
Optimize Content for Answer Engines: The GEO Framework
Learn how to optimize content for answer engines like ChatGPT and Gemini. Our GEO framework provides a step-by-step guide to win visibility in AI answers.

A lot of advice on how to optimize content for answer engines misses how these systems work. It often frames AI discovery as a formatting issue, even though retrieval architecture plays the central role.
Many marketing teams still carry SEO habits into AI search workflows. The systems behind Google AI Overviews, ChatGPT, Perplexity, and Gemini retrieve fragments, reconcile sources, and generate responses through Retrieval-Augmented Generation rather than simply sorting documents.
The shift is measurable. Emerging 2024–2026 LLMs such as Gemini 2.0 and Claude 3.5 weigh external trust signals over on-page SEO by 3.2x, according to Position Digital's benchmark study of 1,200 AI-generated answers across 15 categories in its analysis of answer engine optimization best practices. That finding reshapes the most common playbook in the market.
A large share of published AEO guidance remains focused on page-level advice. Position Digital reports that 78% of AEO content focuses only on on-page formatting while leaving out the off-page grounding anchors that shape model confidence. CMOs need more than checklist SEO. They need an operating model for citation control.
That operating model starts with a clear distinction. Traditional SEO focuses on ranking. GEO focuses on retrievability, attribution, and repeated citation in model outputs. Readers comparing stacks can review resources that compare top AI content optimization tools, but tool selection comes after system design. A retrieval-first structure is what gives software something strong to work with.
The deeper strategic reset appears in Algomizer's earlier chapter on what Generative Engine Optimization is. The central point remains the same. Discovery in AI interfaces goes to brands that become dependable source material.
Table of Contents
Executive Summary The New Rules of Discovery
Traditional SEO no longer maps to AI retrieval
Citation dominance is an engineering problem
Reverse Engineering AI Information Retrieval
RAG systems retrieve passages, not pages
Machine constraints dictate content design
Machine readability decides citation eligibility
Engineering Truth with Evidence Clusters
Evidence Clusters create citation-grade proof
Semantic Density determines extractability
SEO vs. GEO A Fundamental Shift in Optimization
Deploying Grounding Anchors Across the Web
Source biasing changes what models trust
Entity identity must remain consistent everywhere
Measuring and Verifying AI Visibility
API reporting misses real-world citations
Headless observation produces verifiable evidence
The Paradigm Shift From Ranking to Reasoning
Brands must become source material
Reasoning systems reward structured truth
Executive Summary The New Rules of Discovery
Discovery in AI systems now depends on whether a brand becomes citable source material. That is a different operating model from classic search, and it changes what CMOs should fund, publish, and measure.
Our research at Algomizer frames this shift as an engineering problem. A page can be well written and technically clean and still underperform in answer engines when the surrounding web does not reinforce the same claims, entities, and proof points. Competitors often reduce answer engine optimization to page structure. We see that view as incomplete because citation behavior forms through retrieval, source selection, and attribution.
Traditional SEO no longer maps to AI retrieval
The market still assumes that strong SEO performance will carry over into AI visibility. Under closer review, answer engines assemble responses from evidence they can retrieve, trust, and synthesize with low ambiguity.
External validation carries more weight than many content teams expect. A claim that appears only on a brand-owned property remains self-asserted. When the same claim is repeated consistently across credible third-party environments, a model can cite it more confidently and with less response risk.
That explains why so much AEO advice plateaus. On-page improvements become more effective once the model has enough confidence in the source package around the brand. Algomizer's view of what Generative Engine Optimization is starts from that premise. The unit of competition extends beyond the page itself. It includes the evidence footprint attached to the entity.
Citation dominance is an engineering problem
CMOs should treat AI visibility as a coordination layer across content, PR, structured data, reviews, analyst mentions, and measurement. The goal is simple. Reduce uncertainty for the model.
We use a three-part framework:
Evidence design: publish claims in forms that can be extracted, quoted, and checked quickly
Source biasing: place corroborating statements in environments models are more likely to trust and retrieve
Verification: observe live answer surfaces to confirm whether the brand is cited, omitted, or replaced by competitors
This is the gap in much of the public guidance. HubSpot-style advice often stops at on-page formatting and FAQ patterns. That helps with readability. It gives less guidance on influencing source preference across the wider web or on verifying whether those interventions changed citation outcomes.
Teams comparing platforms may want to compare top AI content optimization tools to assess workflow fit. The larger advantage comes from controlling the evidence environment around the brand and measuring citation share directly in live interfaces.
The strategic implication is straightforward. Answer engines tend to reward brands that are easy to verify, easy to reconcile across sources, and safe to attribute. In this field, visibility follows engineered trust.
Reverse Engineering AI Information Retrieval
Answer engines work under strict technical constraints. Content must be built for passage retrieval, rapid rendering, and low-friction synthesis.
A useful visual model of the pipeline appears below.

RAG systems retrieve passages, not pages
The practical architecture is a three-part loop. First, the system retrieves candidate material relevant to the user's question. Next, it augments the model context with selected passages or structured snippets. Then it generates a response from that temporary evidence set.
Classic search maps queries to documents and leaves the final synthesis to users. In answer engines, the machine performs the synthesis directly. That changes what counts as optimized content.
A long page with a buried answer often loses visibility to a compact paragraph that states the claim at the top and supports it immediately after. Search Engine Land's discussion of generative engine optimization notes that generative engines extract self-contained, front-loaded paragraphs where the main point appears at the start, especially when that passage answers a single well-defined question.
The system isn't trying to appreciate a page. It's trying to harvest a usable block.
This is why content teams need to think in passages. Each block needs to survive extraction on its own.
Machine constraints dictate content design
Retrieval happens under tight time limits. AI systems often operate under retrieval timeouts as short as 1–5 seconds, which makes page speed decisive because slow-loading pages are frequently truncated or ignored entirely by generative engines, as described in Jakob Nielsen's analysis of GEO and retrieval behavior.
That timing pressure changes how teams should structure publishing systems:
Render complete HTML immediately. If a crawler hits a page and meets script-heavy delay, the page may never become evidence.
Write single-question blocks. One block should answer one intent cleanly.
Front-load the takeaway. Supporting detail belongs after the answer.
Reduce dependency on narrative setup. RAG extraction strips context aggressively.
Prompt architects have already learned a similar lesson in product interfaces. The discipline behind essential prompt design for AI founders is relevant here because both prompts and web passages perform better when intent, instruction, and context are explicit.
Machine readability decides citation eligibility
Teams often talk about “good content” as if quality alone creates visibility. In answer engines, content also needs machine legibility. A strong page must be renderable, segmentable, semantically clear, and evidence-heavy at the block level.
That shifts the unit of optimization from page experience to retrieval object. The passage becomes the product.
Return to Chapter 1. Book a call: schedule a complimentary visibility assessment.
Engineering Truth with Evidence Clusters
Citation-grade content must package proof in modular form. The most effective approach combines structured claims, corroborating assets, and dense factual framing.
Evidence Clusters create citation-grade proof
Algomizer's proprietary framework begins with Evidence Clusters. An Evidence Cluster is a deliberately interlinked set of assets that verifies a single commercial or topical claim from multiple machine-readable angles.
A cluster usually includes a primary explanation page, a supporting FAQ, a proof-oriented comparison or glossary page, and one or more external references that reinforce the same entity and claim. The model experiences these assets as repeated confirmation across a coherent source set.
Answer engines retrieve text while also evaluating whether a passage fits a broader pattern of corroboration. A stand-alone blog post provides limited evidence. A structured claim repeated across aligned assets provides stronger evidence.
Working definition: Evidence Clusters transform content from isolated pages into a verifiable knowledge system.
Semantic Density determines extractability
The second term is Semantic Density. This is the concentration of verifiable facts, named entities, explicit definitions, and source-backed claims inside a passage.
High Semantic Density does not mean keyword stuffing. It means every block carries enough informational substance to stand on its own during retrieval. Monday.com's guide to answer engine optimization identifies a core methodology: immediately following each H2 or H3 with a concise 40–60 word definition that directly answers the question. That structure increases AI extractability and citation rates because the answer arrives before explanation.
A usable operational sequence looks like this:
Start with the claim. The first sentence after a heading should answer the heading directly.
Add proof quickly. Named entities, cited facts, or source-backed specifics should appear near the top of the block.
Expand only after closure. Context belongs after the answer is complete.
Keep blocks modular. Each block should make sense if extracted into an AI Overview or chat answer.
The full technical rationale behind this method appears in Algomizer's framework on engineering truth for GEO.
SEO vs. GEO A Fundamental Shift in Optimization
Dimension | Traditional SEO | Generative Engine Optimization (GEO) |
|---|---|---|
Primary target | Ranked document | Retrieved passage |
Core unit of value | Click | Citation |
Content structure | Topic depth across page | Modular answer blocks |
Evidence model | Authority inferred from ranking signals | Authority reinforced through corroborated claims |
Writing pattern | Intro, build-up, conclusion | Inverted pyramid, answer first |
Technical priority | Crawlability and indexing | Renderability, extractability, quotability |
Off-page role | Link equity | Grounding anchors and entity confirmation |
Reporting lens | Traffic and rank movement | Visible inclusion in generated answers |
The shift reaches beyond a standard content refresh. SEO optimized pages to win a position. GEO engineers passages to become source material inside machine reasoning.
Return to Chapter 1. Book a call: schedule a complimentary visibility assessment.
Deploying Grounding Anchors Across the Web
On-page clarity alone rarely wins citations. LLMs form trust by reconciling what a brand says about itself with what the surrounding web says independently.

Source biasing changes what models trust
Our analysis of answer surfaces points to a consistent retrieval pattern. Models give more weight to claims that appear across multiple source types with matching entity language, especially when at least some of those sources are not brand-controlled. That is why off-page presence shapes more than awareness. It also influences which claims survive synthesis.
For CMOs, the implication is practical. Media mentions, review profiles, LinkedIn company pages, Quora threads, Reddit discussions, partner pages, and niche forums operate as grounding anchors when they repeat the same identity and use-case framing. Competitors that focus only on schema and page formatting leave this layer underdeveloped, even though it often determines whether a model treats a claim as self-description or externally confirmed fact.
We deploy anchors in a controlled sequence:
Canonical proof page first: Publish one brand-owned page that states the core claim in language precise enough for quotation.
Professional identity second: Align company name, product naming, category labels, and positioning across LinkedIn and other structured profiles.
Discussion seeding third: Introduce the same use-case language into relevant community threads where the problem is already being discussed.
Reference reinforcement fourth: Secure third-party mentions that restate the same entity framing without adding conflicting terminology.
This sequence matters because LLM retrieval is sensitive to consistency across documents, not just authority within a single URL. A scattered footprint creates attribution drag. A repeated footprint creates probabilistic confidence.
A short walkthrough of external authority design is useful here.
Entity identity must remain consistent everywhere
Entity ambiguity lowers citation likelihood. When a company describes itself one way on its site, another way on LinkedIn, and a third way on review platforms, the model has to resolve competing descriptions. In many cases, that lowers the chance of a direct citation.
A stable entity identity requires consistency in:
Company naming
Product taxonomy
Category definition
Executive attribution
Use-case language
We treat this as an engineering problem. The goal is to reduce variance in how the web describes the entity so models can map scattered references back to the same brand with high confidence. Teams that want to operationalize that process can start with this framework for auditing brand visibility across LLMs.
One measurement-focused example is Algomizer, which provides GEO and AI search services including media placement, content engineering, and headless-browser visibility tracking. The analytical point is straightforward. Source biasing works when off-platform references and on-site claims reinforce the same entity graph instead of introducing drift.
A brand becomes citable when the web repeats the same verifiable truth about it in enough trusted places.
Measuring and Verifying AI Visibility
AI visibility must be observed where answers appear. Anything less turns reporting into inference.
A comparison view helps clarify the reporting gap.
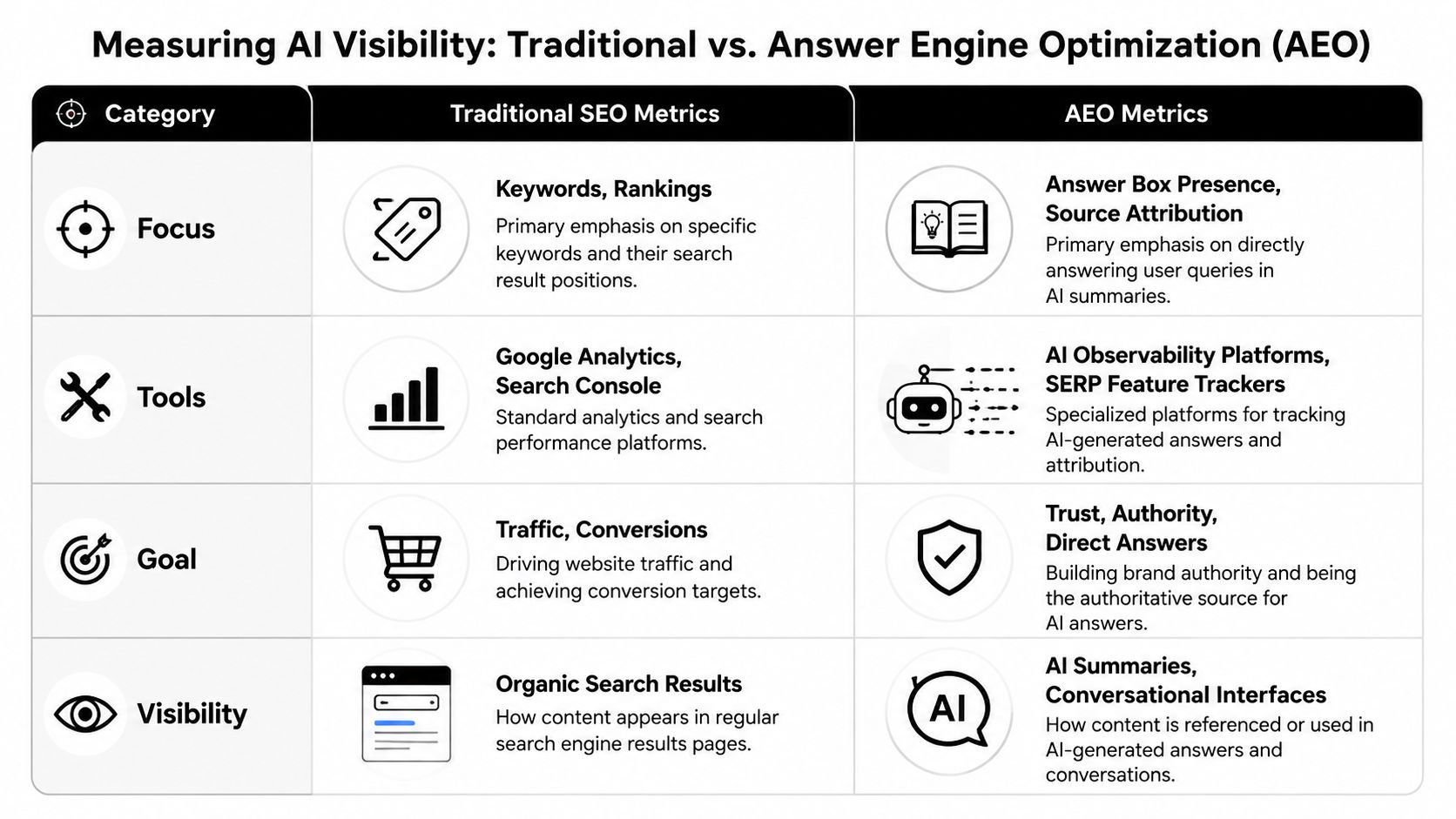
API reporting misses real-world citations
Many teams still rely on APIs or abstract “AI rank” estimates. That approach leaves gaps when answers are dynamically rendered, personalized by context, or embedded in changing interface states.
The measurement gap is documented. API-based tools miss 47% of non-boolean citations due to dynamic rendering and context-dependent responses, while headless browser tracking increases AI visibility measurement accuracy by 2.8x, according to Rankdots' discussion of answer engine optimization measurement.
That single comparison changes how CMOs should evaluate vendors. If a reporting method misses nearly half of the citations that matter, downstream ROI claims become unstable.
Headless observation produces verifiable evidence
Headless browser tracking works because it captures what a human user would see in ChatGPT, Gemini, Perplexity, or browser-based answer surfaces. It does not ask the platform for a simplified answer object. It renders the interface, waits for dynamic output, and records the visible citation state.
The strongest reporting systems therefore prioritize:
Measurement question | Weak method | Reliable method |
|---|---|---|
Did the brand appear? | API summary | Headless interface capture |
Was the brand cited or merely implied? | Keyword match | Visible attribution review |
Did the answer vary by context? | Static prompt set | Repeated live prompt testing |
Can a third party verify the result? | Proprietary score | Screenshot or session-based evidence |
For teams building a serious observability program, Algomizer's audit framework on how to audit brand visibility on LLMs is a useful reference point because it centers verification over proxy metrics.
Measurement principle: If the method can't reproduce the user experience, it can't prove visibility.
This is why AI search reporting now looks more like product QA and less like rank tracking.
Return to Chapter 1. Book a call: schedule a complimentary visibility assessment.
The Paradigm Shift From Ranking to Reasoning
The old SEO mental model reaches its limit here. Answer engines assemble responses from sources they judge reusable, defensible, and easy to ground rather than sorting pages by likely click value.
That changes the CMO's job. Visibility now depends on whether a model can pull your claims into its reasoning path with low risk and low transformation cost. Placement still matters, and citation eligibility matters even more.
Brands must become source material
A brand asset now competes on a different layer. It must function as usable evidence.
We see four recurring properties in content that survives model selection. It states claims with precision. It attaches those claims to verifiable entities, definitions, or observations. It appears in environments that reinforce the same interpretation. It can be cited without forcing the model to infer missing context. This is the basis of the Algomizer framework for engineering AI citations. We optimize the page, the surrounding source graph, the media placement strategy, and the measurement system that proves whether citation occurred.
This is the point many content programs miss. They improve formatting for answer engines and stop there. Large models do not form trust from formatting alone. They form preferences from repeated exposure to consistent claims across sources they already treat as admissible.
Reasoning systems reward structured truth
External research supports the broader GEO premise. Princeton's work on Generative Engine Optimization research showed that content changes can improve visibility in generative engine responses.
Our conclusion is narrower and more operational. Visibility gains come from reducing ambiguity at the claim level, increasing corroboration around priority narratives, and shaping where models are likely to encounter those narratives across the open web. In practice, the winning unit is the evidence cluster.
That distinction matters because reasoning systems compress, compare, and synthesize. When your brand publishes a strong page but the surrounding web provides weak reinforcement, the model has less incentive to rely on your version of the truth. When your claims appear across controlled placements, expert commentary, structured documentation, and independent mentions with stable wording, the model can reuse them with less uncertainty.
We built Algomizer around that reality. The objective is engineered citation probability that can be observed, tested, and improved over time.
Brands that understand this structural shift will influence answers upstream, at the point where the model decides what is safe to say. Brands that continue treating AI discovery as a ranking problem will remain easy to find and harder to cite.