How to Rank in ChatGPT: An Algomizer Research Playbook
Learn how to rank in ChatGPT with our definitive playbook. We cover the AI-first strategies, proprietary frameworks, and measurement needed for LLM visibility.

Algomizer Research
April 19, 2026
Most advice on how to rank in ChatGPT is wrong because it treats AI visibility like a lighter version of SEO. It isn't. Traditional SEO optimizes pages for human clicks and search engine results pages. ChatGPT optimizes retrieval and citation around passages, semantic fit, and source trust.
That shift changes the unit of work. The page is no longer the primary object. The retrievable content chunk is. Marketing teams that still chase isolated keywords, generic backlinks, and vanity rankings are engineering for the wrong machine.
The system is retrieval-led. Large language models increasingly depend on retrieval pipelines that assemble candidate passages, compare them, rerank them, and synthesize them into a final answer. Visibility comes from being easy to retrieve, easy to trust, and easy to quote.
This paper deconstructs that mechanism and replaces vague content advice with an engineering framework built for AI recall, citation retention, and cross-model durability.
Table of Contents
Executive Summary
Deconstructing the AI Retrieval Architecture
The page lost to the passage
The Second Index is already here
The Algomizer Framework for AI Visibility
Evidence Clusters win fan-out retrieval
Semantic Density decides whether a passage survives reranking
GEO vs SEO A Fundamental Mindset Shift
The KPI changed first
Old SEO habits now create blind spots
Engineering Content for AI Recall
Answer Capsules outperform essays
Structured proof beats polished prose
Measuring What Matters Citation and Share of Voice
Rank tracking is the wrong model
Headless verification replaces prompt spot checks
Avoiding Common Pitfalls and Cross-Model Calibration
Single-model optimization fails in production
Durable visibility requires calibration not publishing volume
Executive Summary
Ranking in ChatGPT requires engineering passages for retrieval, trust, and citation, not optimizing pages for clicks. That is the operative shift behind modern Generative Engine Optimization, or GEO.
ChatGPT and similar systems don't behave like conventional search engines. They retrieve semantically related passages, fuse candidates across multiple internal searches, rerank those candidates, and then generate an answer from the surviving evidence. The implication is severe for content strategy. Most brand content is still written to persuade humans after a click. AI systems need content that can be extracted before the click ever happens.
That means the practical target is machine recall. If a model can't isolate a clean answer, verify the underlying claim, and place that passage into a broader topical frame, the brand disappears from the answer layer. A polished article can still lose if its evidence is diffuse, its structure is weak, or its authority is unverifiable.
The market has focused too narrowly on visible formatting cues such as FAQs, schema, and short answers. Those matter, but they are not the system. The system is the interaction between retrieval architecture, evidence quality, source authority, and repeated relevance across related query variants. The winning asset isn't merely optimized content. It's a content object engineered to survive fan-out retrieval and synthesis.
Research conclusion: The brand that gets cited is rarely the brand with the prettiest article. It's the brand with the cleanest retrievable proof.
This paper introduces a full-stack methodology for that environment. It frames AI visibility through Evidence Clusters, which consolidate verifiable facts into retrievable blocks, and Semantic Density, which increases the amount of machine-usable meaning per passage. Together, those concepts create a repeatable operating model for getting cited, measuring citation share, and retaining visibility when models change.
Marketing leaders don't need another checklist for "AI-friendly content." They need a system for making their brand mathematically easier for models to recall.
Deconstructing the AI Retrieval Architecture
ChatGPT ranks passages, not pages, so retrieval architecture now determines visibility before copy quality ever enters the process.
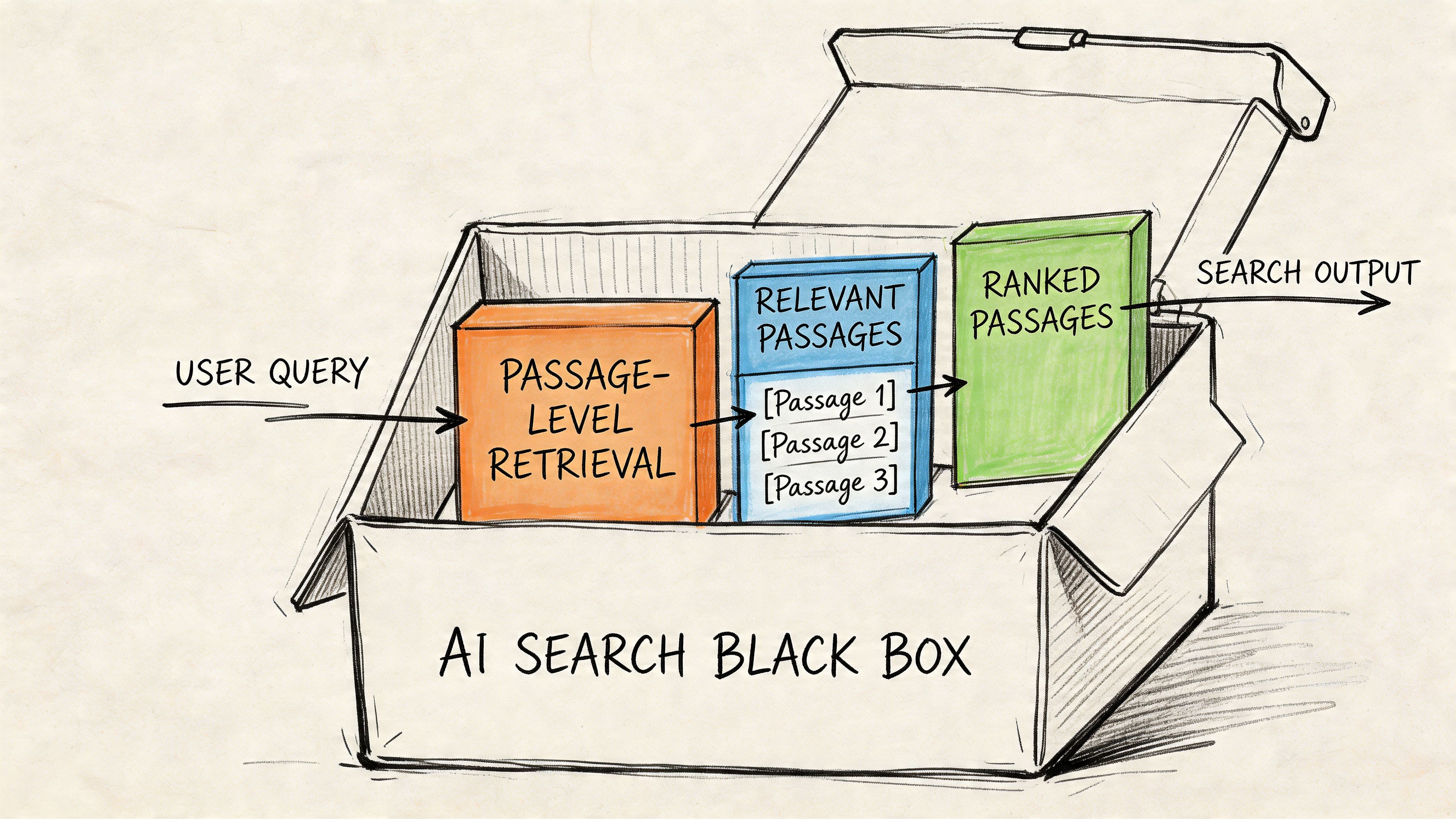
The page lost to the passage
AI systems like ChatGPT operate differently from traditional search engines because they use dense vector embeddings to retrieve semantically similar content chunks rather than keyword matching. That changes the optimization target from document-level relevance to passage-level authority, with implementation tied to schema such as Article and FAQPage and verified crawler access for GPTBot, as documented by Go Fish Digital's analysis of SearchGPT retrieval.
This is the first major misunderstanding in most content programs. Teams still build one broad page per keyword theme and assume the page's aggregate authority will carry the answer. In AI retrieval, the model often evaluates smaller chunks inside that page. If the specific passage doesn't stand on its own, the surrounding page strength won't rescue it.
That is why retrieval-first systems are best understood through the mechanics of Retrieval Augmented Generation. RAG systems don't "remember" a brand the way a human analyst does. They pull candidate evidence, compare semantic fit, and compose an answer from the pieces they trust enough to use.
A passage that cannot survive extraction cannot win citation.
The Second Index is already here
A useful operating metaphor is the Second Index. Traditional search builds a visible index of pages. LLMs build a parallel semantic index of passages, entities, and claims. This second layer doesn't care much about keyword placement in the old sense. It cares whether a chunk maps cleanly to the latent meaning of the prompt and its related sub-prompts.
That process is rarely limited to the literal query. AI systems often expand the question into adjacent intents, comparisons, use cases, and entity checks. A CMO asking for "best CRM for SaaS onboarding" may trigger hidden retrieval around implementation complexity, pricing model, integrations, and B2B fit. A single page must therefore support multiple retrievable interpretations without becoming vague.
Three technical properties decide whether content survives this layer:
Semantic coherence: Each section must answer one tight idea cleanly enough to stand alone.
Structural visibility: Headings, lists, tables, and schema make it easier for retrieval systems to isolate the exact block.
Access integrity: Clean HTML and crawler accessibility determine whether the model can ingest the page at all.
The common failure mode is publishing long articles that read well to humans but collapse under segmentation. The fix is engineering passages as independent answer units, then stitching them into a larger page architecture.
For teams building that layer deliberately, Algomizer's technical framework for GEO is a useful reference point because it treats citation as an output of retrievable evidence design rather than editorial style.
The Algomizer Framework for AI Visibility
AI visibility is won by increasing retrievable proof across related queries, not by polishing a single page until it ranks once.
Evidence Clusters win fan-out retrieval
The central unit in this framework is the Evidence Cluster. An Evidence Cluster is a tightly grouped block of claims, qualifiers, examples, and source-verifiable facts organized around one decision question. It is not a paragraph. It is a retrieval object.
That structure matters because ChatGPT uses Reciprocal Rank Fusion with the formula 1 / (60 + rank position) to combine results across multiple internal fan-out queries, according to Singularity Digital's analysis of ChatGPT ranking mechanics. The same analysis shows that mid-tier rankings across 10+ related queries can outperform a single #1 ranking by up to 10x in cumulative score. That overturns the old SEO instinct to obsess over one head term.
The implication is straightforward. A SaaS brand shouldn't ask whether one article ranks for one phrase. It should ask whether its evidence appears repeatedly across the hidden query family surrounding the commercial topic.
An Evidence Cluster is built to do exactly that:
Core claim: A direct answer expressed in one sentence.
Proof layer: Specific facts, decision criteria, ranges, or conditions.
Entity framing: Clear identification of product, category, or use case.
Extraction format: Bullets, tables, short subsections, and FAQ-compatible structure.
A tool directory such as Airankpilot can help teams discover how AI visibility products frame these workflows, but the core principle is architectural rather than tool-specific.
Semantic Density decides whether a passage survives reranking
The second component is Semantic Density. This is the amount of machine-usable meaning inside a passage relative to its length. High-density passages do not ramble. They deliver answer, qualifier, and evidence in compressed form.
Low-density writing is one of the main reasons good brands disappear from ChatGPT. The article may contain the right ideas somewhere, but the model has to work too hard to isolate them. Dense passages reduce ambiguity and increase the odds that the reranker keeps the block in play.
Operating rule: If a paragraph can lose half its words without losing any meaning, it probably isn't dense enough for AI retrieval.
This framework rejects creative-led content production as the primary engine of AI visibility. Editorial craft still matters. But the governing discipline is systems design. The content team must engineer repeatable evidence units that can surface across many semantically adjacent prompts.
GEO vs SEO A Fundamental Mindset Shift
GEO replaces page ranking with citation capture, so the strategic model has to change before tactics can improve.
The KPI changed first
Those trying to learn how to rank in ChatGPT still use SEO language to diagnose an AI visibility problem. That creates false confidence. They look at keyword positions, organic traffic, and generic authority metrics while the actual answer layer is choosing sources through a different mechanism.
The cleaner lens is a side-by-side contrast.
Factor | Traditional SEO (Obsolete) | Generative Engine Optimization (Required) |
|---|---|---|
Primary unit | Page | Passage |
Retrieval logic | Keyword and document signals | Semantic relevance and answer extraction |
Main goal | Click acquisition | Citation inclusion |
Core authority signal | Broad domain strength | Passage-level trust and verifiable evidence |
Success pattern | Rank high for one query | Appear across related fan-out queries |
Reporting habit | Position tracking | Citation Count and Share of Voice |
Content style | Intro-heavy, narrative-led | Answer-first, evidence-led |
Off-site strategy | Backlink accumulation | Trusted third-party mention and verification |
Technical focus | Indexation and page optimization | Schema, clean HTML, crawler access, extractable structure |
The mental model has already shifted. The tactical model usually hasn't.
Old SEO habits now create blind spots
Three inherited SEO behaviors regularly suppress AI visibility.
Keyword-first briefs: These push writers toward phrasing targets instead of retrievable meaning.
Page-level reporting: This hides whether the model is citing a brand's best passages or ignoring them.
Link-led authority assumptions: These miss the role of source verification and extractable proof inside the answer layer.
A useful way to interpret this shift is through Algomizer's explanation of how GEO works, which maps visibility to how models recall and synthesize sources rather than how users browse result pages.
SEO asked, "Can the page rank?" GEO asks, "Can the model trust and reuse this passage?"
That distinction sounds subtle. It isn't. It changes content planning, technical implementation, measurement, and PR priorities all at once.
Engineering Content for AI Recall
LLM citation behavior is shaped less by prose quality than by retrieval geometry. The model needs a passage it can extract, verify, and reuse with minimal transformation. Content engineered for recall therefore prioritizes answer accessibility, entity clarity, and evidence proximity inside the first retrievable block.
Answer Capsules outperform essays
Our team refers to that retrievable unit as an Answer Capsule. It is a compact passage built for extraction. The capsule resolves the query immediately, identifies the entity in plain language, and attaches supporting proof close enough that the model does not need to infer what supports what.
This is a different writing specification from conventional blog content. Narrative setup, scene-setting intros, and long opinionated transitions often dilute retrieval value because they force the model to compress before it can cite. High-recall content does the opposite. It reduces compression work.
A usable Answer Capsule usually follows four rules:
Resolve the query in the first sentence: The opening line should stand alone if lifted into an answer.
State the entity explicitly: Name the company, product, method, or category without pronoun dependence.
Attach verifiable proof nearby: Use original data, constraints, examples, or attributable claims close to the statement they support.
Format for extraction: Headings, bullets, tables, and FAQs create cleaner retrieval boundaries than dense narrative paragraphs.
Our internal concepts of Evidence Clusters and Semantic Density are important. An Evidence Cluster is a set of tightly related claims, examples, and validations arranged so the model can retrieve them as one coherent unit. Semantic Density measures how much query-relevant meaning exists per passage without adding filler. Pages that score well on both dimensions tend to survive fan-out prompting better because they remain quotable across adjacent query variants, not just the head term.
Structured proof beats polished prose
Polished writing helps humans finish an article. Structured proof helps models cite it.
A strong page gives the model clear decision logic, explicit boundaries, and machine-readable context. That includes schema markup, but the larger issue is passage design. If a claim appears in one paragraph and the qualifying condition appears three sections later, recall quality drops. If the page mixes product messaging into the same block as factual assertions, attribution gets weaker. The model prefers content it can separate cleanly into claim, support, and source identity.
For teams building repeatable AI visibility, the practical standard looks like this:
Schema support: Use
Article,FAQPage, andHowTowhere relevant.Decision logic: Include ranges, exclusions, prerequisites, and if/then conditions.
Evidence concentration: Place original observations, examples, or source-backed claims close together.
Source identity: Make authorship, brand ownership, and topical authority explicit.
Extractable comparisons: Use tables when the user is evaluating options or tradeoffs.
The authority layer also affects recall quality. Our analysis of how authority weight functions in GEO systems shows that models reuse passages more reliably when expertise signals and evidence structure reinforce each other inside the same retrieval window.
The video below shows the wider content-engineering mindset behind this shift.
A concise production checklist keeps this operational:
Front-load the answer: Put the highest-value statement before context.
Use self-contained passages: Limit pronouns and references that depend on earlier sections.
Separate fact from promotion: Keep commercial language out of evidentiary blocks.
Use comparison tables for choice queries: Aligned rows are easier for models to reuse accurately.
Refresh decaying proof: Old screenshots, stale metrics, and unsupported claims reduce citation durability.
One vendor in this category is Algomizer, which offers visibility tracking, prompt discovery, and calibration for AI-generated answer environments. The larger point is methodological. Brands do not improve LLM recall by publishing more content. They improve it by engineering higher-density evidence units that multiple models can quote without reconstruction.
Measuring What Matters Citation and Share of Voice
AI visibility can't be managed through rank tracking because the answer layer is probabilistic, citation-based, and cross-model by nature.

Rank tracking is the wrong model
The correct primary KPI is Citation Count, and the secondary KPI is Share of Voice, defined as a brand's percentage of all citations across a tracked query set. Success requires monitoring 20-30 core queries weekly and using independent verification through headless browsers rather than API-dependent tracking, as outlined by LLMrefs in its ChatGPT ranking guide.
That reframes the reporting stack. The question is no longer "Where does the page rank?" It is "How often does the brand get cited, for which prompts, and against which competitors?" Citation Count measures inclusion. Share of Voice measures competitive control of the answer layer.
A practical operating dashboard should include:
KPI | What it answers | Why it matters |
|---|---|---|
Citation Count | How often the domain is cited | Measures raw visibility in answers |
Share of Voice | How much of the citation set belongs to the brand | Reveals topic-level competitive position |
Query coverage | Which prompts trigger citations | Identifies missing use cases and topic gaps |
Source type mix | Whether citations come from owned or third-party sources | Shows trust distribution |
Headless verification replaces prompt spot checks
Manual prompting is seductive because it's easy. It is also unreliable. A marketer can ask the same question twice and mistake a passing mention for durable visibility.
Headless browser testing is more defensible because it observes actual answer outputs across repeated prompts and platforms. That makes it possible to compare prompt families, test retention over time, and verify changes independently of API constraints.
For teams building governance around this channel, the role of authority in GEO provides a useful lens for interpreting why some brands retain citations while others flash briefly and vanish.
Measurement rule: If the result can't be reproduced across a tracked prompt set, it isn't a performance signal. It's an anecdote.
The operational consequence is important. AI visibility isn't a launch metric. It is a monitored system.
Avoiding Common Pitfalls and Cross-Model Calibration
Brands lose AI visibility when they optimize for ChatGPT alone because each model retrieves, prioritizes, and refreshes evidence differently.
Single-model optimization fails in production
The most expensive mistake in this market is treating ChatGPT as the whole category. It isn't. It is one answer interface with one retrieval profile.
Practitioners on Reddit report 40-60% visibility drops when optimizing solely for ChatGPT, and the reported reason is model divergence in query fan-out and data priorities, including Perplexity's heavier focus on real-time web data versus ChatGPT's greater reliance on training data, according to Wellows' review of ChatGPT ranking tactics.
That is the point most playbooks miss. A passage that performs in ChatGPT may underperform in Claude if sourcing feels promotional. A text-heavy asset may underperform in Gemini if the surrounding ecosystem lacks strong video signals. A stale page may disappear from Perplexity if fresher third-party material enters the comparison set.
The practical symptoms are familiar:
Unstable citations: A brand appears in one model and vanishes in another.
False positives from internal testing: Teams celebrate a mention that doesn't survive broader prompt variation.
Content drift: Writers keep shipping more articles while the actual issue is calibration failure.
Authority imbalance: Competitors dominate through third-party references while the brand overinvests in owned content.
Durable visibility requires calibration not publishing volume
The durable strategy is unified but not uniform. The same core evidence should support multiple LLMs, but the packaging, freshness, media mix, and off-site support need calibration.
A disciplined operating model usually includes:
Shared entity foundation
Brand facts, product definitions, and category language must remain consistent across site copy, schema, and third-party mentions.Model-aware formatting
ChatGPT often rewards clean extraction structure. Other systems may weigh recency, reasoning style, or media format differently.Third-party reinforcement
Earned mentions in trusted publications help stabilize authority signals across models.Continuous verification
Teams need recurring prompt sets, competitor benchmarks, and retention checks instead of one-off audits.
This is why GEO has to be treated as an engineering discipline rather than a content campaign. Publishing volume alone won't solve retrieval mismatch. More pages often amplify the wrong patterns if the underlying evidence architecture remains weak.
The strongest brands in AI search aren't just "doing content well." They are controlling retrieval inputs, authority signals, and measurement loops across the answer ecosystem. That is the actual standard for learning how to rank in ChatGPT and retain that visibility when the wider model environment shifts.
Brands that need a measurable system for AI visibility can work with Algomizer to assess current citation coverage, identify retrieval gaps, and implement ongoing GEO calibration across ChatGPT, Claude, Gemini, and Perplexity. Book a call to review prompt coverage, authority signals, and citation share trends with a team built for answer-engine performance.