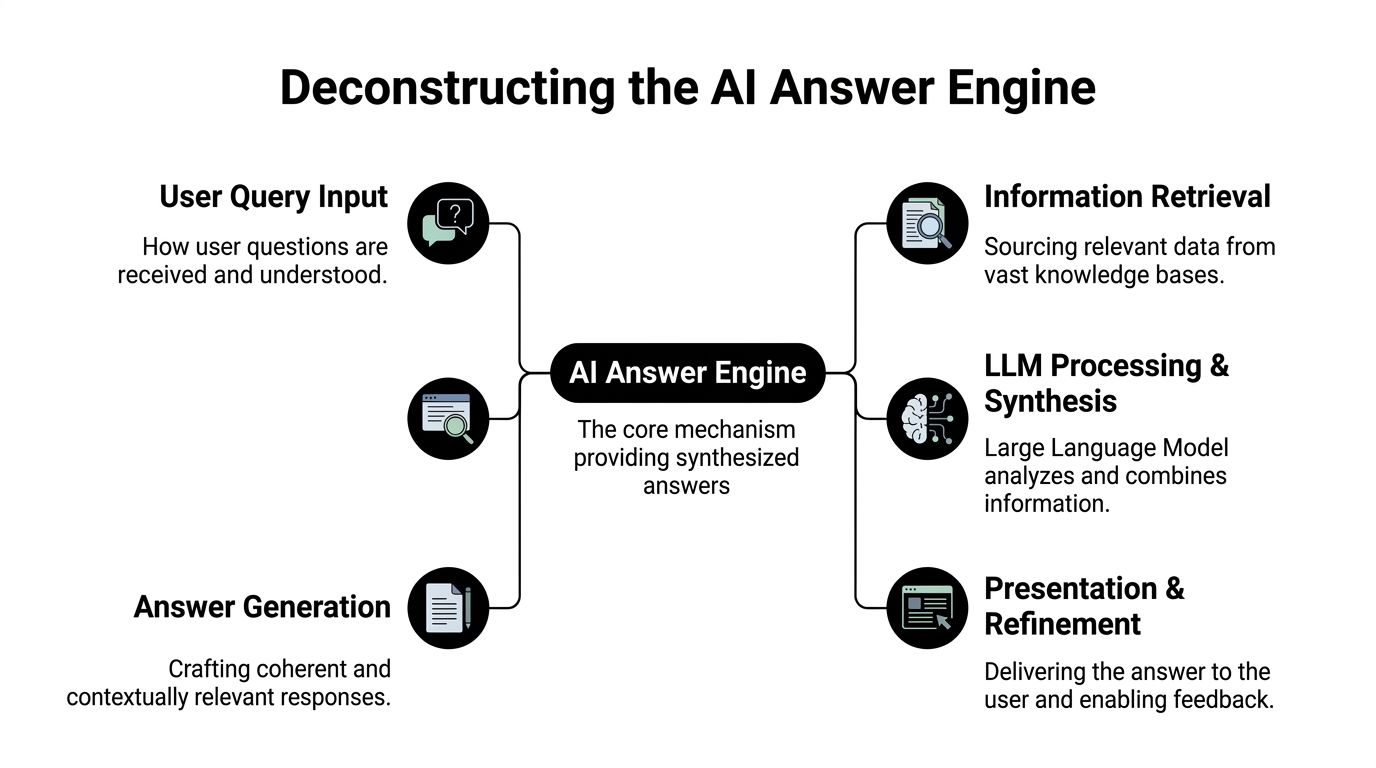
Google’s legacy model worked like a librarian. It indexed pages, scored links, and returned a ranked list of destinations. An answer engine behaves more like a research assistant. It interprets the question, retrieves candidate material, compresses that material into a narrow working context, and then writes a response.
That is why the content chunk has replaced the page as the primary unit of optimization. If a paragraph, table, definition, or product description can survive retrieval and fit inside a model’s working window, it has a chance to shape the answer. If it can’t, the page’s overall authority is less useful than teams assume.
RAG behaves like a research assistant
Retrieval-augmented generation is often described as a black box. It isn’t. It is a chain of operations. The system receives a query, identifies semantically related material, selects passages that appear useful, then conditions the generation step on that retrieved context.
The architecture rewards structure over ornament. It prefers content that can be isolated without losing meaning.
A concise engineering rule emerges from that behavior:
Practical rule: If a paragraph needs the entire page to make sense, it is poorly suited for AI retrieval.
Snippet-level reuse becomes measurable, as Hashmeta’s LLMO guide notes that, before AI, top-10 positions captured 75% of clicks, while LLMO now focuses on snippet reuse, and content with Schema.org markup sees 2-4x better entity recognition in models like Claude and Copilot.
That evidence explains why teams should stop asking whether a page “ranks” and start asking whether a fact can be extracted cleanly. The page is now a container. The retrievable unit is the atomic statement.
A simple contrast clarifies the change:
Retrieval model | What the system favors | Failure mode |
|---|---|---|
Link-based search | Page authority and query-match relevance | Strong page, weak answerability |
AI answer engine | Compact, semantically legible evidence | Rich page, unusable chunks |
The reverse-engineering implication is straightforward. Brands need to write for machine segmentation. Semantic headings, self-contained paragraphs, explicit entities, and structured definitions are not formatting choices. They are retrieval controls.
Teams that want a deeper technical treatment of this machine-behavior lens can use Engineering Truth and the technical framework for GEO as a companion reference.
Back to Chapter 1. To evaluate how current content behaves inside answer engines, book a call with Algomizer.
The LLMO vs SEO Showdown
Winning AI visibility requires a different operating model than winning search rankings. Search engines score pages against a query. LLMs assemble answers from evidence they can identify, attribute, and reuse with low risk of distortion. That shift changes what a marketing team is optimizing, what engineering teams must publish, and what leadership should measure.
The practical consequence is easy to miss. A page can perform well in search and still disappear inside an answer engine if its claims are diffuse, weakly sourced, or hard to extract at the passage level. In LLM environments, the unit that matters is often the evidence block, not the URL.
A more accurate frame is retrieval engineering. As noted earlier, industry guides on LLMO converge on four recurring controls: entity clarity, chunking, verifiability, and answerability. Analysts discussing AI citation behavior also point to a consistent pattern: systems such as Perplexity and AI Overviews cite content more often when claims are explicit and readily verifiable.
How the optimization model changes
The comparison below captures the shift in operating assumptions.
Dimension | Traditional SEO | LLMO / GEO |
|---|---|---|
Core objective | Gain visibility through rankings | Gain inclusion inside generated answers |
Unit of optimization | Page or URL | Passage, entity, claim, evidence cluster |
Dominant signal | Relevance and authority | Extractability, attribution, and verifiability |
Primary tactics | Keywords, internal links, backlinks | Entity consistency, structured claims, schema, direct answer formatting |
Reporting metric | Rankings, clicks, traffic | Citation frequency, mention share, answer presence |
Common failure mode | Low position in results | Omission, paraphrase loss, or unattributed reuse |
This is why superficial SEO translation fails. Expanding keyword sets or adding links may improve discovery conditions, but those steps do little if the model cannot isolate a claim, connect it to the right entity, and reproduce it safely.
Algomizer’s reverse-engineering work uses a different vocabulary because the machine is solving a different problem:
Semantic Density measures how much unambiguous meaning a passage carries per token.
Evidence Clusters group claims, sources, and entity references into units the model can retrieve without cross-page reconstruction.
Citation Share tracks how often a brand appears in model outputs for a topic set, which is closer to business impact than raw ranking share.
The system favors evidence it can compress, verify, and attribute.
Authority still matters, but its role is narrower than many teams assume. Strong domains improve the chance that content is crawled, indexed, and considered. Citation behavior depends on whether the underlying material is machine-legible at the claim level. That is the distinction explored in The Weight of Authority in GEO, which examines how domain strength interacts with answer-engine reuse.
For teams building the execution layer, LLM Optimization techniques to improve AI search visibility offers a useful tactical companion. The strategic point remains the same. SEO improves the probability that a page is seen. LLMO improves the probability that a brand becomes part of the answer.
Back to Chapter 1. To align search reporting with answer-engine behavior, book a call with Algomizer.
The Algomizer Framework The Four Pillars of LLMO
Citation in LLMs is an engineering outcome, not a reputation outcome. A brand appears in generated answers when four controls align: the model can resolve the entity, extract the claim, validate the evidence, and reuse the material in answer form.
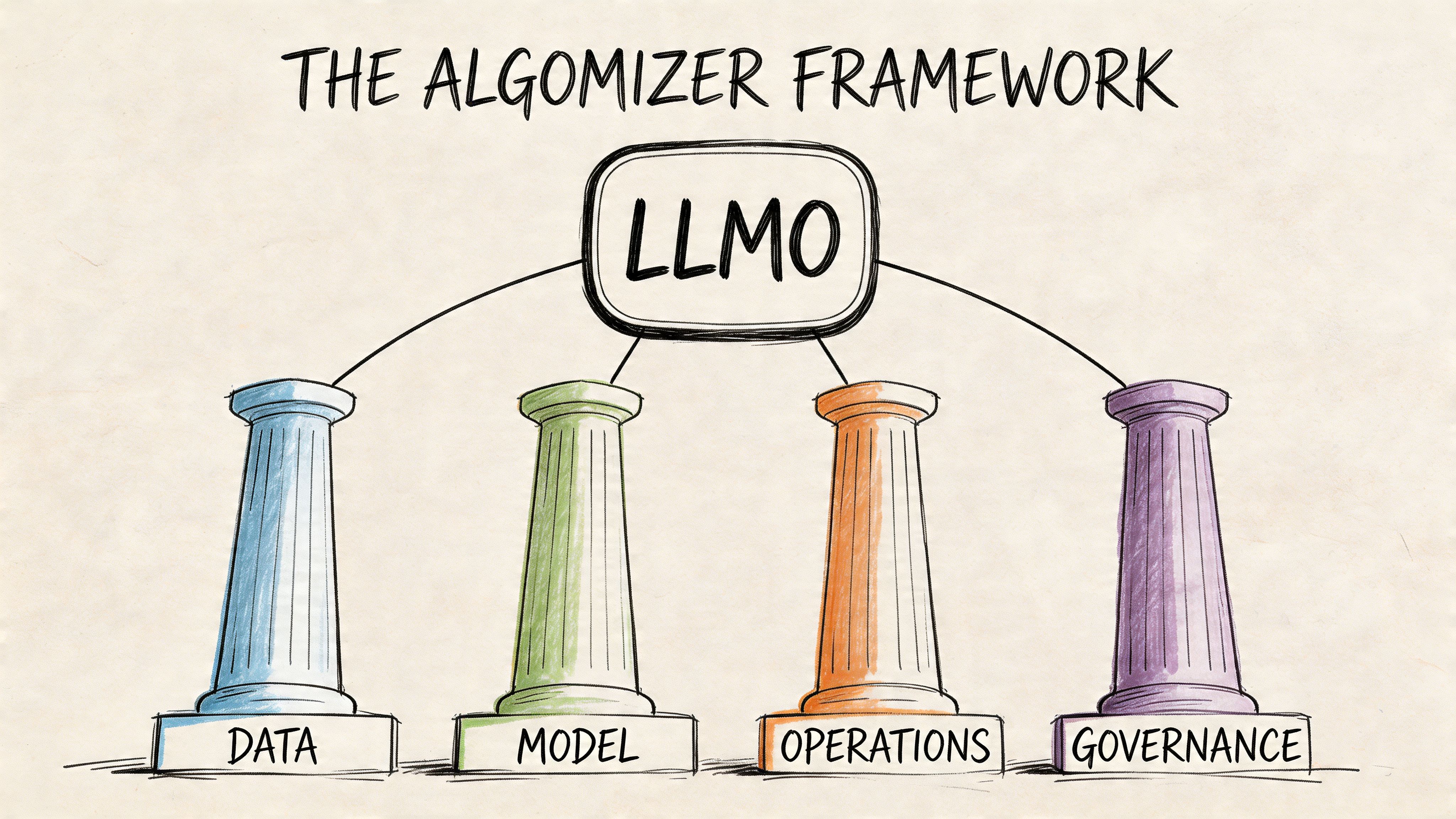
Algomizer treats those controls as a system, not a checklist. The four pillars below map to the main failure modes we see when reverse-engineering why one source gets cited and another gets ignored. The practical advantage is repeatability. Teams can diagnose where citation probability breaks, then repair the specific layer that blocks reuse.
Entity clarity removes identity loss
Entity clarity determines whether a model can collapse scattered references into one stable brand object. If product pages, corporate pages, executive bios, and third-party profiles describe the company with inconsistent category terms, the model has to infer whether those records refer to the same entity. That inference step introduces loss.
The fix starts with naming discipline across public assets. Company name, product name, category, use case, and key differentiators should recur in stable combinations. Schema markup and sameAs references strengthen that graph by tying the brand to external identifiers.
Earlier research cited in this article found that stronger entity clarity is associated with materially higher citation rates. The operational lesson matters more than the exact percentage. Brands with consistent entity architecture give models fewer chances to split relevance across duplicate or weakly connected representations.
A common enterprise failure case is straightforward. The site describes a platform as "revenue intelligence," LinkedIn calls it "sales analytics," the press release frames it as "RevOps software," and review profiles use a fourth label. Human buyers can usually reconcile that variation. A probabilistic model often cannot.
Semantic density raises extractable value
Semantic density measures how much usable meaning survives compression at the paragraph level. Passages with high density present one clear claim, attach it to specific nouns, and minimize filler that forces the model to recover context from surrounding text.
That property changes citation behavior because answer engines retrieve fragments, not full narratives. If the evidence for a claim is distributed across several vague paragraphs, extraction gets harder and attribution gets less reliable.
Regulated sectors expose the constraint sharply. In Damespeak’s analysis of LLMO in regulated fields, 70% of financial services see zero AI citations due to data scarcity. The implication is structural. These firms do not need broader brand prose. They need tighter evidence packaging so the model can locate and reuse defensible claims without reconstructing them.
Three editing rules improve semantic density quickly:
Reduce each paragraph to one claim: Retrieval works better when each block has a single job.
Use descriptive subheads: They function as routing labels for both users and models.
Separate category facts from brand facts: Attribution improves when the model does not have to infer which statement belongs to which entity.
For teams comparing implementation methods, LucidRank’s overview of LLM Optimization techniques to improve AI search visibility complements this framework with formatting tactics.
Verifiability signals reduce model hesitation
Verifiability governs whether a model considers a source safe enough to reuse. Claims with clear provenance, visible dates, attributable authorship, structured context, and supporting evidence create lower-risk inputs for answer generation.
The mechanism is straightforward. Models and answer engines rank relevance, but they also filter for reuse risk. A page can contain the right fact and still fail citation if the claim looks weakly sourced, commercially inflated, or detached from any checkable evidence.
This explains why legal, financial, and healthcare brands often need stricter source controls than SaaS vendors. In those categories, minor ambiguity carries higher downstream risk, so the threshold for reuse rises. Evidence Clusters matter here because they package the claim, proof, and entity reference into a unit the model can lift without guesswork.
A visual walkthrough helps clarify how these controls interact in production.
Answerability structure turns content into reusable output
Answerability determines whether the source already resembles the response format the model is trying to produce. Definitions, comparisons, FAQs, scoped recommendations, short tables, and explicit qualification statements all reduce the transformation work required at generation time.
Many brand programs often break down. Teams publish persuasive thought leadership, but the core claims sit inside narrative copy built for sequential reading. Forums, directories, and reference pages often outperform them because those sources expose answer-ready blocks with clearer boundaries and lower rewrite cost.
Answerability also interacts with the other pillars. High semantic density without verifiability can still block reuse. Strong entity clarity without answer-ready formatting can still leave the brand out of the final synthesis. Citation probability rises when all four controls reinforce each other.
Pillar | What it fixes | What happens without it |
|---|---|---|
Entity clarity | Identity ambiguity | Brand confusion |
Semantic density | Low extractability | Weak retrieval |
Verifiability | Trust deficit | Citation avoidance |
Answerability | Reuse friction | Omission from final answer |
Back to Chapter 1. To map these four pillars against existing brand assets, book a call with Algomizer.
LLMO in Action Use Cases and Measurement
The KPI is citation share not raw ranking
Most brands can’t measure LLMO accurately with standard dashboards. The reporting stack was built for search referrals, not for synthetic answers rendered across multiple models.
That measurement gap is now large enough to distort budget decisions. ClickPoint Software’s review of the attribution problem reports that 65% of brands struggle with LLMO attribution, and that headless browsers capture 20-30% more citations than APIs due to dynamic rendering.
The strategic implication is immediate. If a team relies on APIs alone, it is likely undercounting presence, misreading model behavior, and optimizing against incomplete evidence.
Three operating scenarios show how measurement changes
A useful measurement model tracks three KPIs across ChatGPT, Claude, Gemini, Copilot, and Perplexity:
Citation Share of Voice: How often the brand is mentioned or cited against named competitors.
Topic Authority Coverage: Which prompts and subtopics produce a brand mention.
Generation Framing: Whether the brand appears as a leader, niche option, comparison point, or omission.
Those KPIs are clearer when attached to operating scenarios.
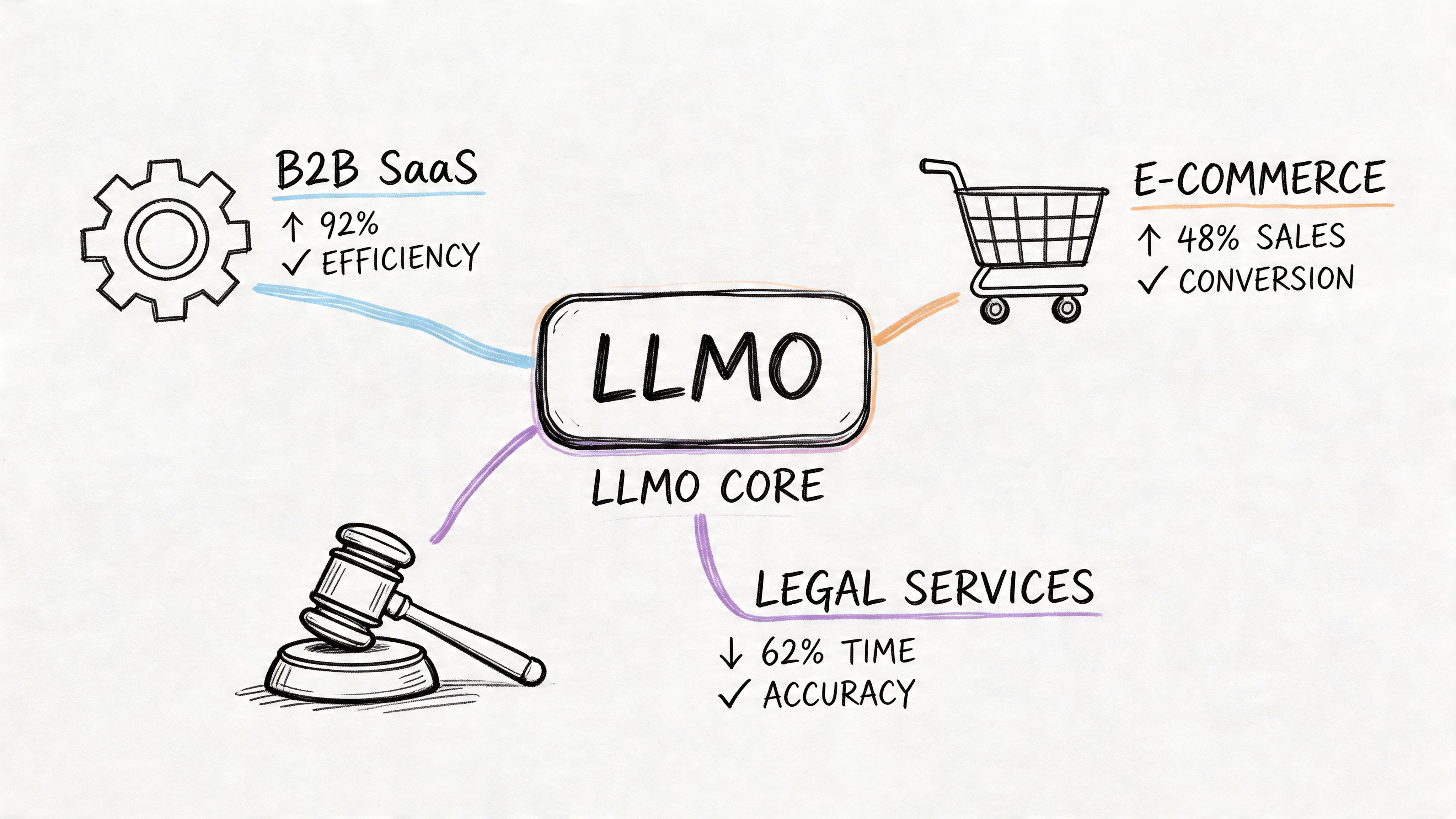
Scenario | Traditional metric | LLMO metric | What the team learns |
|---|---|---|---|
B2B SaaS | Organic traffic to feature pages | Citation share on category prompts | Whether the model associates the vendor with the category |
Financial services | Rankings for service terms | Presence on compliance-sensitive prompts | Whether evidence is strong enough for cautious AI outputs |
Legal services | Local SEO positions | Framing in “best firm” and “what to do if” prompts | Whether the brand appears as trusted guidance or is ignored |
A B2B SaaS company usually discovers that comparison pages and implementation guides outperform glossy product copy because they contain cleaner evidence blocks. A financial services firm often finds the opposite problem. It has authority, but not enough public, machine-usable specificity. A law firm may have strong location pages yet weak answerability on procedural questions that models prefer to summarize directly.
One category of platform is built around this cross-model verification method. Algomizer, for example, uses headless-browser based tracking across major LLM interfaces and independently verifiable reporting, which fits the need described above without relying on API-only visibility snapshots.
The wrong metric hides the right opportunity. LLMO performance often exists before web analytics can see it.
The executive reporting shift is simple. A monthly AI visibility report should ask where the brand was cited, on which topics, in what framing, and against whom. It should not start with traffic.
Back to Chapter 1. To build a cross-model measurement baseline, book a call with Algomizer.
The CMOs Strategic Roadmap for LLM Dominance
Audit first because visibility is often mismeasured
The first move is not content production. It is auditing answer-engine presence across priority prompts. Teams often lack knowledge of where the brand appears, how competitors are framed, or which topics are being lost to neutral data sources.
The audit should classify prompts by business value, then compare actual AI outputs across major platforms. This reveals entity gaps, missing proof points, and content forms that models ignore. Teams working on mastering LLM brand visibility and AI SEO often benefit from this prompt-led view because it connects visibility to brand positioning rather than to isolated pages.
Optimization must become an operating system
The second stage is engineering, not editorial patchwork. The brand has to normalize naming, tighten evidence blocks, upgrade structured data, and rewrite key assets into answerable formats. Product pages, comparison pages, FAQs, category explainers, executive bios, and third-party profiles all need alignment.
A concise leadership checklist helps:
Audit and benchmark: Capture current mentions and competitor patterns across priority prompts.
Optimize the evidence layer: Apply the four pillars to the assets that shape category understanding.
Institutionalize monitoring: Re-check prompt sets because models, retrieval layers, and answer styles change.
Scale turns citation into market perception
The third stage is scale and defense. Once a brand is present on a core set of prompts, the goal changes from isolated wins to durable topic ownership. Coverage expands outward from the commercial core into adjacent questions, use cases, objections, and comparison language.
LLMO thus functions as a brand-governance function rather than a channel tactic. If a model repeatedly cites a company on critical prompts, that company becomes the machine’s reference point for the category. Visibility then compounds into perception.
That is the profound shift CMOs need to internalize. What is llmo? It is the discipline of making the brand legible to machines at the exact moment machines mediate demand. The winners won’t merely be easier to find. They will become the sources that answer engines trust to explain the market itself.
Algomizer helps brands improve visibility inside AI-generated answers across platforms such as ChatGPT, Claude, Gemini, and Perplexity through visibility assessment, content engineering, technical implementation, and ongoing calibration. Marketing leaders who want a factual baseline of current AI presence can book a call with Algomizer.