How to Rank in ChatGPT: Master AI Answers 2026
Learn how to rank in ChatGPT with our GEO playbook. Get the framework for winning visibility and higher ranking in AI answers. Updated for 2026.

Subtitle: Generative Engine Optimization 101
Date: April 20, 2026
Most advice on how to rank in ChatGPT is incomplete because it treats AI visibility like a content formatting exercise. It isn't. The central failure is measurement. Existing coverage heavily emphasizes optimization tactics while underserving the tracking problem in probabilistic AI responses, where citations vary dramatically across repeated queries with <1 in 100 chance of identical brand lists, as noted by Ahrefs’ discussion of ranking in ChatGPT.
That single fact changes the discipline.
A brand can't improve what it can't observe consistently. A team can't claim progress because one prompt returned one citation on one day. AI search visibility is unstable at the output layer, so the operating model has to move deeper, toward retrieval mechanics, passage construction, citation probability, and cross-query coverage.
That shift is why Generative Engine Optimization, or GEO, now stands apart from SEO as its own discipline. GEO isn't a rewrite of old search habits. It's an engineering framework for producing passages that language models can retrieve, reason over, and cite.
For teams in verticals where buyer intent is narrow and highly comparative, the implications are already visible. ListingBooster's piece on AI SEO for real estate agents is a useful example of how AI-first discovery changes local and transactional content strategy when prompts become conversational, comparative, and intent-rich.
Table of Contents
Executive Summary The End of SEO
Most advice fails at the measurement layer
GEO is an engineering discipline
The Architectural Shift From Pages to Passages
ChatGPT retrieves chunks, not brand promises
RRF rewards breadth across query variations
The Algomizer Framework Evidence Clusters and Semantic Density
Evidence Clusters create machine-readable trust
Semantic Density turns passages into citation candidates
External mention patterns reinforce retrieval confidence
A Tale of Two Optimizations SEO vs GEO
The operating assumptions are no longer the same
Authority now travels through citations and co-mentions
Tactical Implementation and Measurement
Share of Voice is the controlling KPI
Implementation starts with answer capsules
Tracking requires independent observation
Conclusion Reframing Brand Discovery
Visibility is now a managed system
The durable advantage belongs to engineering teams
Executive Summary The End of SEO
Conventional SEO isn't merely aging. In AI search, parts of it are directly misaligned with how answers get assembled and cited.
The old model optimized for page rank, click-through rate, and keyword ownership. The new model optimizes for retrieval, passage usefulness, and citation trust. Those are not adjacent problems. They require different content architecture, different KPIs, and different workflows.
Most advice fails at the measurement layer
The market still talks about schema, FAQs, and answer-first formatting as if those inputs alone explain performance. They don't. The unresolved issue is observability. Existing content on how to rank in ChatGPT heavily emphasizes optimization tactics but underserves measurement and tracking challenges in probabilistic AI responses, where citation sets can change across repeated runs with <1 in 100 chance of identical brand lists, according to Ahrefs’ analysis.
That means a screenshot isn't evidence. A single prompt isn't evidence. A one-time citation isn't evidence.
Practical rule: A brand has not ranked in ChatGPT until its citation pattern persists across prompts, variations, and repeated retrieval conditions.
Failure often occurs when teams borrow SEO reporting habits for a system that doesn't behave like a deterministic SERP. Consequently, they over-credit formatting tweaks and under-invest in corpus engineering.
GEO is an engineering discipline
GEO treats AI visibility as a systems problem. The brand isn't trying to win one keyword. The brand is trying to become the model's most retrievable and defensible source across a family of related prompts.
That requires four operating assumptions:
Retrieval comes first: The model can only cite what it can surface and parse.
Passages matter more than pages: The useful unit isn't the URL. It's the chunk.
Evidence beats assertion: Unsourced brand copy gives models little reason to trust the passage.
Monitoring must be repeatable: Teams need structured observation across prompts, not isolated wins.
The result is a cleaner definition of success. GEO is the discipline of increasing the probability that a model retrieves, synthesizes, and cites a brand when users ask high-intent questions.
Marketing leaders who still manage AI search as an SEO extension are measuring the wrong surface. The companies that win will build retrieval-ready corpora, not just polished webpages.
For readers starting here, Chapter 1 is the right anchor for the rest of this paper. Teams that need a working system can also book a call with Algomizer using this chapter reference and utm_source=blog1.
The Architectural Shift From Pages to Passages
ChatGPT does not evaluate the web the way traditional search engines did. It retrieves candidate material, compares relevance across variations, and assembles answers from semantically useful text units.
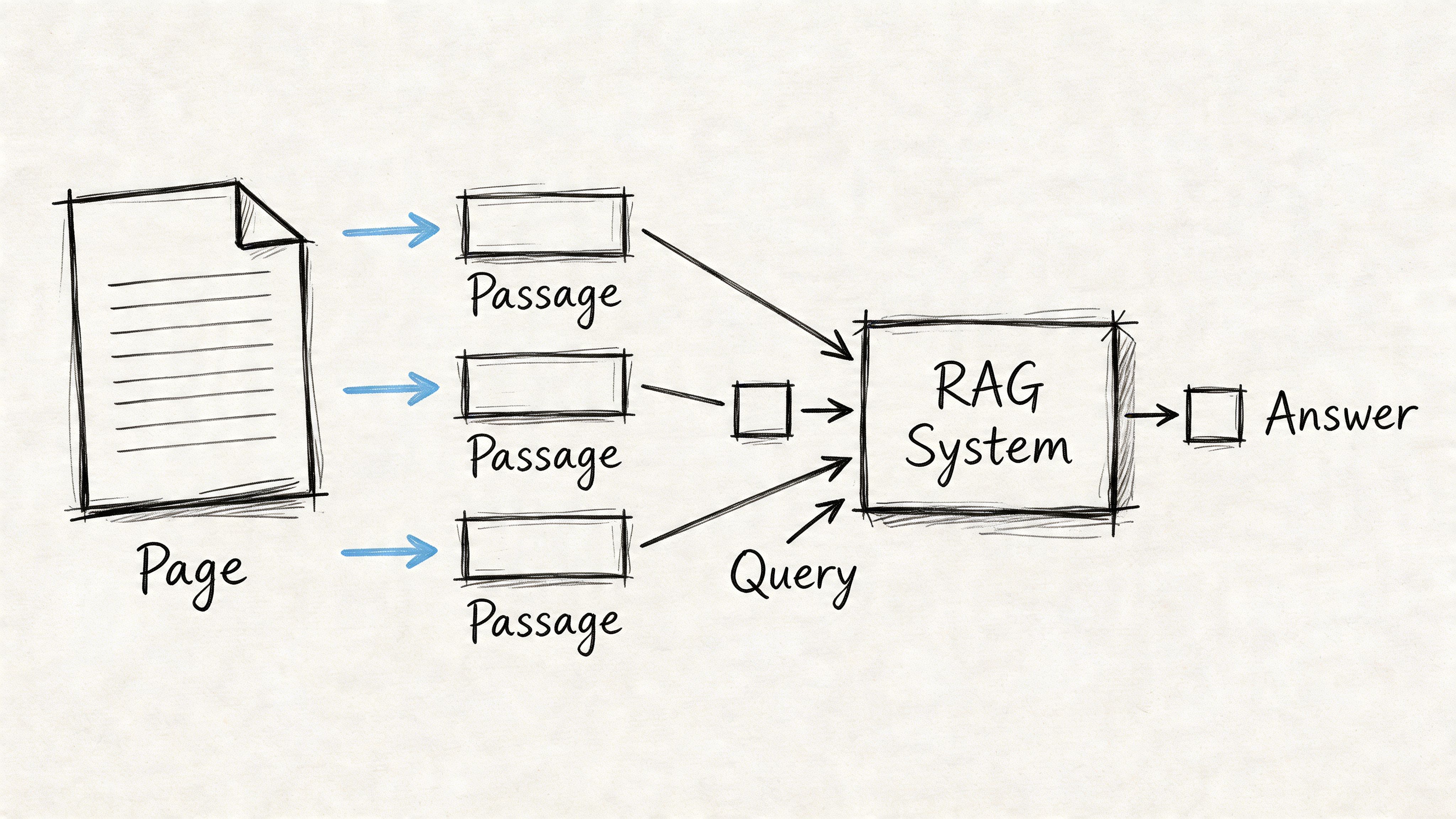
ChatGPT retrieves chunks, not brand promises
The practical unit of AI visibility is the passage. A strong homepage can still underperform if the underlying text isn't chunked into precise, evidence-bearing sections that map cleanly to user intent.
This is the architectural reason GEO exists. Retrieval-augmented systems don't need an entire page to be excellent. They need passages that resolve a question clearly enough to survive retrieval and ranking. A page can contain many passages, but only some will qualify as citation material.
That shift demands a different content build. Teams need shorter semantic blocks, explicit claims, and tightly scoped answers that can stand alone when extracted from page context. The deeper mechanics are explored in Algomizer's piece on how GEO works.
RRF rewards breadth across query variations
The ranking logic reinforces this passage-first reality. ChatGPT uses a Reciprocal Rank Fusion formula of 1 / (60 + rank position) to evaluate content across multiple search variations, according to Singularity Digital’s analysis of ChatGPT ranking.
The important implication isn't the formula by itself. It's what the formula incentivizes.
A site ranking #5 across ten related searches accumulates more influence than a site ranking #1 for just a single query under this system. The mechanism rewards topical depth across fan-out queries rather than singular keyword dominance. The web team that owns one glamorous term can lose to the quieter team that appears consistently across many related question forms.
Retrieval systems reward coverage patterns. They don't reward a brand for obsessing over one canonical phrase while neglecting adjacent use cases.
This is why legacy SEO advice breaks down inside AI answers. Traditional workflows concentrated effort around one page, one keyword, one rank target. GEO has to distribute effort across a topic network, where each passage strengthens the model's ability to retrieve the brand under a different phrasing, edge case, or comparison prompt.
The page hasn't disappeared. It has been demoted. The passage is now the operative asset.
Readers who need the strategic context should return to Chapter 1. Teams evaluating implementation paths can book a call with Algomizer and reference utm_source=blog2.
The Algomizer Framework Evidence Clusters and Semantic Density
The winning content pattern in AI search isn't verbosity. It's compression with proof. The model cites what carries enough meaning, context, and trust inside a retrievable unit.
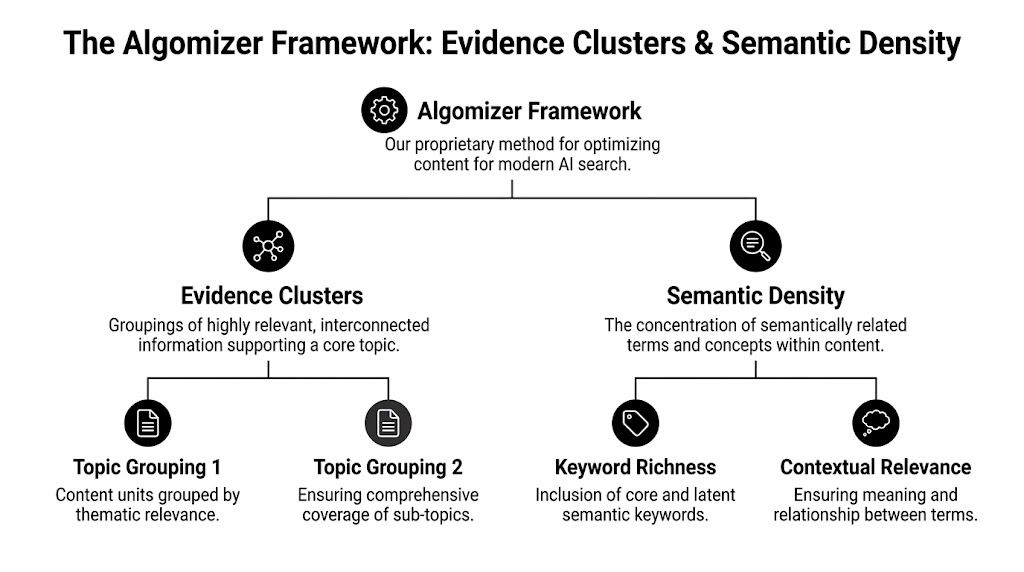
Evidence Clusters create machine-readable trust
An Evidence Cluster is a set of tightly related passages that collectively answer a decision, validate a claim, and reduce ambiguity for the model. It is not a content cluster in the old SEO sense. It is a citation architecture.
The most effective GEO methodology requires chunked passages of 100-300 tokens with high semantic relevance, supported by author bios detailing qualifications and inline sources for every claim, according to LLMrefs’ guide to ranking on ChatGPT. That same source states that brands using this structured approach see "almost certain" traffic gains when combined with 2+ external listicle mentions.
An Evidence Cluster usually includes:
A decision passage: A direct answer to a specific buyer question.
A proof passage: Supporting facts, sourced claims, or qualification context.
A comparison passage: Clear distinctions against alternatives, categories, or use cases.
A credibility passage: Author identity, expertise, and transparent sourcing signals.
This is the difference between publishable content and retrievable content. Publishable content reads well end to end. Retrievable content still works when a model pulls one passage out of context and asks, "Can this be cited safely?"
Semantic Density turns passages into citation candidates
Semantic Density is the concentration of useful meaning inside a chunk. It is not keyword stuffing. It is the disciplined packing of definitions, decision criteria, constraints, and brand-specific context into a passage that can survive extraction.
A dense passage does three things at once. It names the concept, resolves the user intent, and grounds the claim in evidence. It doesn't wander through scene-setting copy, inflated transitions, or brand theater.
A weak passage says a platform is easy to use, powerful, and flexible. A dense passage explains which team it serves, which problem it resolves, which decision criteria matter, and why the claim can be trusted.
Working standard: If a paragraph loses meaning when separated from the page, its semantic density is too low for AI retrieval.
Teams building for this environment should think like information architects. Every paragraph needs a job. Every claim needs support. Every answer needs to stand on its own.
A related discipline is emerging in monitoring as well. Mentionkit's analysis of AI scoring in brand mention monitoring is useful for teams trying to understand how references, co-mentions, and qualitative signal interpretation are evolving around LLM visibility.
External mention patterns reinforce retrieval confidence
Self-authored content rarely closes the loop on trust by itself. Models synthesize across documents, and external corroboration strengthens the chance that a passage is treated as reliable rather than merely promotional.
That is why listicles, Reddit threads, directories, comparison pages, and high-signal third-party mentions matter in GEO. They don't just build awareness. They create repeated external references that align with the same claims the brand is making on its own domain.
The technical expansion of this framework appears in Algomizer's write-up on engineering truth for GEO. The underlying principle is simple. A brand becomes citable when its claims recur across a distributed evidence environment.
Readers who want the conceptual starting point can return to Chapter 1. Teams building AI-native content systems can book a call with Algomizer and reference utm_source=blog3.
A Tale of Two Optimizations SEO vs GEO
SEO and GEO now operate as separate channels with different units of value, different outputs, and different reporting logic.
The operating assumptions are no longer the same
Traditional SEO pursued ranked pages and visitor clicks. GEO pursues cited passages and inclusion in generated answers. The overlap exists, but the center of gravity has shifted.
Dimension | Traditional SEO (2004–2024) | Generative Engine Optimization (2025+) |
|---|---|---|
Primary goal | Win clicks from ranked results | Win citations inside generated answers |
Unit of optimization | Page | Passage |
Query strategy | Target primary keywords | Cover fan-out prompts and use cases |
Core tactic | On-page optimization and link acquisition | Evidence Clusters and semantic passage engineering |
Trust signal | Page authority and backlink profile | Source trust, corroboration, and extractable proof |
Reporting focus | Rank, impressions, CTR | Citation count and Share of Voice |
Competitive frame | SERP position | Model inclusion and comparative mention frequency |
This comparison changes staffing decisions as much as content decisions. The old SEO stack favored technical auditors, link builders, and page optimizers. GEO requires content engineers, entity strategists, and measurement systems capable of observing citation behavior across models.
Authority now travels through citations and co-mentions
The authority signal has also changed shape. In AI search, the model isn't only selecting the page with the strongest historical link graph. It is selecting passages that fit the answer and survive trust evaluation.
That makes brand corroboration more important than isolated self-description. Mentions in trusted third-party environments, repeated topic association, and consistency of wording across the web all influence whether a model sees a brand as part of the answer set.
The logic behind that authority shift is explored further in Algomizer's analysis of the weight of authority in GEO. The consequence for leadership teams is immediate. Budget once reserved for broad link velocity has to move toward citation architecture, comparison content, and external brand signal design.
SEO asked whether a page deserved traffic. GEO asks whether a passage deserves to be repeated.
Readers who need the original framing can return to Chapter 1. Teams assessing organizational readiness can book a call with Algomizer and reference utm_source=blog4.
Tactical Implementation and Measurement
Execution starts when content teams stop publishing pages and start assembling citation assets. The objective is to increase retrievability, trust, and repeat citation across high-intent prompts.
Share of Voice is the controlling KPI
Share of Voice has become the primary metric for AI search visibility. A 25% SoV means that for every four citations an AI model provides across a brand's target topics, one citation points to that brand, as described in Opttab's guide to ranking in ChatGPT. That source also notes that this KPI has replaced click-through rate because AI search success depends on whether the model trusts and cites the brand.
This is the right metric because it captures competitive position, not just isolated appearance. Citation count matters, but SoV shows whether the brand is taking space from rivals across a defined topic set.
A disciplined implementation sequence looks like this:
Map buyer-intent prompts: Build prompt sets around comparisons, alternatives, implementation questions, objections, and buyer constraints.
Record citations by model: Track brand mentions across ChatGPT and other LLMs because citation preferences vary by platform.
Group prompts by topic family: Measure SoV at the cluster level, not just per prompt.
Prioritize gaps: Fix the topic families where competitors appear repeatedly and the brand does not.
Implementation starts with answer capsules
The most effective production unit is the answer capsule. This is a compact passage package designed around one question and its supporting proof.
A useful capsule usually contains:
A direct answer: One paragraph that resolves the query without filler.
Decision criteria: A short list of what matters when choosing among options.
Evidence layer: Sourced claims, author credentials, or documented methodology.
Comparison context: Why this solution fits one use case and not another.
Structured data still matters, especially when it clarifies FAQs, product attributes, and comparison logic. Conversational phrasing matters too, because prompt language is natural rather than keyword-stiff. But neither input works unless the passage itself is precise enough to retrieve cleanly.
A practical stack may include editorial workflows, schema implementation, prompt libraries, and monitoring platforms. Algomizer is one example, offering visibility tracking, prompt and topic exploration, and brand intelligence for AI-generated answers. The tool category matters because teams need independent observation rather than platform-reported impressions.
A strong visual explanation of the tactical workflow appears below.
Tracking requires independent observation
The biggest reporting mistake is trusting a single interface or API view of performance. AI outputs are probabilistic, and teams need repeated sampling, prompt variation, and cross-model comparison to distinguish a real ranking pattern from noise.
That means tracking systems should watch:
Citation count: How often the brand appears.
SoV: How much of the citation set the brand owns.
Prompt class coverage: Which buyer-intent groups trigger citations.
Competitor overlap: Which brands dominate the same prompt families.
Passage alignment: Which content fragments appear to support citation behavior.
The operational requirement is consistency. Teams should monitor the same prompt families over time, preserve prompt wording variants, and review changes after model shifts. Without that loop, progress is impossible to verify and regressions are easy to miss.
Readers who need the conceptual anchor can return to Chapter 1. Teams building an AI visibility reporting system can book a call with Algomizer and reference utm_source=blog5.
Conclusion Reframing Brand Discovery
Brand discovery in AI search is no longer a publishing problem. It is a controlled retrieval problem.
Visibility is now a managed system
The mechanics are now clear. Retrieval systems surface passages, not brand slogans. Citation behavior follows trust, corroboration, and semantic usefulness. Measurement has to account for unstable outputs, not assume a fixed ranking page.
That is why passive content programs deteriorate quickly. A data-driven AEO monitoring cycle is critical because 60% of strategies fail from unmonitored model evolution, while GEO tactics can lift citations 3x in 3 weeks and brands with multi-source mentions rank 85% more reliably, according to Crackle PR's analysis of ranking in ChatGPT.
Those numbers describe more than performance. They describe discipline. The winning teams don't publish once and wait. They deploy, observe, refine, and recalibrate.
The durable advantage belongs to engineering teams
The strategic conclusion is straightforward. The brands that treat AI visibility as a technical system will compound advantage. The brands that treat it as a copywriting variation of SEO will lose ground without understanding why.
A modern brand corpus needs passage architecture, evidence design, external corroboration, and independent measurement. Those pieces work together. Remove one, and citation reliability weakens. Maintain all of them, and the brand becomes easier for models to retrieve and safer for models to recommend.
That is the answer to how to rank in ChatGPT. Not by gaming a keyword. Not by polishing one page. By engineering a body of evidence that language models are incentivized to reuse.
Readers who want the starting point can return to Chapter 1. Teams ready to operationalize this discipline can book a call with Algomizer and reference utm_source=blog6.
Algomizer helps brands improve visibility inside AI-generated answers across ChatGPT, Claude, Gemini, Perplexity, and related platforms through content engineering, media placement, technical implementation, and independent tracking. Teams that want a factual assessment of current citation visibility can book a call with Algomizer.