Expert Guide: How to Optimize for AI Overviews
Discover how to optimize for AI Overviews with our technical guide. Engineer content & signals to be cited by LLMs like Gemini.

Subtitle: An engineering-first playbook for getting cited inside AI-generated answers, not just indexed in search.
July 15, 2026
Generative Engine Optimization 201. Chapter 1.
Executive summary
Most advice on how to optimize for ai overviews is already outdated because it treats AI search as a variant of classic SEO. It isn't. The objective has shifted from ranking a page to making a claim retrievable, groundable, and citable inside an LLM response.
That distinction matters because AI Overviews already trigger in 60.85% of informational queries containing four or more words, according to SE Ranking’s analysis of AI Overview query patterns. Complex discovery is no longer mediated primarily by ranked lists. It is mediated by synthesis.
For marketing leaders, the implication is structural. Teams must stop treating content as a page-level asset designed to win clicks and start treating it as a machine-readable evidence layer designed to survive retrieval, attribution, and compression. That is the operating logic behind GEO.
A useful starting point is Algomizer’s explanation of how GEO works, which frames the same market shift from ranking systems to recall systems. The strategic conclusion is straightforward. Visibility now depends on whether an AI system can pull a factual unit from a document, verify it against a source, and place it into an answer with confidence.
Table of Contents
The End of Ranked Lists and The Rise of GEO
Rank is no longer the primary unit of visibility
GEO changes the asset being optimized
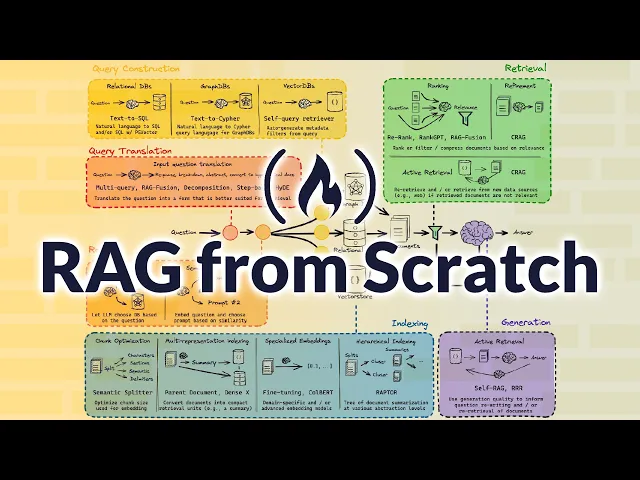
Deconstructing AI Search The RAG Architecture
Retrieval decides whether content enters the conversation
Grounding is the citation gatekeeper
Generation compresses evidence, not marketing copy
The Evidence Cluster Framework for GEO
Evidence Clusters are built for machine recall
Three components make the structure work
SEO vs GEO A Tale of Two Signals
The signal stack has changed
Tactical Execution Content Engineering and Technical Signals
Formatting changes citation probability
Technical context reduces attribution friction
From Ranking to Recall: A New Operating Model
Google is only one retrieval environment
Recall has to be measured at the answer layer
The End of Ranked Lists and The Rise of GEO
Rank is no longer the primary unit of visibility
The popular advice still says the goal is to appear higher in search results. That advice lags the interface. In AI search, the user often sees a synthesized answer first and only then encounters sources.
SE Ranking’s analysis shows that AI Overviews trigger in 60.85% of informational search queries containing four or more words in Google, which makes long, specific questions the center of the new discovery model, not the edge case of the old one. The practical meaning is simple. Discovery now happens inside generated answers for the exact category of queries that buyers use when they are clarifying a problem, comparing approaches, or validating a vendor.
Practical rule: If a brand only optimizes for where its page ranks, it misses the more important question of whether its facts are available for synthesis.
Classic SEO treated the page as the product. GEO treats the answer fragment as the product. That difference explains why many content programs still produce polished assets that fail to appear in AI outputs. They were written to satisfy a crawler and persuade a human. They were not engineered to satisfy retrieval and grounding.
GEO changes the asset being optimized
Generative Engine Optimization changes the design target from page relevance to citation eligibility. That means the content unit that matters most is no longer the page title, the primary keyword, or even the link graph in isolation. It is the factual segment that can be extracted with minimal ambiguity.
This shift creates a new mandate for CMOs and search leaders:
Optimize claims, not just pages. A page can rank and still contribute nothing to an AI summary if its language is too vague for extraction.
Build retrieval-friendly topic depth. Long-tail discovery favors content that answers complex questions with specific, bounded statements.
Treat citations as distribution. In AI search, being quoted inside the answer often matters more than being listed beneath it.
The market still calls this “search optimization,” but the mechanics are closer to knowledge packaging. Teams that continue publishing generic leadership content without discrete evidence units will remain indexable and still become invisible.
Book a call with Algomizer to assess how a brand currently appears inside AI-generated answers.
Deconstructing AI Search The RAG Architecture
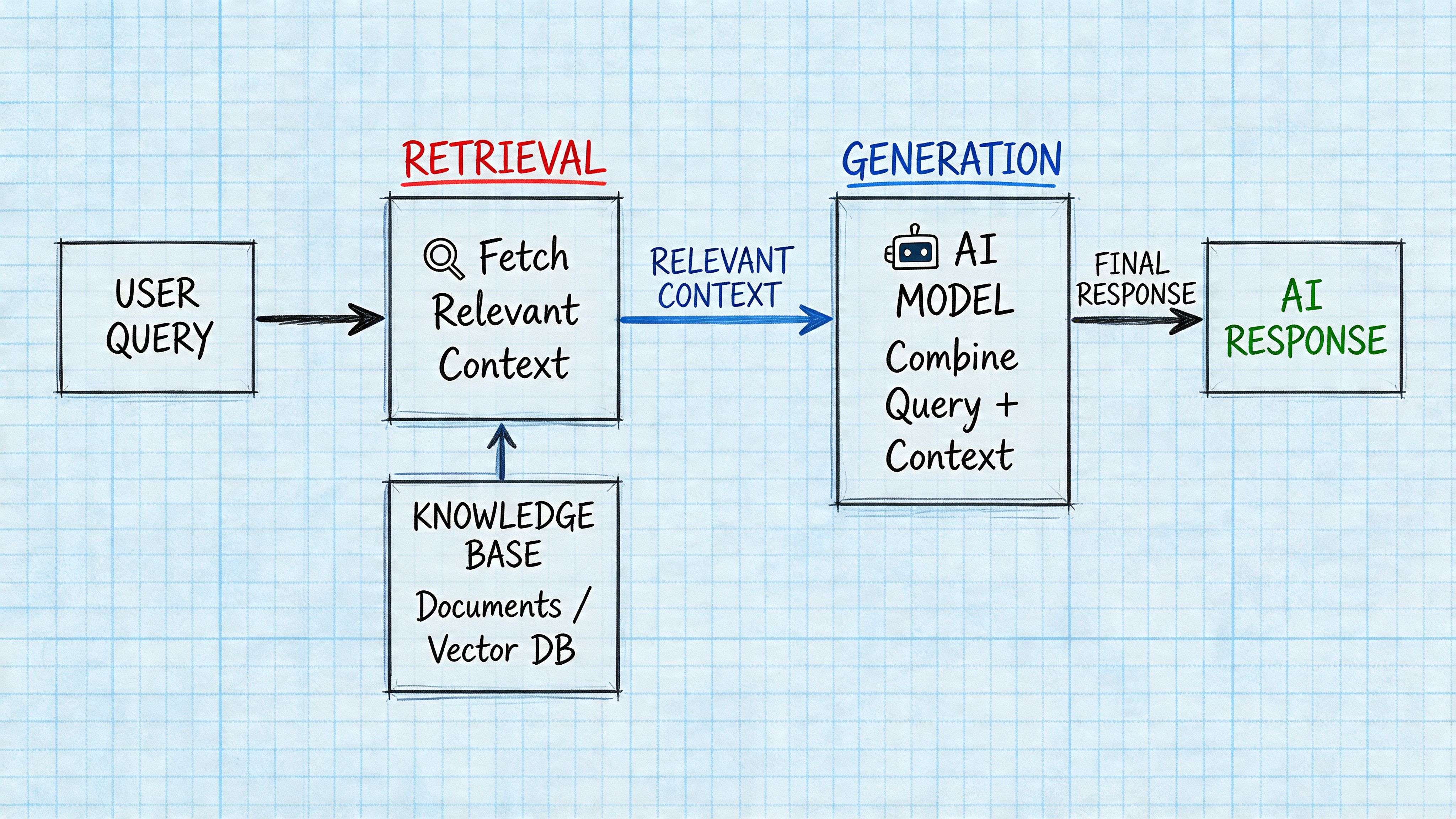
Retrieval decides whether content enters the conversation
AI Overviews are not composed from memory alone. They are assembled through a Retrieval-Augmented Generation pipeline that first identifies candidate documents, then extracts useful passages, and finally synthesizes an answer from retrieved evidence.
For marketers, the key point is operational rather than academic. Retrieval systems don't reward prose that sounds overly complex. They reward content whose meaning is easy to match to a user query and easy to isolate as a usable passage. That is why factual subheadings, direct definitions, and compact answer blocks consistently outperform diffuse brand copy.
A useful mental model is three sequential gates:
Retrieval. The system matches the query to documents and passages.
Grounding. The system checks whether the generated statement can be tied back to retrieved material.
Generation. The model compresses those grounded passages into a coherent answer.
If the content fails at gate one, it is never seen. If it fails at gate two, it is seen and discarded.
Grounding is the citation gatekeeper
Google’s Gemini model relies on a grounding mechanism, and every sentence in an AI Overview must be supported by a retrieved document, which means ambiguous or unsourced claims are filtered out before citation, as described in LinkGraph’s explanation of grounding mechanics in AI Overviews.
That single constraint explains a large share of AI visibility failure. Many enterprise pages contain claims such as “industry-leading,” “a complete platform,” or “trusted by advanced teams.” These phrases may help positioning copy, but they don't provide a system with an independently verifiable statement to ground.
The model cannot safely cite what it cannot attribute.
RAG sharply diverges from old SEO assumptions. Keyword alignment may still help retrieval, but retrieval alone doesn't secure inclusion. The sentence must also survive a second test. Can the model point to a document and justify why that line belongs in the answer?
That is why tables, bullets, named entities, and explicit source references matter so much. They lower the cost of attribution.
A visual walkthrough helps clarify how the pipeline behaves in practice:
Generation compresses evidence, not marketing copy
Once a model has retrieved and grounded evidence, it generates a final response by compressing overlapping facts into a concise synthesis. This means AI Overviews prefer high-extractability content over elegant but indirect prose.
The most reliable content shapes are the ones that reduce interpretive work:
Content shape | Retrieval effect | Grounding effect |
|---|---|---|
Question-based H2/H3 headings | Aligns closely to user phrasing | Defines clear claim boundaries |
Bullet lists | Produces extractable units | Makes sentence-level attribution easier |
Data tables | Surfaces comparable facts | Preserves structure during synthesis |
Explicit source mentions | Adds context around entities | Increases attribution clarity |
The result is mechanical, not mystical. AI search is a systems problem. Brands that understand that architecture stop asking how to sound smarter and start asking how to become easier to cite.
For readers who want the broader strategic framing, Chapter 1 connects back to the earlier argument on ranked lists and GEO. Book a call with Algomizer to evaluate where retrieval and grounding currently break down across key topics.
The Evidence Cluster Framework for GEO
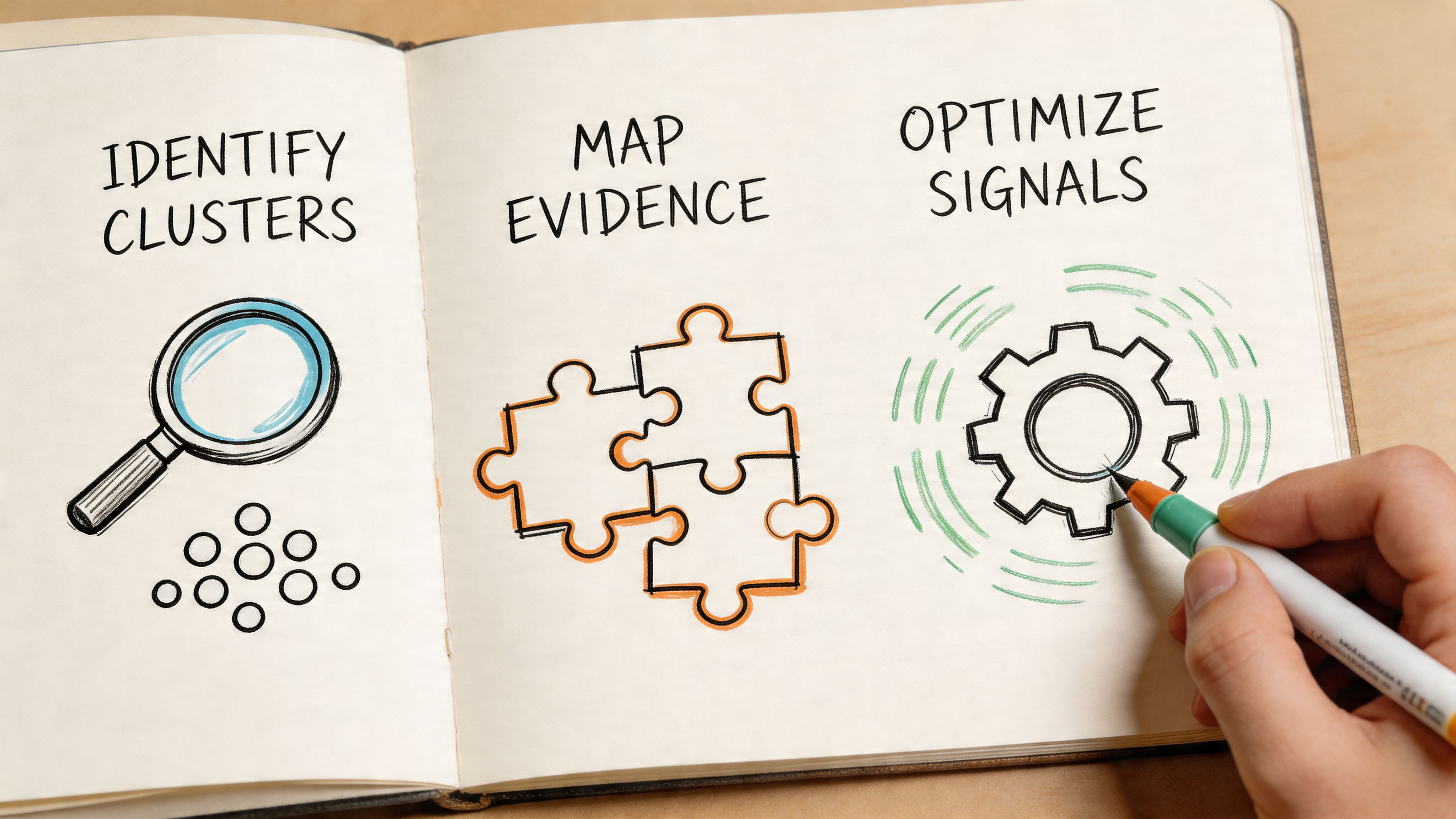
Evidence Clusters are built for machine recall
The most effective response to AI search is not “better content” in the generic sense. It is better evidence architecture. That is the logic behind the proprietary Evidence Cluster framework.
An Evidence Cluster is a content structure built around a central claim and surrounded by supporting proof in forms that RAG systems can retrieve and ground with minimal friction. It combines one broad authoritative asset with multiple narrower substantiation assets so the model has both context and proof.
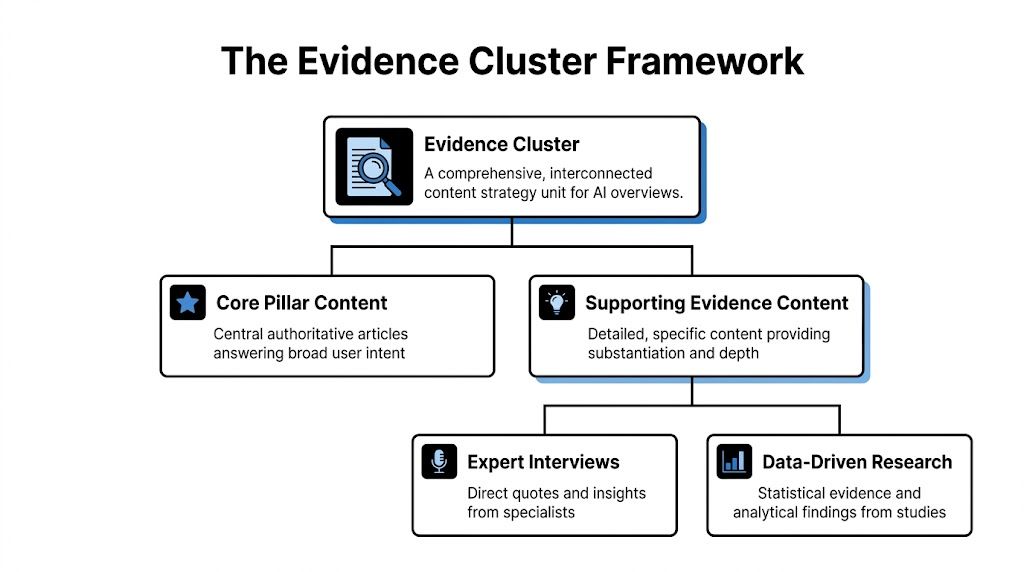
This framework matters because AI systems synthesize across documents, not within a single polished landing page alone. A brand is easier to cite when one asset defines the topic cleanly, another provides comparative detail, and another supplies attributable expertise.
Three components make the structure work
The framework has three working parts. Each serves a distinct role in retrieval and synthesis.
Answer Capsules establish the claim
An Answer Capsule is a short, direct response to a specific query, usually in the opening sentence beneath an H2 or H3. It should resolve the question immediately, then expand with context.
For example, a section on schema should begin with a statement such as: FAQPage, Person, and BreadcrumbList markup give machines explicit context about what a page says and who is saying it. That structure gives the system a stable sentence to extract.
Data Payloads carry the proof
A Data Payload is the structured evidence attached to the claim. This often appears as a table, bullet sequence, cited statistic, or clearly bounded comparison.
What matters is not ornamental design. What matters is semantic visibility. If the key comparison lives inside an image, many models can't use it as effectively as semantic HTML text. If the evidence lives in a compact table with labeled rows, extraction becomes straightforward.
Operational insight: The strongest content unit in AI search is a claim immediately followed by evidence in a machine-legible format.
Source Attributions make citation possible
A Source Attribution identifies where the fact comes from and who stands behind it. This can mean naming a study, a researcher, or a documented authority within the body copy. Attribution transforms a statement from interesting prose into a citable unit.
An Evidence Cluster usually contains these assets working together:
Core pillar content. A definitive page that frames the broad problem and names the key entities.
Expert interview content. Quotable specialist commentary that gives the system attributable language.
Data-driven research content. Structured findings that can be reused across query variants.
Supporting explainers. Narrow pages that answer one factual sub-question cleanly.
This architecture doesn't chase a single ranking event. It builds a network of corroborating passages that improve the odds of inclusion when the model assembles an answer.
For a broader introduction, the logic in Chapter 1 still applies. Book a call with Algomizer if a content team needs an evidence-layer audit across priority topics.
SEO vs GEO A Tale of Two Signals
The signal stack has changed
Traditional SEO and GEO are not competing labels for the same practice. They optimize for different outputs. SEO tries to rank pages. GEO tries to get claims cited.
That distinction changes what a team should value in audits, briefs, and reporting. A useful companion perspective appears in LucidRank’s analysis of Answer Engine Optimization vs Traditional SEO, which captures the same structural shift from link-driven visibility to answer-surface visibility.
The internal strategic implication is that authority itself must be reinterpreted. In GEO, authority is not just accumulated through mentions and backlinks. It is also expressed through how clearly a page states verifiable facts, how coherently entities are connected, and how little ambiguity remains for the model to resolve. That broader framing aligns with Algomizer’s analysis of the weight of authority in GEO.
Signal Type | Traditional SEO Focus (Ranking Pages) | GEO Focus (Getting Cited) |
|---|---|---|
Keyword targeting | Match high-value terms | Match user questions and factual intents |
Backlinks | Increase page authority | Support credibility around retrievable claims |
Content depth | Publish comprehensive pages | Publish extractable evidence across topic clusters |
On-page structure | Improve readability and relevance | Create bounded, citable answer units |
Schema markup | Help search engines interpret pages | Reduce ambiguity for retrieval and attribution |
E-E-A-T | Strengthen perceived site quality | Make expertise explicit inside the claim itself |
Measurement | Position, traffic, CTR | Citation presence, answer coverage, recall consistency |
GEO doesn't replace SEO. It changes which signals carry the final mile of visibility inside generated answers.
A team that still measures success only through rankings will miss the actual battleground. The more useful question is whether the brand's claims appear when an LLM explains the category.
Book a call with Algomizer to compare classic SEO signals against citation-focused GEO signals for a target market.
Tactical Execution Content Engineering and Technical Signals
Formatting changes citation probability
The most actionable lesson in how to optimize for ai overviews is that formatting is not cosmetic. It changes whether evidence can be extracted at all.
A Princeton study found that embedding statistics increases content inclusion likelihood in LLM outputs by 35%, while direct quotations increase it by 30%, according to Moz’s summary of GEO research and AI Overview optimization. That finding confirms what retrieval engineers already observe in practice. Verifiable elements survive synthesis better than generic commentary.
The execution standard is therefore strict:
Lead with the answer. Start each major section with a direct response in roughly one sentence.
Bind proof to the claim. Place the statistic, quote, or named source immediately after the answer, not several paragraphs later.
Use semantic lists and tables. They are easier to isolate than narrative paragraphs.
Write headings as factual prompts. A heading framed as a question often aligns more cleanly with user intent and retrieval behavior.
A practical checklist looks like this:
Rewrite H2s and H3s around user questions. “How does FAQ schema affect AI visibility” is better retrieval bait than “Schema best practices.”
Convert soft claims into hard statements. Replace “teams can benefit from” with a specific explanation tied to evidence.
Add attributable quotations. Expert commentary gives the model language it can safely reuse.
Move comparisons out of images. If a key distinction exists only in a visual, many systems won't parse it reliably.
Refresh evidence blocks. If proof becomes stale, citation likelihood declines qualitatively because the model can prefer fresher support.
For teams looking for another practical angle, LLMrefs published a concise guide on how to optimize for AI Overviews that complements this engineering-first approach.
The best-performing section on a page is often not the most persuasive. It is the one with the cleanest answer-evidence-attribution sequence.
Technical context reduces attribution friction
Technical implementation matters because it feeds machine-readable context into the retrieval stack. Structured markup, clear authorship, and crawlable navigation don't create authority by themselves, but they remove uncertainty around what a page contains.
The essential technical signals are straightforward:
FAQPage schema. Useful when the page contains discrete question-answer pairs.
Person schema. Clarifies who authored or contributed expertise.
BreadcrumbList schema. Helps define topic context and page hierarchy.
Clean internal linking. Reinforces entity relationships between pillar pages and supporting evidence assets.
This is also the right layer for tooling. Search Console can still surface indexing patterns. Headless browser workflows can show what users see inside AI interfaces. For implementation support, Algomizer’s technical framework for GEO outlines one method for operationalizing these requirements across content, markup, and monitoring. Algomizer also offers a managed service that uses headless browsers to track cross-platform visibility without relying on API access.
The takeaway is practical. Content engineering wins retrieval. Technical clarity helps that content survive grounding.
For teams ready to operationalize the stack, book a call with Algomizer.
From Ranking to Recall: A New Operating Model
Google is only one retrieval environment
The common GEO mistake is treating Google’s AI Overviews as the whole market. They are one retrieval environment among several, each with different grounding behavior, citation norms, context windows, and query rewriting patterns. Content that appears reliably in one system can disappear in another because the retrieval stack is not shared.
That changes the optimization target. A ranking model assumes one index, one results page, and one visible position. A recall model assumes multiple systems that fetch fragments, compare sources, and assemble answers from whatever evidence survives retrieval and grounding.
The practical implication is straightforward. Teams need assets built for cross-model retrieval, not pages tuned for a single interface.
Environment trait | Ranking mindset | Recall mindset |
|---|---|---|
One search engine | Optimize one SERP | Test retrieval across multiple LLMs |
One position metric | Track rank movement | Track citation presence by prompt set |
One content output | Publish one canonical page | Publish reusable evidence in multiple formats |
This is why the Evidence Cluster framework matters. It starts from the mechanics of RAG. Models do not remember brands the way humans do. They retrieve candidate passages, score them for relevance, and synthesize from the evidence that is easiest to extract, compare, and restate. Brands win inclusion when their claims exist in tightly structured, semantically consistent clusters that can be found across prompts and across platforms.
Recall has to be measured at the answer layer
Legacy SEO dashboards cannot show whether a model used your evidence in the generated answer. They can show crawling, indexing, and click behavior. They cannot show synthesis behavior inside ChatGPT, Claude, Gemini, Perplexity, or Google’s AI layer.
Direct observation is required.
Headless browser testing helps because it captures the rendered answer surface in environments where API access is limited or absent. That makes it possible to evaluate the actual unit of competition: whether a model cites, paraphrases, or excludes the brand’s evidence when answering commercially relevant prompts.
A useful operating model looks like this:
Identify prompts that trigger comparison, recommendation, or category-definition behavior.
Record which entities, claims, and source types appear in the answer.
Compare those outputs against the brand’s intended message and available evidence.
Rebuild thin or ambiguous pages into Evidence Clusters with clearer factual assertions, stronger corroboration, and tighter entity alignment.
Retest on a fixed cadence because retrieval behavior changes as models, interfaces, and prompt templates change.
The strategic change is durable. Search teams are no longer optimizing for link placement alone. They are engineering whether a model can retrieve the right facts, trust them enough to use them, and restate them accurately under synthesis pressure.
That is the standard for how to optimize for ai overviews. Rank can still matter as an upstream discovery signal, but recall determines whether the brand enters the answer at all.
Book a call with Algomizer.
Algomizer helps brands improve how they are cited, represented, and recommended across AI search surfaces such as ChatGPT, Claude, Gemini, and Perplexity. For teams that need an evidence-based GEO program rather than another SEO retrofit, book a call with Algomizer.