LLM SEO Agency: Unlock AI Search Visibility
Hire the right LLM SEO agency. Our guide defines GEO, compares tactics to SEO, & provides a C-suite checklist for AI search visibility.

Subtitle: Engineering Citable Truth in the Generative Era
Date: April 23, 2026
Chapter 2
Traditional SEO advice still tells executives to publish more pages, build more links, and defend rank positions. That advice is already obsolete. Search no longer rewards the brand that merely owns an indexed page. It rewards the brand whose claims can be retrieved, synthesized, and cited inside AI-generated answers.
That shift is why the modern llm seo agency isn't a content vendor. It is an architectural partner. Its job is to help a brand move from page-level visibility to answer-level inclusion.
For enterprise teams, the implications are immediate. The old model optimized documents for search engines. The new model engineers retrievable facts for language models. That change sounds semantic. It isn't. It changes budgets, metrics, workflows, and who should lead the function.
Table of Contents
An Executive Summary on The End of Search As We Know It
Why LLM Search Is Not Traditional Search
PageRank retrieves documents, RAG assembles answers
The unit of competition is no longer the page
Comparing Agency Models and Mandates
The mandate has changed from ranking to representation
A procurement team should compare operating models, not taglines
How We Engineer Citable Truth for AI Models
Evidence Clusters create retrievable proof
Semantic Density determines what survives compression
Technical implementation controls citation eligibility
The New KPIs for AI-Driven Discovery
Legacy metrics miss the actual outcome
Verifiable attribution is the new baseline
An Evaluation Framework for Your Next Agency Partner
Internal readiness comes before external strategy
The right questions expose weak agency models quickly
A practical engagement cadence
Why Your Next Head of Search May Be an Engineer
An Executive Summary on The End of Search As We Know It
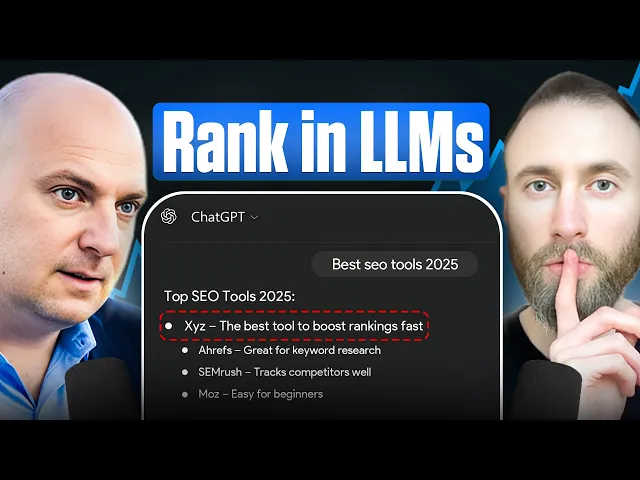
Executive summary. Search still exists, but the unit of competition has changed from the page to the retrievable claim. Brands now win by becoming citable inside generated answers.
The old SEO model assumed visibility was earned at the document level. That assumption is breaking. 58.5% of Google searches now end without clicks, and AI Overviews reduce organic click-through rates by 61% on affected queries, according to AI SEO statistics compiled by Limelight Digital. Separately, Adobe reported that traffic from generative AI sources to U.S. retail sites increased by 1,300% during the 2024 holiday season compared with the prior year, based on analysis of more than 1 trillion visits to U.S. retail sites in its Adobe holiday shopping report. The implication is direct. Discovery is shifting from ranked-page selection to answer-layer inclusion.
That shift changes what an executive team should measure.
A strong domain no longer guarantees influence inside AI-mediated discovery. Large language models do not treat a website as a single authority object. They break the web into passages, entities, claims, and corroborating signals, then assemble responses from the pieces they can retrieve and trust. At Algomizer, we see the same pattern across LLM environments. Brands with conventional SEO strength still lose answer-share when their facts are diffuse, weakly attributed, or structurally difficult to retrieve.
This creates an authority paradox. A company can hold rankings and still disappear from the decision surface if the model cites a competitor's evidence instead of the company's source material.
Practical rule: If a brand appears in results but not in the answer layer, the brand is visible to the index and invisible to the synthesis engine.
That is why executive teams are shifting from SEO vocabulary toward Generative Engine Optimization (GEO). The term is useful because it describes the actual operating problem. The work is not limited to optimizing pages for crawlers. The work is engineering citable truth for retrieval systems that rank evidence before they generate language.
The service market is adjusting to that architecture. Grand View Research projects the global generative AI market will grow from $66.89 billion in 2024 to $109.37 billion in 2025, according to its generative AI market analysis. That spending does not prove every vendor can deliver results. It does show that buyers understand the stack has changed.
An llm seo agency exists because search now runs through retrieval, synthesis, and citation. The operating mandate is different. Teams need content structured as evidence clusters, claims written with enough semantic density to survive compression, and technical deployment that makes those claims retrievable across systems such as ChatGPT and Google AI Overviews. Pages remain the publishing format. For AI systems, the primary object of competition is the chunk.
Why LLM Search Is Not Traditional Search
LLM search doesn't ask which page ranks highest. It asks which fragments, entities, and claims can be assembled into the most useful answer.
Traditional search and AI search solve different problems. Google's historical model has been document retrieval. The model identifies relevant pages, orders them, and lets the user decide. LLM-based search uses answer synthesis. It retrieves evidence, compresses it, and returns a composed response.
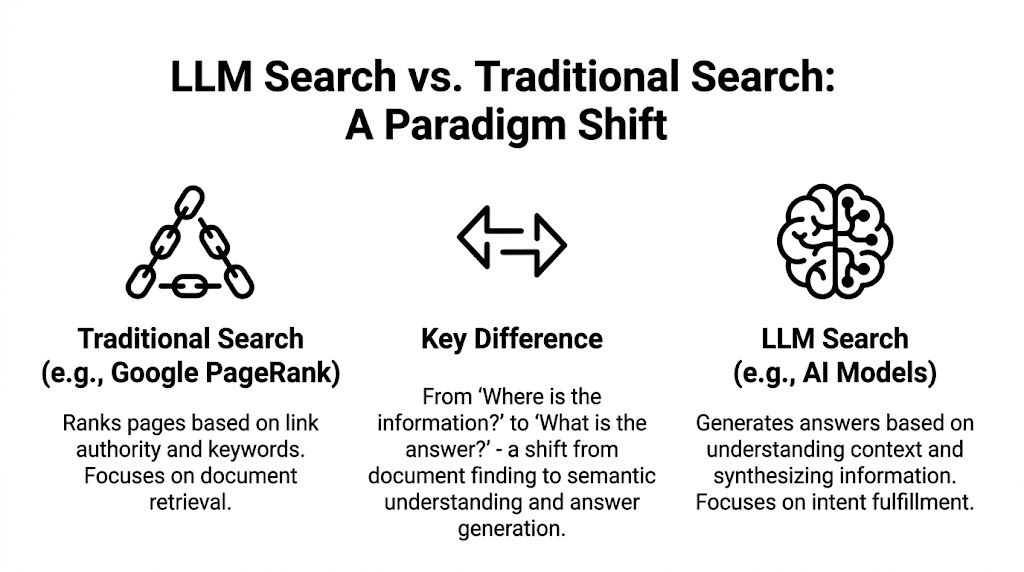
PageRank retrieves documents, RAG assembles answers
The cleanest analogy is operational. PageRank behaves like a librarian organizing books by authority, topic, and popularity. Retrieval-augmented generation behaves like an engineer pulling passages from several books, comparing them, and writing a fresh brief.
That distinction matters because user behavior is already shifting to the second system. By 2026, 37% of consumers globally are projected to start searches with LLMs like ChatGPT or Perplexity, and 38% already use AI regularly for online searching, according to Search Logistics' AI SEO statistics.
An executive team should read that change as a demand-side signal. Buyers are no longer asking only, "Which site should I visit?" They are asking, "Which answer should I trust?"
The unit of competition is no longer the page
The page still matters, but it is no longer the primary unit of competition. The winning asset is the retrievable content chunk. That chunk might be a definition, comparison, procedural sequence, product attribute, legal explanation, or pricing qualifier. If the model can isolate it, validate it, and reuse it, the brand can influence the response. If it can't, the page may remain invisible despite being technically indexed.
This is the practical foundation of GEO. It is also why many teams are studying resources such as Mastering SEO for LLM to understand the shift from keyword matching to model-readable structure.
The strategic question has changed from "How do we rank this page?" to "How do we make this fact retrievable, compressible, and worth citing?"
Three architectural consequences follow:
Content must be chunkable. Dense paragraphs and vague claims are harder for models to extract cleanly.
Entities must be explicit. Brands, products, categories, and relationships need unambiguous naming.
Evidence must be corroborated. Models prefer patterns they can verify across multiple sources and formats.
A traditional SEO agency can still improve crawlability and rankings. An llm seo agency works on a different plane. It studies how answer engines retrieve and synthesize knowledge, then restructures a brand's information so it survives that process.
Comparing Agency Models and Mandates
The difference isn't branding. It's mandate. A traditional SEO agency tries to increase page visibility. An llm seo agency tries to increase answer inclusion.
Most procurement errors happen because buyers compare agencies by deliverables instead of by operating model. Both firms may promise visibility, content strategy, and reporting. Only one is built for AI-mediated discovery.
The mandate has changed from ranking to representation
In legacy SEO, the agency's work ends when pages rank and traffic arrives. In AI search, the harder problem begins after retrieval. The model has to choose which facts to keep, which sources to trust, and which brands to mention.
That means the modern agency mandate is representation management inside generative systems. For teams evaluating an AI SEO company, the right comparison isn't "Who writes better content?" It is "Who can shape how models interpret and cite the brand?"
A procurement team should compare operating models, not taglines
Criterion | Traditional SEO Agency | LLM SEO Agency (GEO) |
|---|---|---|
Core objective | Rank pages in search results | Earn citations and mentions inside generated answers |
Primary unit of optimization | URL, keyword cluster, backlink profile | Content chunk, entity relationship, evidence set |
Success metrics | Rankings, sessions, click-through from SERPs | AI Share of Voice, citation frequency, citation quality, prompt-level visibility |
Tactical focus | Keyword mapping, on-page SEO, link building | Prompt research, evidence engineering, schema deployment, crawler access, answer formatting |
Technology stack | Search console data, rank trackers, backlink tools | Headless browser monitoring, multi-model testing, citation logging, prompt libraries |
Reporting logic | Position changes and organic traffic trends | Cross-platform answer capture and verifiable mention tracking |
Content strategy | Publish more optimized pages | Structure facts so models can retrieve and reuse them |
Risk if executed poorly | Rankings stagnate | Brand is omitted, misrepresented, or cited inconsistently |
This comparison exposes a practical budget question. A company can retain a conventional SEO agency and still be structurally absent from AI answers. The two engagements solve adjacent but different problems.
Procurement teams should ask whether the agency is optimizing a library of pages or an answer-generation environment. The tooling, staffing, and KPIs won't look the same.
The best buyers also examine what each agency cannot do. Traditional firms often lack prompt discovery workflows, citation auditing, and model-specific testing. Many GEO-focused firms, on the other hand, may underinvest in classic technical hygiene. The right partner depends on the actual mandate, not on who uses newer language in the pitch.
For a C-suite leader, that distinction changes resource allocation. A brand that treats AI discovery as a sidecar to old SEO will underfund the function that now shapes recommendation, recall, and comparative framing.
How We Engineer Citable Truth for AI Models
AI visibility is produced by retrieval architecture. An answer model cites what it can resolve, compress, and restate with low risk of distortion.
Our work as an llm seo agency starts from a different premise than legacy SEO. Indexed pages are no longer the unit of value. Retrievable content chunks are. Models do not reward page count or stylistic polish on their own. They reward claims that survive parsing, chunking, ranking, and synthesis.
We engineer for that pipeline.
The operational objective is to turn brand assertions into citable truth. In practice, that means building content systems with enough internal consistency, entity clarity, and corroborating structure that a model can reuse the claim without rewriting its meaning. We organize that work through two frameworks: Evidence Clusters and Semantic Density.
Evidence Clusters create retrievable proof
An Evidence Cluster is a set of assets that expresses one business-critical fact across the formats models retrieve. That set can include a core commercial page, supporting FAQs, structured data, documentation, comparison copy, and third-party references where they already exist. The design principle is corroboration across surfaces, not repetition for its own sake.
Answer engines rarely consume a page as a human does. They ingest fragments, score them against a prompt, and assemble a response from the fragments that appear most supportable. A single claim buried in broad marketing copy is easy to miss. The same claim stated clearly in headings, body copy, schema, and adjacent support content is easier to retrieve and safer to cite.
Analysts should read this as an architecture problem, not a writing problem. Well-structured schema markup helps models resolve entities and page purpose. Prompt research helps teams identify the exact comparative, definitional, and recommendation queries that trigger retrieval. For a technical explanation of how these systems are built, see our framework for engineering truth in GEO.
Semantic Density determines what survives compression
Semantic Density measures how much verifiable meaning a passage carries relative to its length. We use it to evaluate whether a section gives a model enough material to quote, paraphrase, or cite after compression.
High-density passages usually contain explicit entities, direct claims, constrained qualifiers, and relationships that can be checked elsewhere on the site or against external context. Low-density passages rely on abstraction, broad adjectives, and brand language that signals positioning but carries little evidentiary value.
That distinction shapes citation outcomes. LLMs compress aggressively. During compression, decorative phrasing drops out first. Specific facts tend to remain.
A high-density block often includes:
Named entities. Product names, buyer segments, geographies, platforms, and standards.
Resolvable claims. Statements tied to visible page elements, structured data, documentation, or supporting references.
Answer-shaped formatting. Definitions, comparisons, tables, short lists, and headings that match real query intent.
Tight qualification. Clear limits, conditions, and scope that reduce ambiguity during synthesis.
Later in the workflow, teams often use process explainers like the one below to align technical and editorial execution.
Technical implementation controls citation eligibility
Strong editorial logic fails if the site exposes the wrong signals to crawlers and answer systems. Citation performance depends on implementation details that many conventional SEO programs still treat as secondary.
A working GEO stack usually includes:
Schema deployment. FAQ, HowTo, Article, Product, and organization markup in JSON-LD where the page supports those structures.
Crawler access rules. Directives that permit relevant AI agents to reach pages intended for retrieval.
Prompt mapping. Research into the comparison, category, and problem-framing prompts buyers use.
Cross-model validation. Testing across ChatGPT, Claude, Gemini, and Perplexity because retrieval and citation behavior differ by model.
Tooling sits underneath that process. The market now includes headless browser monitoring, prompt tracking environments, and managed services such as Algomizer, which provides AI visibility assessments, technical implementation, and cross-platform tracking for generative search workflows.
The core conclusion is straightforward. Brands do not get cited because they published more. They get cited when their claims are engineered as machine-legible, evidence-backed units that models can retrieve and reuse with confidence.
The New KPIs for AI-Driven Discovery
Legacy SEO metrics can report improvement while AI visibility declines. The right KPI system measures whether the brand appears in answers, not just in indexes.
The biggest reporting error in this category is still overreliance on rank, sessions, and conventional click-through analysis. Those numbers retain value, but they no longer capture the full commercial surface. A board presentation built on rankings alone can miss the channel where recommendation is happening.
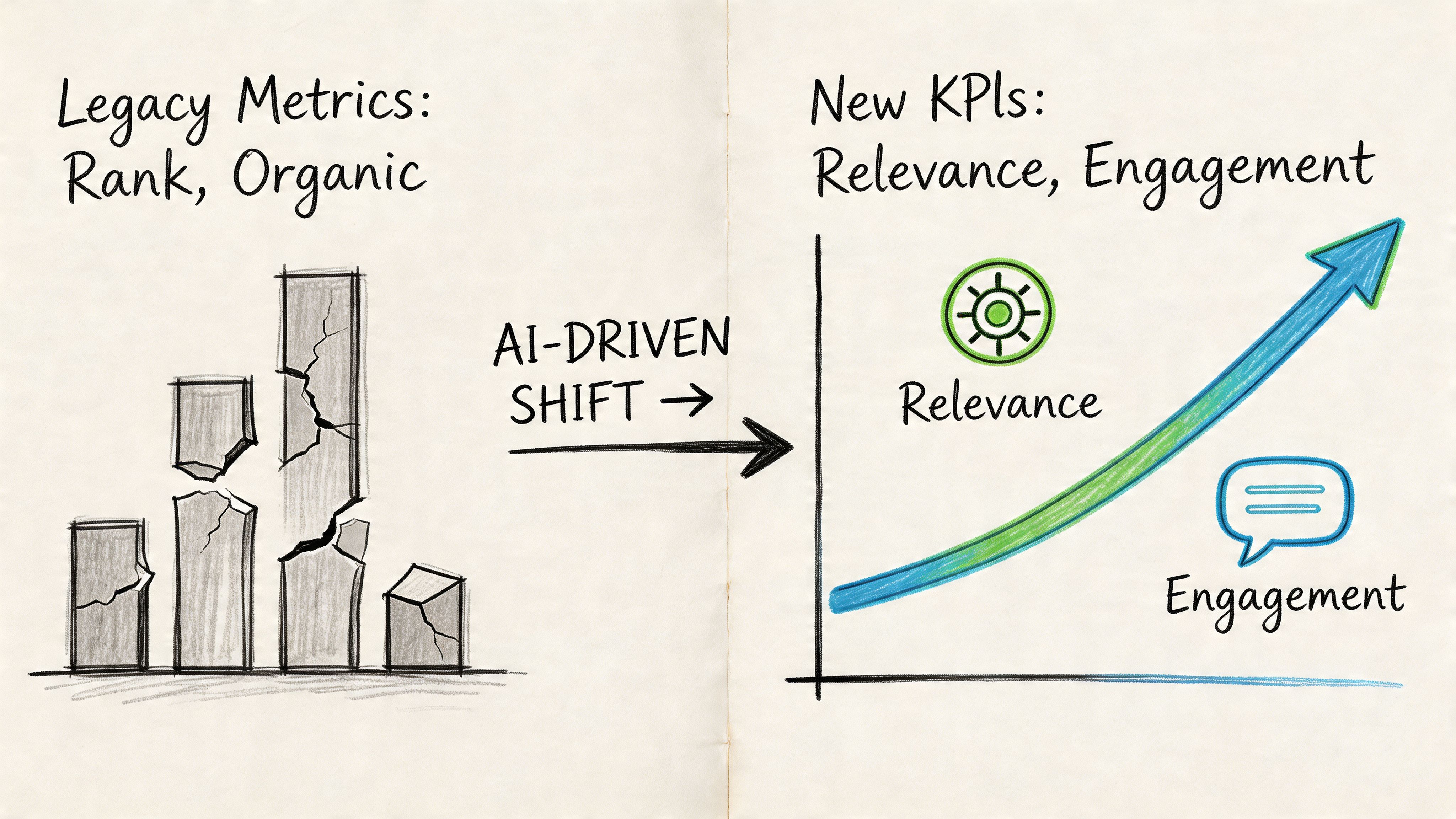
Legacy metrics miss the actual outcome
The market doesn't have a clean measurement standard yet. That gap is material. As Breaking B2B's review of LLM SEO agencies notes, marketing leaders face a measurement crisis, with agencies making large commitments without industry standards for verifying ROI claims.
That critique points to a real procurement risk. If a platform reports brand mentions without distinguishing true citations, or if it samples prompts inconsistently, the dashboard may be measuring noise rather than influence.
The KPI stack for AI discovery should center on four questions:
KPI | What it measures | Why it matters |
|---|---|---|
AI Share of Voice | Presence across relevant prompts and models | Reveals whether the brand is entering the answer set consistently |
Citation frequency | How often the brand or its assets are cited | Distinguishes sporadic inclusion from durable recall |
Citation quality | Whether the model cites core commercial pages or weak peripheral mentions | Separates vanity visibility from buying-journey relevance |
Prompt-level visibility | Performance on specific high-intent prompts | Connects AI exposure to actual demand categories |
Verifiable attribution is the new baseline
A trustworthy llm seo agency should explain exactly how it measures these signals. That means capturing answers as users perceive them, across multiple models, under controlled conditions.
A screenshot isn't a methodology. A repeatable observation process is.
This is why headless-browser-based measurement has become central. It observes rendered outputs across platforms without relying on incomplete API access or ad hoc manual checks. For executives trying to understand AI answer exposure, guidance on optimizing for AI Overviews is useful because it shifts the discussion from rankings to answer-surface behavior.
A sound reporting framework should let a marketing team verify:
Which prompt was run
Which model produced the answer
Whether the brand was cited, mentioned, or omitted
Which URL or source type appeared
Whether the result repeated over time
The strategic implication is larger than reporting hygiene. Once attribution becomes answer-based instead of rank-based, the organization starts managing knowledge representation rather than just search placement.
An Evaluation Framework for Your Next Agency Partner
The right agency choice starts with internal readiness. A company that can't execute recommendations will waste strategy, regardless of agency quality.
One of the most important findings in this market isn't about tooling. It's about organizational capacity. Contently's review of LLM SEO agencies captures the problem directly: brands have spent six months on a GEO audit only to realize they lacked the internal content engine to act on the recommendations. That is the execution-strategy mismatch in plain language.
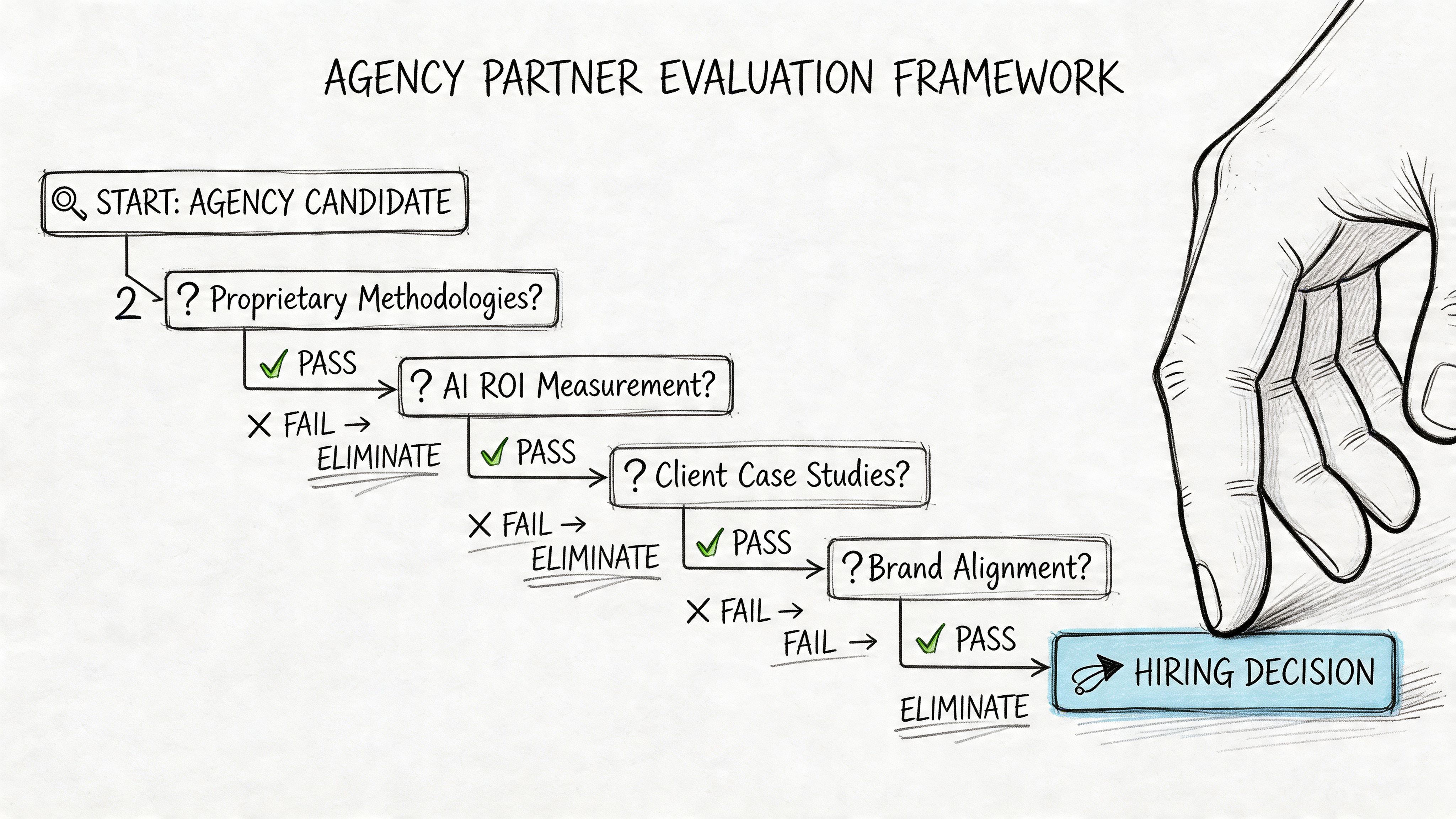
Internal readiness comes before external strategy
Before issuing an RFP, a leadership team should audit its own operating capacity.
A useful readiness check includes:
Content production capacity. Can the team revise, expand, and publish structured assets at the speed the strategy requires?
Technical ownership. Is there someone who can implement schema, page updates, and crawler-access changes?
Approval velocity. Can legal, product, and brand teams approve factual refinements without long delays?
Cross-channel alignment. Can PR, content, and SEO support the same evidence architecture?
A frequent breakdown in engagements occurs as follows: The agency identifies gaps correctly, but the client organization cannot turn recommendations into published, structured evidence.
The right questions expose weak agency models quickly
A CMO evaluating an llm seo agency should ask direct, unambiguous questions.
How is visibility measured across ChatGPT, Claude, Gemini, and Perplexity?
If the answer is vague, the reporting probably is too.How are citations distinguished from mentions?
Those are not the same outcome, and they shouldn't be priced or reported the same way.What is the verification method?
A serious partner should explain repeatability, prompt controls, and cross-platform capture.What operational work is required from the client?
This answer reveals whether the firm understands execution realities.Is the commercial model retainer-based or outcomes-based?
Incentives shape behavior. Buyers should know whether the partner is paid for activity or for sustained visibility outcomes.
The strongest agency signal isn't a polished GEO vocabulary. It's operational clarity about measurement, implementation, and dependency on the client's internal teams.
A useful strategic reference for this stage is the discussion of authority in GEO, because agency selection should reflect how authority is constructed, not how it is marketed.
A practical engagement cadence
A realistic first engagement usually follows a phased shape:
Period | Focus | Expected output |
|---|---|---|
Early phase | Visibility audit and prompt mapping | Baseline on answer presence, citation gaps, and high-value prompt clusters |
Middle phase | Technical and content implementation | Schema updates, content restructuring, and evidence alignment |
Later phase | Calibration and verification | Cross-model testing, reporting refinement, and iteration on weak prompts |
This cadence matters because leadership teams often expect immediate volume effects from what is a representation problem. The first goal is clarity. The second is technical correction. Only then does durable answer visibility become measurable.
Why Your Next Head of Search May Be an Engineer
Search leadership is shifting toward systems thinking. The winning team won't just publish content. It will design information that models can retrieve and trust.
The core change is not semantic. It is organizational. Traditional SEO rewarded editorial scale, keyword discipline, and link acquisition. AI discovery rewards structured evidence, entity clarity, crawler accessibility, and measurement rigor.
That pushes search toward engineering. The new leader in this function must understand how retrieval works, how content gets chunked, how schema exposes meaning, and how attribution can be verified across changing model interfaces. Marketing judgment still matters, but it is no longer enough on its own.
The market doesn't need more pages. It needs more retrievable truth.
Brands that want to compete inside AI-generated answers can book a call with Algomizer to assess how their products, services, and expertise are currently represented across major LLMs, and where technical, content, or measurement gaps are limiting citation visibility.