
How to Audit Brand Visibility on LLMs: A GEO Playbook
Learn how to audit brand visibility on LLMs with our step-by-step GEO playbook. Measure citations, benchmark competitors, and find content gaps in AI answers.

Algomizer Research
June, 2026
The most popular advice on how to audit brand visibility on LLMs is incomplete. Counting whether ChatGPT or Perplexity mentions a brand is not an audit.
A real audit treats AI visibility as a measurable channel with controlled inputs, reproducible testing, and comparative analysis. The field itself only became formalized in 2024, when Generative Engine Optimization began to be treated as a distinct optimization problem rather than a side effect of SEO, with mature audits examining both the input layer and the answer layer through metrics such as citation share and semantic alignment (PBJ Marketing on AI brand visibility audits).
That shift matters because enterprise marketers don't need another vague visibility score. They need a system that explains why one model cites a review site, why another model omits the brand entirely, and why a competitor appears in recommendation prompts that should favor the stronger product.
At Algomizer, the black box framing is rejected. LLM visibility is constrained by source selection, source repetition, prompt framing, and answer synthesis. Those factors can be audited. They can also be acted on.
This chapter presents a practical methodology for how to audit brand visibility on LLMs using a controlled prompt set, structured data capture, and an analysis layer built around proprietary concepts such as Evidence Clusters and Semantic Density. Readers who need the foundational distinction between AI search optimization and legacy SEO can review this explainer on LLMO.
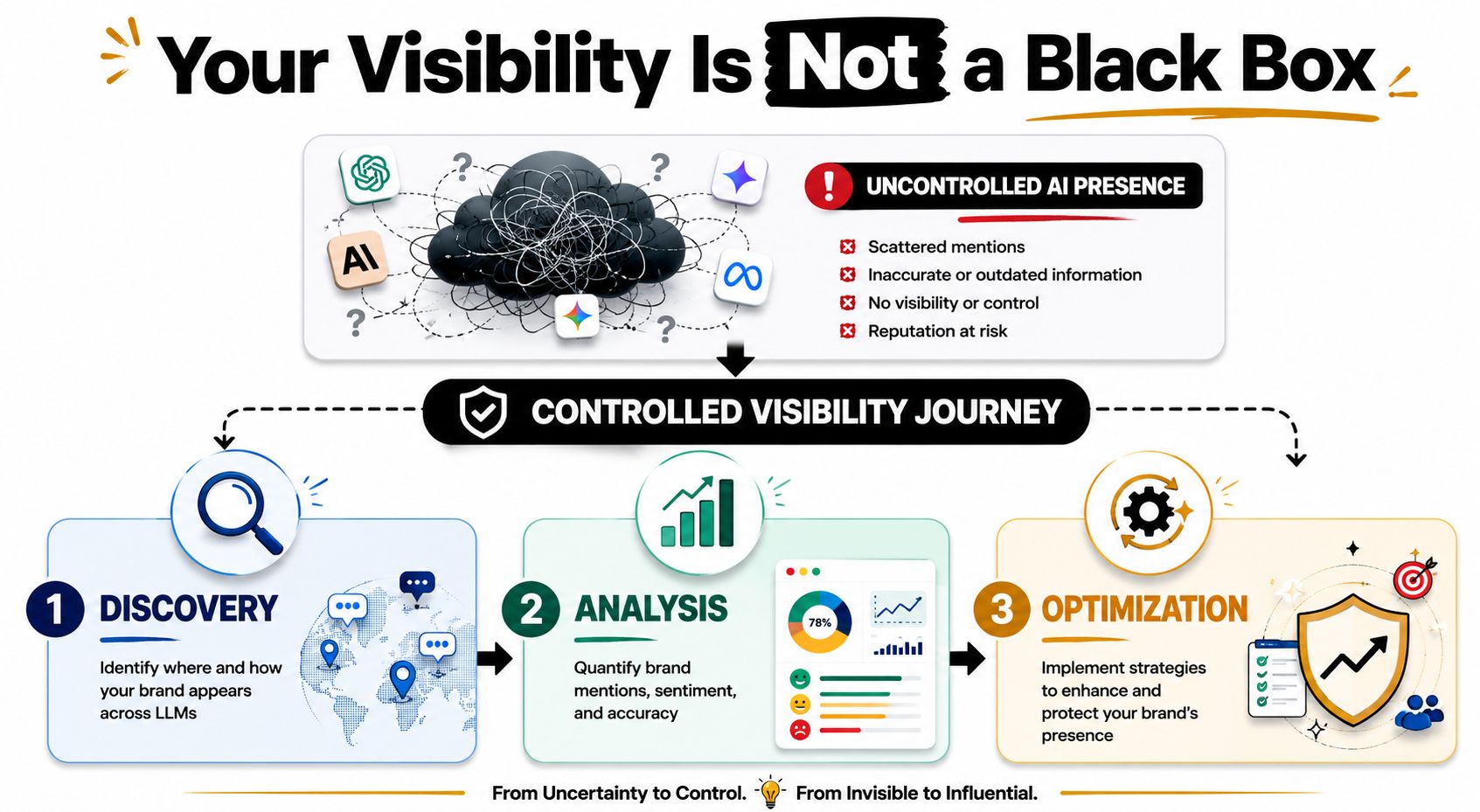
Table of Contents
Executive Summary Your Visibility Is Not a Black Box
Most visibility audits fail at the measurement layer
The Algomizer lens treats LLM visibility as an engineering system
Establish Your Audit Foundation
Query clusters determine audit quality
Scope must mirror business reality
Execute Reproducible Data Capture
Standardize the capture schema before you run prompts
Capture the user-facing environment, not just the model output
Record evidence in a way that supports later diagnosis
Analyze Visibility and Benchmark Performance
Mention counts are necessary and insufficient
The Algomizer framework explains why brands are cited
Build a Prioritized Remediation Roadmap
Every audit should end in ranked actions
Content gaps and technical gaps require different fixes
Operationalize Your Audit for Continuous Improvement
Continuous auditing creates competitive intelligence
The C-suite needs interpretation not raw logs
Executive Summary Your Visibility Is Not a Black Box
A brand's presence in AI answers can be audited systematically because model outputs follow observable source and framing patterns rather than pure randomness.
Most marketing teams still treat AI answers as mysterious. They run a few prompts in ChatGPT, note whether the company appears, and call that visibility tracking. That approach misses the actual unit of analysis. The question is how the model formed the answer, which sources shaped it, and whether competing brands occupy the recommendation space around the query.
Most visibility audits fail at the measurement layer
The strongest practical audit pattern starts with a repeatable baseline of prompts tested across major models such as ChatGPT, Gemini, Claude, and Perplexity, then compared using mention frequency, sentiment, accuracy, source quality, and competitor presence. Operationally, teams are advised to log each run in a spreadsheet or tracking tool and repeat the audit monthly or quarterly so changes in model behavior can be observed over time (Wellows on auditing brand visibility on LLMs).
That recommendation has a deeper implication. It means AI visibility should be managed like analytics, not treated like PR monitoring alone. A reliable audit compares the brand against rivals, tracks the exact prompts that trigger inclusion or exclusion, and examines whether the answer is built on authoritative material or low-signal listicles.
Practical rule: If the prompt set changes every run, the audit is measuring prompt drift.
The Algomizer lens treats LLM visibility as an engineering system
The proprietary Algomizer methodology uses three layers.
Prompt Layer: A fixed set of queries covering brand, category, competitor, and problem-aware intent.
Evidence Layer: The cited or implied materials that repeatedly shape the answer, grouped into Evidence Clusters such as product documentation, review platforms, community discussion, and expert commentary.
Answer Layer: The final framing that reaches the buyer, measured through inclusion, sentiment, factual accuracy, and competitive context.
This structure breaks the black box into inspectable components. It also explains why some brands with strong SEO underperform in AI answers. Search ranking strength and LLM citation strength are related, but they aren't identical. A brand can rank well in classic search and still lose AI recommendation prompts if the model keeps grounding its answer in competitor-heavy publications or community threads.
The useful question to ask is "Which evidence cluster is carrying competitor recall when our brand should own the answer?"
That is the threshold between observation and GEO. Once the audit is framed this way, the output becomes operational. Teams can identify which prompts matter, which sources recur, and which gaps are structural rather than accidental.
Establish Your Audit Foundation
A usable audit starts with query design, because prompt selection determines what the dataset can reveal and what it will hide.
Many enterprise teams begin with model selection. That is the wrong first move. The most impactful decision is defining the query clusters that reflect actual buyer intent and competitive pressure. Without that structure, the audit produces disconnected screenshots instead of decision-ready evidence.
Query clusters determine audit quality
A strong prompt library usually includes four clusters.
Brand queries ask for direct recall. Examples include prompts about what the company does, who it serves, or how it is described.
Category queries test whether the brand appears when buyers ask for solution types rather than vendor names.
Competitor queries reveal displacement risk by asking models to compare alternatives or recommend vendors in the same market.
Problem-aware queries test the most strategic territory. These prompts ask the model to solve a business problem without naming any brand.
Each cluster exposes a different failure mode. A company may dominate direct brand queries and still disappear from category or problem-aware prompts where real consideration begins.
Scope must mirror business reality
The audit scope should align with the operating footprint of the brand.
A B2B SaaS company selling analytics software, for example, should not treat all prompts as equal. Enterprise procurement, implementation, integration, and reporting use cases don't create the same visibility stakes. The query set has to reflect actual revenue-driving motions, product lines, and regional positioning.
A practical scoping checklist looks like this:
Define priority entities. Include the corporate brand, flagship products, category labels, and executive or expert entities if they influence visibility.
Select comparison brands. Use direct competitors that frequently appear in buyer conversations and AI responses.
Write approved descriptors. Keep a controlled list of preferred phrases for market category, differentiators, and core claims.
Map prompts to intent. Separate informational, evaluative, and recommendation-oriented prompts.
Teams don't lose LLM visibility evenly. They lose it in the specific prompt clusters that map to buying decisions.
The coined framework Semantic Density becomes useful. In Algomizer's methodology, Semantic Density measures how consistently a brand's approved descriptors appear across owned content, earned mentions, community discussion, and the language used by the models themselves. High Semantic Density means the same core meaning shows up across evidence layers. Low Semantic Density means the brand's narrative fractures across sources, which makes citation behavior less stable.
The audit should also name the target models before execution. ChatGPT, Gemini, Claude, and Perplexity typically belong in the baseline because they represent materially different answer environments. Some rely more heavily on visible citations, some synthesize more aggressively, and some make competitor presence more explicit.
A clean foundation creates one outcome: every later finding can be traced back to a deliberate measurement design instead of anecdotal prompting.
Execute Reproducible Data Capture
LLM visibility audits fail at the capture layer more often than the analysis layer. The problem is uncontrolled variance. If one run happens in a fresh browser session, another in an authenticated account, and a third through an API response that strips interface elements, the resulting dataset cannot support benchmarking.
At Algomizer, we treat data capture as an engineering problem. The objective is to create a repeatable observation system that records the same prompt under the same conditions across models, then preserves enough context to explain why an answer changed. That standard is what makes downstream metrics such as Citation Share and Evidence Clusters credible instead of anecdotal.
A usable capture protocol fixes five variables before a single query is run: prompt text, model and interface, session state, geography, and logging format. Cadence matters too, but consistency matters more. Monthly and quarterly runs both work if the operating conditions stay fixed.
Standardize the capture schema before you run prompts
Each prompt execution should produce a structured record, not a screenshot folder and a few analyst notes. At minimum, log these fields:
Prompt ID and exact wording: No improvisation. Version every change.
Model and surface: ChatGPT web, Gemini web, Claude web, Perplexity web, API endpoint, or another named environment.
Session conditions: Logged in or logged out, browser profile, personalization state, location, and time stamp.
Answer output: Full response text plus visible formatting elements.
Brand visibility classification: Primary mention, secondary mention, absent, or negative exclusion.
Citation data: Visible cited domains, link order, repeated sources, and source type.
Competitor co-occurrence: Which rival brands appear, and whether they are recommended, compared, or dismissed.
Evidence markers: Repeated claims, recurring source patterns, and content blocks that can later be grouped into Evidence Clusters.
That schema creates a dataset that analysts can query. It also prevents a common audit failure. Teams often remember to capture whether they were mentioned, but not which sources made that mention possible.
Reproducibility comes from fixed variables, not higher prompt volume.
Prompt design should also reduce ambiguity. Single-intent questions produce cleaner data than prompts that mix category education, pricing, implementation, and recommendations in one turn. A narrow prompt gives the model fewer degrees of freedom, which makes changes over time easier to attribute to actual visibility shifts rather than prompt noise.
Capture the user-facing environment, not just the model output
For enterprise audits, browser-based collection usually provides the more faithful record because it captures the interface users see. That includes citation modules, answer cards, “sources” panels, ranking order, and formatting choices that shape perceived authority. Teams evaluating capture options should understand the tradeoff described in this guide to AI search visibility measurement. Text output alone misses part of the trust surface.
Attribute | API Access | Headless Browser |
|---|---|---|
Session realism | Limited to API response conditions | Mirrors the live user environment more closely |
Interface capture | Text-first output | Captures citations, layout, and surfaced modules |
Citation visibility | Can differ from user-facing experience | Reflects visible answer presentation |
Reproducibility | Strong for controlled programmatic runs | Strong when browser state is standardized |
Best use | Scaled extraction and normalization | Representative auditing of real answer experience |
API capture still matters. It is efficient for structured parsing, large prompt libraries, and repeated extraction workflows. But API responses can understate or alter what an end user sees if the live product adds source panels, follow-up suggestions, or retrieval elements outside the base text response.
The strongest audit design combines both. A headless browser establishes the observable answer environment. Programmatic extraction then normalizes the output into analyzable fields. That is the same logic behind Algomizer's use of browser-based collection for cross-platform AI visibility auditing, paired with parsing pipelines that support repeat measurement and source-level analysis. Teams that need a benchmark for source extraction methods can review this framework for reliable citation analysis across AI search engines.
Record evidence in a way that supports later diagnosis
Raw outputs are not enough. Analysts need to tag recurring source relationships while capture is happening, because that is what later makes Citation Share and Evidence Clusters measurable.
Citation Share tracks how often a domain or source group appears across the collected answer set relative to competitors and to your own properties. Evidence Clusters group repeated trust signals that travel together, such as a review site plus a comparison blog plus a community thread that repeatedly co-occur in recommendation prompts. If those patterns are not captured at collection time, later analysis becomes guesswork.
This is also where many enterprise teams miss the actual cause of low visibility. The issue is often not total absence. It is unstable evidence. A brand may appear in one model because a single strong source is picked up, then disappear in another because the surrounding evidence cluster is thin, fragmented, or dominated by competitor citations.
A disciplined capture system fixes that. It turns each prompt run into a reproducible observation with traceable source context, which is the minimum standard for any serious LLM visibility audit.
Analyze Visibility and Benchmark Performance
The analytical layer should explain not only whether a brand appears, but why the model trusted some sources and ignored others.
Simple mention counting is a start, but it can't diagnose the mechanics of exclusion. A mature audit must inspect source quality, competitor overlap, and the concentration of evidence behind each answer. Industry guidance now treats that as a core gap in many audits, arguing that stronger analysis measures source concentration, citation overlap with competitors, and the balance between owned, earned, and community sources rather than relying on raw visibility frequency alone (Channel V Media on source-quality and citation-bias auditing).
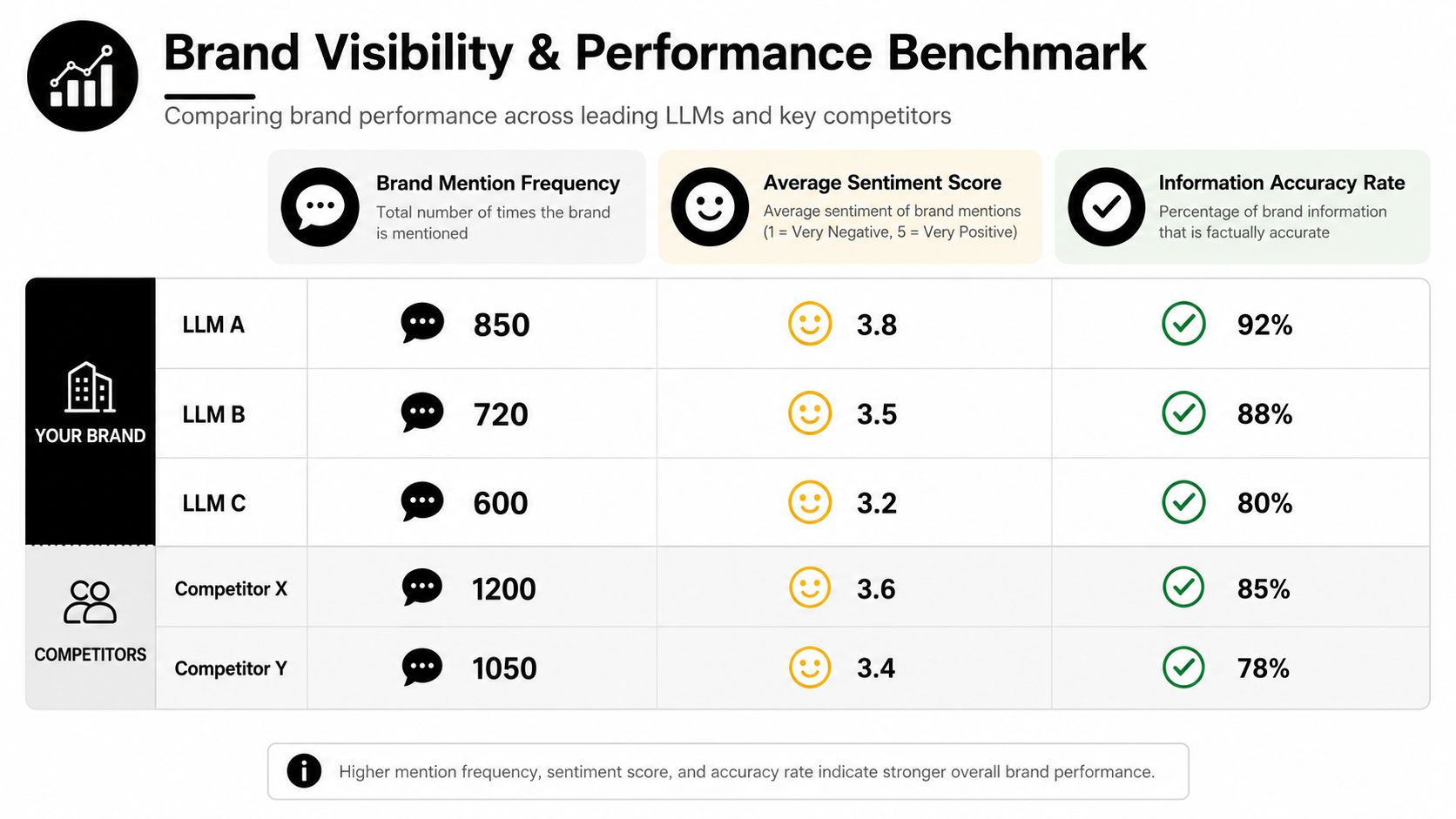
Mention counts are necessary and insufficient
The first pass should still quantify baseline visibility.
For each query cluster, teams should record whether the brand is present, how prominently it appears, and whether competitors occupy more persuasive positions in the answer. That creates directional visibility benchmarking. But deeper insight begins when the analysis asks which evidence layers dominate the model's answer formation.
A useful companion resource for teams building this reporting discipline is this guide to AI search visibility measurement, which helps frame how operational metrics can be translated into management reporting.
Later in the process, citation-level benchmarking becomes more important than mention-level benchmarking. Teams that need a deeper breakdown of source recurrence and overlap can study methods for citation analysis across AI search engines.
The Algomizer framework explains why brands are cited
The proprietary analysis model uses three metrics.
Citation Share tracks how often the brand appears in cited or clearly attributed answer support relative to competitors inside the same query cluster. It includes whether the answer grounds the recommendation in material associated with the brand.
Evidence Clusters group the recurring source types that shape model outputs. Typical clusters include:
product and technical documentation
analyst or expert coverage
review and comparison sites
community discussion such as Reddit or Quora
earned editorial coverage
Semantic Density evaluates whether the language in those clusters reinforces a coherent market identity. If product pages say one thing, review sites say another, and community threads use generic labels, the model has weak narrative compression. That weakens brand recall in generated answers.
A brand can be widely discussed and still be weakly legible to an LLM if the evidence is fragmented across inconsistent language.
For a B2B SaaS example, imagine a company that wants to own prompts around data governance. The audit may show that the brand appears in direct product prompts but loses category comparisons. Citation analysis may reveal that competitors dominate review-site and expert-commentary clusters, while the audited brand is represented mostly by its own documentation. The conclusion is that the model trusts third-party framing more than self-published claims in that topic area.
This kind of benchmark should also inspect answer framing. Does the model mention the brand as a primary recommendation, a secondary alternative, or a niche option? Does it cite the brand's documentation or summarize it indirectly through a third-party source? That distinction often predicts whether remediation should focus on source expansion, content restructuring, or technical accessibility.
A short walkthrough of this analytical mindset is useful here:
A strong benchmark doesn't stop at "Competitor X is more visible." It identifies the exact evidence clusters carrying that advantage and the semantic patterns that make the competitor easier for the model to retrieve, synthesize, and recommend.
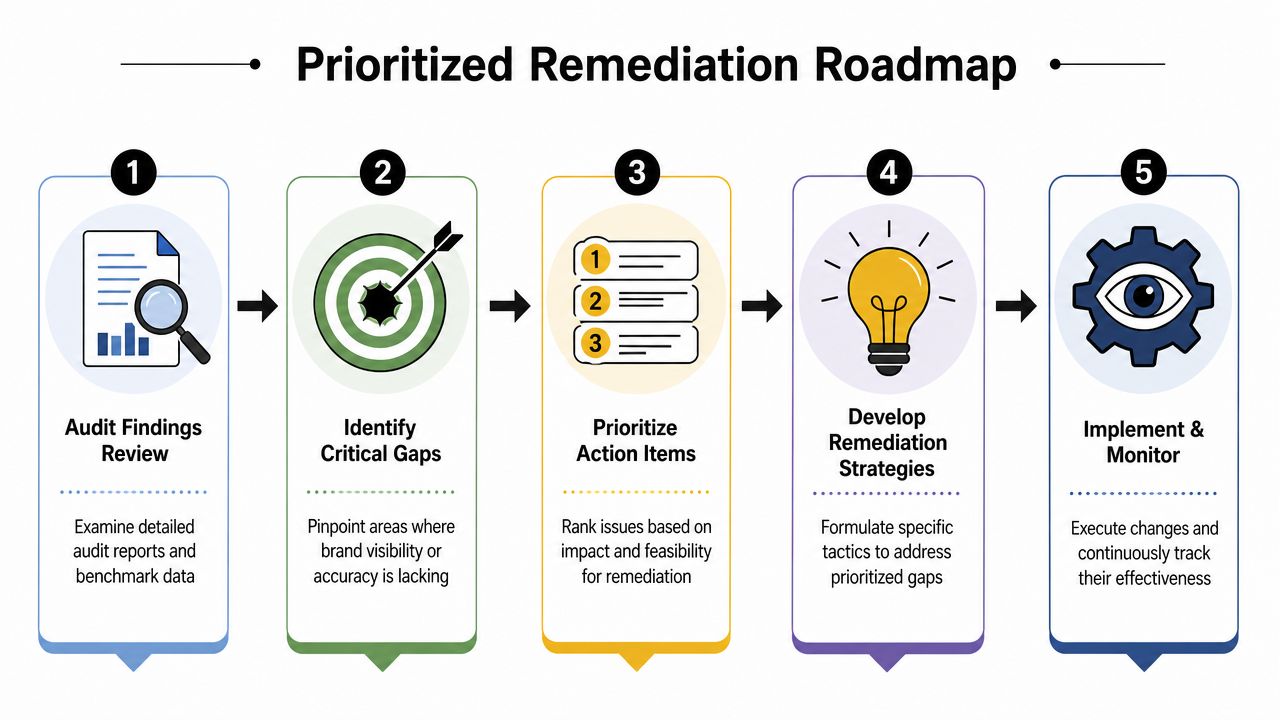
Build a Prioritized Remediation Roadmap
Audit output becomes valuable only when it turns into ranked action, because enterprise teams rarely have the capacity to fix every visibility gap at once.
The strongest audits separate issues into content gaps and technical gaps, then prioritize them by expected influence on model trust and implementation effort. That distinction prevents a common mistake. Teams often respond to poor AI visibility by publishing more content when the underlying problem is that the right evidence already exists but is difficult for models to parse, retrieve, or trust.
Every audit should end in ranked actions
A practical prioritization matrix uses two axes.
Gap type | High impact and lower effort | High impact and higher effort |
|---|---|---|
Content gap | Strengthen missing topic coverage where competitors are repeatedly cited | Build new evidence clusters across earned, expert, and community surfaces |
Technical gap | Improve crawlability, structure, and page clarity for existing priority assets | Rework fragmented documentation, inaccessible formats, or complex delivery patterns |
That matrix keeps remediation grounded in the evidence rather than in editorial instinct.
Content gaps and technical gaps require different fixes
Content gaps appear when competitors are repeatedly cited for topics the brand should own. Typical signs include absence from category prompts, shallow coverage of high-value use cases, or weak third-party support in expert and community channels.
Technical gaps appear when the brand has relevant material but the evidence isn't machine-legible enough to carry into the answer layer. Common patterns include documentation buried in hard-to-extract formats, fragmented topic coverage across disconnected pages, or messaging so abstract that the model can't easily associate the brand with the category.
A good roadmap tends to order actions like this:
Fix direct representation errors first. Incorrect product descriptions or stale market positioning should be addressed before expansion work begins.
Patch high-value topic absences. If the brand loses critical problem-aware prompts, those gaps deserve immediate attention.
Strengthen evidence diversity. Reduce overreliance on owned content by improving presence in earned, expert, and community-adjacent sources.
Normalize language across surfaces. Improve Semantic Density so the same category and differentiation language appears consistently.
Re-test the same query cluster. Remediation without remeasurement is just publishing.
The best remediation roadmap doesn't chase every missing mention. It fixes the evidence structures that repeatedly suppress recommendation eligibility.
That is the key strategic shift. The is the plan for AI answer visibility, expressed in prioritized engineering work.
Operationalize Your Audit for Continuous Improvement
Continuous auditing creates a defensible advantage because model behavior, source ecosystems, and competitor evidence all keep moving even when the brand's own site doesn't.
An LLM visibility audit should become an operating rhythm inside search, content, PR, and product marketing functions. That shift matters because the same baseline prompt set can reveal emerging risks long before they appear in pipeline reporting or brand-lift studies. When a model starts citing a new publication heavily, when a competitor gains recommendation territory, or when answer framing turns vague, the audit becomes an early warning system.
Continuous auditing creates competitive intelligence
The most effective workflow treats the audit as an ongoing monitoring cycle rather than a project with a finish line.
The cadence should be tied to a reporting system that executives can absorb quickly. That doesn't mean exposing raw prompt logs. It means summarizing directional movement across the prompt clusters that matter to revenue and brand positioning. Teams that already maintain executive reporting can adapt patterns from customizable SEO dashboards for this purpose, provided the metrics are rewritten for AI answer environments rather than ranking reports.
The C-suite needs interpretation not raw logs
A useful executive dashboard usually includes:
Query cluster status: Which strategic prompt groups improved, declined, or remained unchanged.
Competitor displacement view: Where named rivals entered recommendation prompts or gained source support.
Accuracy and framing alerts: Whether the brand is described correctly and in the intended category.
Evidence health summary: Which source clusters are carrying visibility and which remain underdeveloped.
This reporting model changes the internal value of the audit. It stops being a specialist exercise for SEO teams and becomes a shared intelligence function across communications, content, and demand generation.
The deeper conclusion is simple. AI visibility isn't a mysterious outcome delivered by inaccessible models. It is a measurable reflection of how clearly, consistently, and authoritatively the brand is represented across the evidence ecosystem the models rely on.
Brands that need a repeatable system for auditing and improving AI answer visibility can book a call with Algomizer to discuss prompt baselining, citation analysis, and ongoing GEO measurement.