
Drive Growth with Sentiment Analysis Marketing
Master sentiment analysis marketing using our AI framework. Boost GEO & AI search visibility and drive measurable business results.

Subtitle: Sentiment Analysis Marketing in the Age of AI Search
Date: June, 2026
Executive summary. Sentiment analysis marketing has shifted from a reporting function to a control layer for AI-mediated brand visibility. AI search systems do not retrieve a single opinion about a company. They synthesize repeated claims across reviews, support transcripts, social discussion, analyst coverage, and third-party commentary, then compress those signals into an answer that users treat as a recommendation.
That change alters the job of marketing leadership. A dashboard that labels conversation as positive, negative, or neutral cannot explain why a model describes one brand as reliable, another as overpriced, and a third as difficult to implement. Large language models weight sentiment through context, source credibility, semantic consistency, and repetition across channels. The business outcome is direct. Brands with stronger sentiment structure are more likely to appear in AI-generated answers with favorable framing, clearer differentiation, and higher trust.
Algomizer's analysis frames this shift through an AI-first lens. Sentiment is no longer just monitored after campaigns, launches, or service failures. It is shaped upstream by controlling which claims become legible, repeated, and retrievable to machine intermediaries. The pipeline is a decision.
This paper argues for a different operating model. Marketing teams need to move from passive listening to perception engineering, where sentiment data is cleaned, validated, connected to entity-level topics, and distributed in formats that AI systems can parse with confidence. In that model, sentiment analysis becomes part of GEO strategy. It influences not only how people feel about the brand, but how AI systems summarize what the market believes.
Table of Contents
Chapter 1 The New Economics of Digital Perception
Sentiment has become market infrastructure
AI search changes what sentiment is worth
Chapter 2 Deconstructing the Sentiment Analysis Pipeline
The pipeline is operational, not abstract
Each stage creates a different failure mode
Chapter 3 Four High-Value Use Cases for AI Search Visibility
Brand health becomes answer quality control
Campaign measurement becomes evidence seeding
Product feedback becomes retrieval training data
Competitive intelligence becomes comparative framing control
Chapter 4 The Semantic Resonance Framework for GEO
Polarity is obsolete as a strategic metric
Three pillars determine resonance
Resonance can be engineered
Chapter 5 A Contrast Between Monitoring and Engineering Sentiment
The operating model has changed
The KPI stack must change with it
Chapter 6 An Enterprise Roadmap for Sentiment-Driven GEO
Phase 1 and Phase 2 establish the data foundation
Phase 3 and Phase 4 turn analysis into workflow
Phase 5 closes the loop with business outcomes
Chapter 7 The Shift from Passive Listening to Active Shaping
Marketing leaders now manage machine-readable reputation
The strategic question has changed
Chapter 1 The New Economics of Digital Perception
Sentiment has become market infrastructure
Digital perception now functions like operating infrastructure for growth. It influences how brands are evaluated by customers, analysts, recommendation systems, and increasingly by large language models that synthesize public evidence into a single answer.
Sentiment analysis marketing therefore belongs with CRM design, paid media measurement, and category strategy. The reason is structural. Sentiment data no longer sits inside a research workflow as a periodic reporting layer. It now feeds campaign analysis, support prioritization, product feedback review, review management, and executive reporting. Once those signals are captured, labeled, and stored, they become part of the evidence base that AI systems can retrieve and summarize.
That shift changes the economics of reputation.
A mention has limited value on its own. Repeated language patterns across reviews, forums, editorial coverage, and support-derived discussions carry more weight because they create machine-readable consistency. In an AI search environment, consistency is often more influential than volume. LLMs do not merely count positive and negative statements. They assemble probable brand narratives from clusters of semantically related evidence.
AI search changes what sentiment is worth
The relevant strategic question is no longer whether sentiment trends look favorable on a dashboard. The relevant question is whether AI systems will infer the brand attributes a company needs to win consideration.
When a buyer asks an LLM whether a vendor is reliable, forward-thinking, easy to deploy, or expensive, the model builds an answer from available evidence. It pulls from sources that are easy to retrieve, topically aligned with the prompt, and specific enough to support summarization. That process gives disproportionate value to sentiment signals attached to high-intent themes such as onboarding speed, customer support quality, pricing clarity, implementation risk, and product stability.
Executive rule: A brand controls AI search perception only when it controls the evidence clusters from which that perception is generated.
This is the key economic change. Sentiment is no longer just a measurement layer for social listening. It is an input to answer generation.
Our analysis framework treats this as a weighting problem. LLM-mediated brand perception is shaped by four factors: topical relevance, source credibility, repetition across independent sources, and linguistic specificity. General praise often loses to precise criticism because precise criticism is easier for a model to cite, compress, and reuse. A brand can show net-positive sentiment and still underperform in AI search if negative narratives are more coherent around commercially important topics.
That is why polarity alone fails as an executive metric. The business outcome depends on which themes persist, where they appear, and how easily a model can convert them into a recommendation or warning.
A stronger definition follows. Sentiment analysis marketing is the practice of converting distributed customer language into structured evidence that improves discoverability, trust, and recommendation within AI-mediated buying journeys.
For marketing leaders, this creates a shared operating surface across brand, SEO, PR, customer support, and product marketing. Those teams are contributing to the same perception graph whether they manage it intentionally or not. Book a call with Algomizer to assess how AI systems currently interpret brand sentiment and category authority.
Return to Chapter 1.
Chapter 2 Deconstructing the Sentiment Analysis Pipeline
The pipeline is operational, not abstract
Effective sentiment analysis follows a three-stage pipeline of data collection, text classification, and insight generation, using NLP to turn unstructured feedback into quantifiable sentiment scores (three-stage sentiment analysis pipeline).

The mechanics are easier to understand through an intelligence workflow. Raw field reports arrive from many places. Social posts, review sites, survey responses, support tickets, emails, and news mentions all carry fragments of perception. The system ingests those fragments, normalizes them, and classifies the emotional and thematic content. Only after that does the executive dashboard receive something usable.
For marketing teams, the point isn't academic. Every pipeline stage determines whether the final output is trustworthy enough to inform action.
Each stage creates a different failure mode
Data collection determines coverage. If a team captures social media and ignores support conversations, the system overweights public performance and underweights operational friction. If it captures reviews but skips email or chat, it misses high-intent dissatisfaction that may never become public.
Text classification determines interpretation. NLP systems identify entities, polarity, and often related themes, but classification quality depends on context. A phrase that looks positive in general language can be negative in a narrow product context. Brand names, feature names, and industry jargon can all distort default model behavior.
Insight generation determines business usefulness. A sentiment score without topic context rarely tells a CMO what to do next. The value appears only when the output is linked to messages, audiences, channels, or funnel stages.
The real pipeline output is not a score. It is a decision.
A disciplined operating model treats the pipeline like this:
Collect broadly: Pull from reviews, social, support, surveys, and owned communication channels.
Classify with context: Validate how the model handles the company's naming conventions, product language, and common edge cases.
Translate into action: Route outputs to the owners who can change messaging, support scripts, product positioning, or escalation workflows.
A weak sentiment program fails unnoticed because the dashboard still looks polished. A strong one exposes where coverage is thin, where classification breaks, and where teams need to intervene. That distinction matters more in AI search, because low-quality interpretation doesn't stay inside the dashboard. It can cascade into the public narrative.
Return to Chapter 1. Book a call with Algomizer if a team needs to map raw perception signals into AI-visible evidence.
Chapter 3 Four High-Value Use Cases for AI Search Visibility
Brand health becomes answer quality control
Real-time AI monitoring has become mainstream marketing behavior. SurveyMonkey reports that 88% of marketers use AI in their day-to-day roles, and one industry source reports that companies using dedicated sentiment platforms have seen a 30% improvement in identifying and responding to negative feedback in real time (AI adoption and real-time response improvement in sentiment operations).
That changes the role of brand health monitoring. The job is no longer to observe a reputation curve after the fact. The job is to control the quality of the answer a model can synthesize when asked whether the brand is trustworthy, expensive, creative, or hard to work with.
A buyer asking Perplexity or Google's AI Overviews for a quick vendor summary isn't looking at the internal dashboard. The model is synthesizing from public evidence. Sentiment analysis becomes the early warning system for answer deterioration.
Campaign measurement becomes evidence seeding
Campaign teams usually assess launch performance through engagement and conversion reporting. In an AI-search environment, they also need to ask what durable language the campaign created.
A successful campaign creates discussion that leaves behind machine-readable traces. That includes review language, forum commentary, editorial references, and customer descriptions that persist beyond the paid flight. If the language cluster around a launch reinforces clarity, usefulness, or category leadership, the campaign has built future retrieval assets.
The critical distinction is duration. Social spikes decay quickly. Repeated thematic language across stable sources accumulates.
Product feedback becomes retrieval training data
Product marketers and CX leaders already use sentiment to identify friction. The GEO lens makes the consequence larger. Product sentiment is often the clearest evidence that LLMs can summarize into simple buyer-facing claims.
If support logs and reviews repeatedly associate a feature with confusion, bugs, or delayed value, those patterns can become the dominant explanatory frame. If they repeatedly associate it with speed, simplicity, or reliability, the opposite occurs. The product team is influencing future recommendation logic.
Competitive intelligence becomes comparative framing control
Competitive sentiment analysis used to focus on relative share of voice and public reaction. The AI-search version focuses on comparative framing. Which adjectives, objections, and strengths are consistently attached to each brand when a model assembles side-by-side answers?
A practical operating model looks like this:
Brand health: Track whether high-salience trust topics are stabilizing or worsening.
Campaigns: Look for recurring audience language that should be reinforced in owned and earned channels.
Product feedback: Convert repeated friction themes into fixes, documentation changes, and narrative corrections.
Competitor analysis: Identify where rivals have cleaner thematic associations in public discourse.
A sentiment program creates strategic leverage when it changes what AI can plausibly conclude, not when it merely confirms what the team already suspects.
The common thread across all four use cases is permanence. Monitoring is useful. Engineering durable evidence is more valuable.
Return to Chapter 1. Book a call with Algomizer to connect sentiment patterns to AI answer visibility across major model interfaces.
Chapter 4 The Semantic Resonance Framework for GEO
Polarity is obsolete as a strategic metric
A 2026 study found that user trust in sentiment systems depended more on context adaptation and linguistic nuance than on raw accuracy, with those factors explaining about 79.8% of variance (study on trust, context adaptation, and linguistic nuance in sentiment systems). That finding has direct implications for sentiment analysis marketing. Polarity is not enough. The system must explain why the sentiment appears, where it appears, and whether the interpretation survives real-world language.
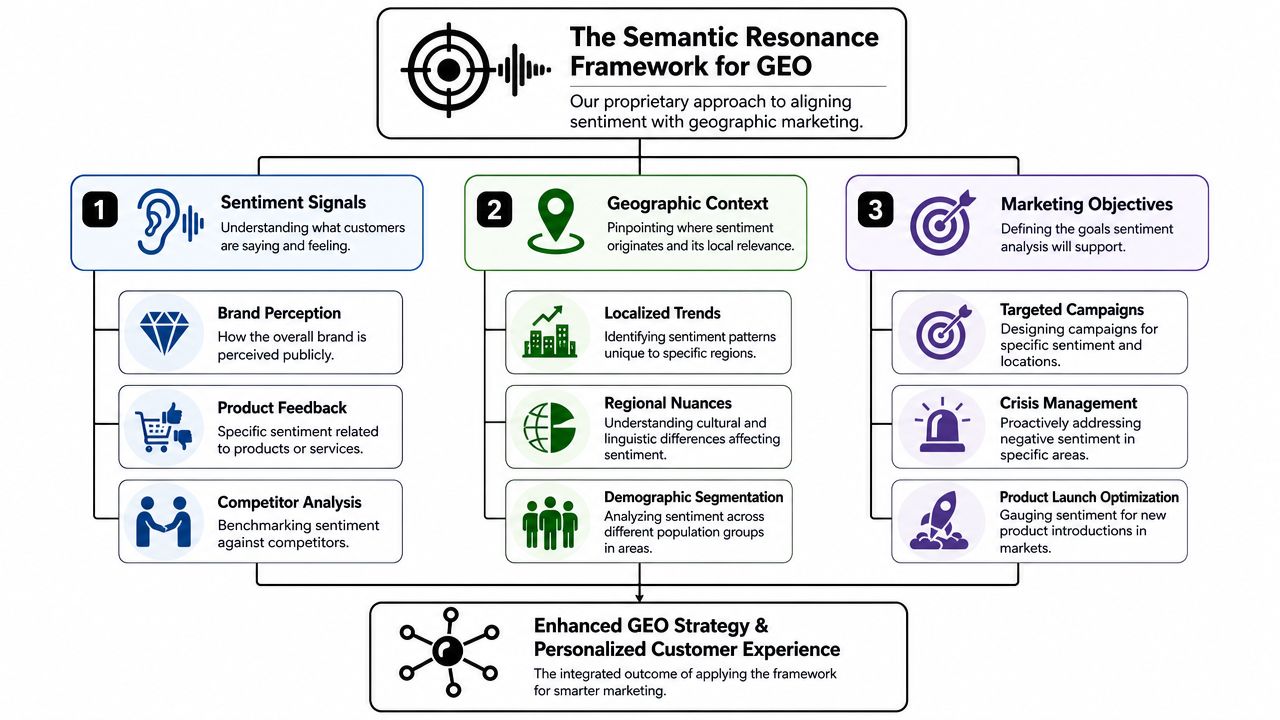
This paper uses the term Semantic Resonance for that broader condition. Semantic Resonance is the degree to which a brand-relevant claim is reinforced across contexts, sources, and language patterns in a way that an LLM can retrieve and summarize cleanly.
Three pillars determine resonance
Contextual alignment asks whether the same sentiment holds across related topics. A company described as helpful in onboarding but frustrating in billing does not have a stable trust signal. It has segmented perception. LLMs often compress segmented perception into simplified summaries, which means unresolved contradictions matter.
Source authority asks where the language appears. A recurring claim on a niche forum and the same claim in reputable editorial coverage do not carry the same retrieval weight in practice. Authority doesn't erase sentiment. It intensifies it.
Later in the evaluation cycle, teams should examine how these claims surface in answer engines alongside broader visibility work such as optimizing for AI Overviews.
Signal purity asks whether the phrasing is easy for models to interpret. Sarcasm, negation, slang, and brand-specific shorthand degrade interpretability. A noisy positive signal can be less useful than a clear neutral one if the model cannot resolve intent.
Resonance can be engineered
The framework changes the operating question from “How positive are mentions?” to “How consistently is the desired conclusion supported by interpretable evidence?”
That shifts execution in three ways:
Pillar | Weak state | Strong state |
|---|---|---|
Contextual alignment | Sentiment varies unpredictably across topics | Core claims remain consistent across topics and channels |
Source authority | Sentiment clusters in low-credibility environments | Sentiment appears in credible, citable environments |
Signal purity | Language is ambiguous or sarcastic | Language is specific, direct, and machine-legible |
A resonance-oriented team does not solely chase favorable mentions. It curates clearer evidence. It aligns product explanation, support language, review capture, and PR messaging so the same brand truths appear repeatedly in interpretable form.
A short explainer supports that point:
The strategic advantage is higher consistency between what the brand wants known and what the model can confidently infer.
Return to Chapter 1. Book a call with Algomizer if a team needs to audit brand resonance across AI-generated answers.
Chapter 5 A Contrast Between Monitoring and Engineering Sentiment
The operating model has changed
Legacy sentiment practice treats language as something to observe. GEO-era sentiment practice treats language as infrastructure that can be improved. The distinction changes budget allocation, workflow design, and executive expectations.
The following comparison captures the difference.
Dimension | Legacy Approach (Monitoring) | GEO Approach (Engineering) |
|---|---|---|
Primary goal | React to crises and track mood | Build citable truth that shapes AI answers |
Core unit of analysis | Mentions and polarity counts | Evidence clusters by topic, source, and interpretability |
Time horizon | Daily or weekly reporting | Ongoing perception design |
Main data posture | Broad collection with loose normalization | Standardized collection with source and topic discipline |
Team behavior | Report findings to stakeholders | Route findings into messaging, PR, CX, and content changes |
Success condition | Cleaner dashboard trendline | Stronger machine-readable brand narrative |
Risk model | Missed issue detection | Misframed AI synthesis and comparative disadvantage |
The KPI stack must change with it
The monitoring model creates a narrow loop. Gather reactions, score them, report them, and escalate outliers. That process is useful for incident response but weak for strategic differentiation.
The engineering model creates a different loop. Detect a pattern, connect it to a topic, validate whether the source environment is credible, correct language where necessary, and reinforce the intended narrative across public and owned touchpoints. That is closer to editorial systems design than to passive analytics.
For teams building that shift, a useful conceptual companion is engineering truth as a GEO framework.
A practical checklist clarifies the difference:
Legacy metric: Percent positive mentions. This is descriptive but shallow.
Engineering metric: Topic-level consistency across credible sources. This is directional and actionable.
Legacy intervention: Reply to negative posts after a spike.
Engineering intervention: Change onboarding copy, update help content, brief PR, and improve review capture prompts around the affected topic.
Legacy outcome: A calmer dashboard.
Engineering outcome: A more favorable comparative answer in AI search.
The strongest sentiment programs do not stop at listening. They redesign the language environment from which machine conclusions are drawn.
This contrast also explains why some brands appear to have good reputations internally but weak positioning externally. Their dashboards detect broad positivity, yet their public evidence remains fragmented. AI systems summarize the fragmentation, not the optimism of the internal report.
Return to Chapter 1. Book a call with Algomizer to compare a monitoring stack against an engineering-oriented GEO workflow.
Chapter 6 An Enterprise Roadmap for Sentiment-Driven GEO
Phase 1 and Phase 2 establish the data foundation
The highest-value execution pattern is to standardize data across channels, benchmark against competitors, and tie sentiment metrics to outcome-linked KPIs such as churn reduction or conversion performance, creating a closed loop between insight and business results (how to tie sentiment analysis to business KPIs).
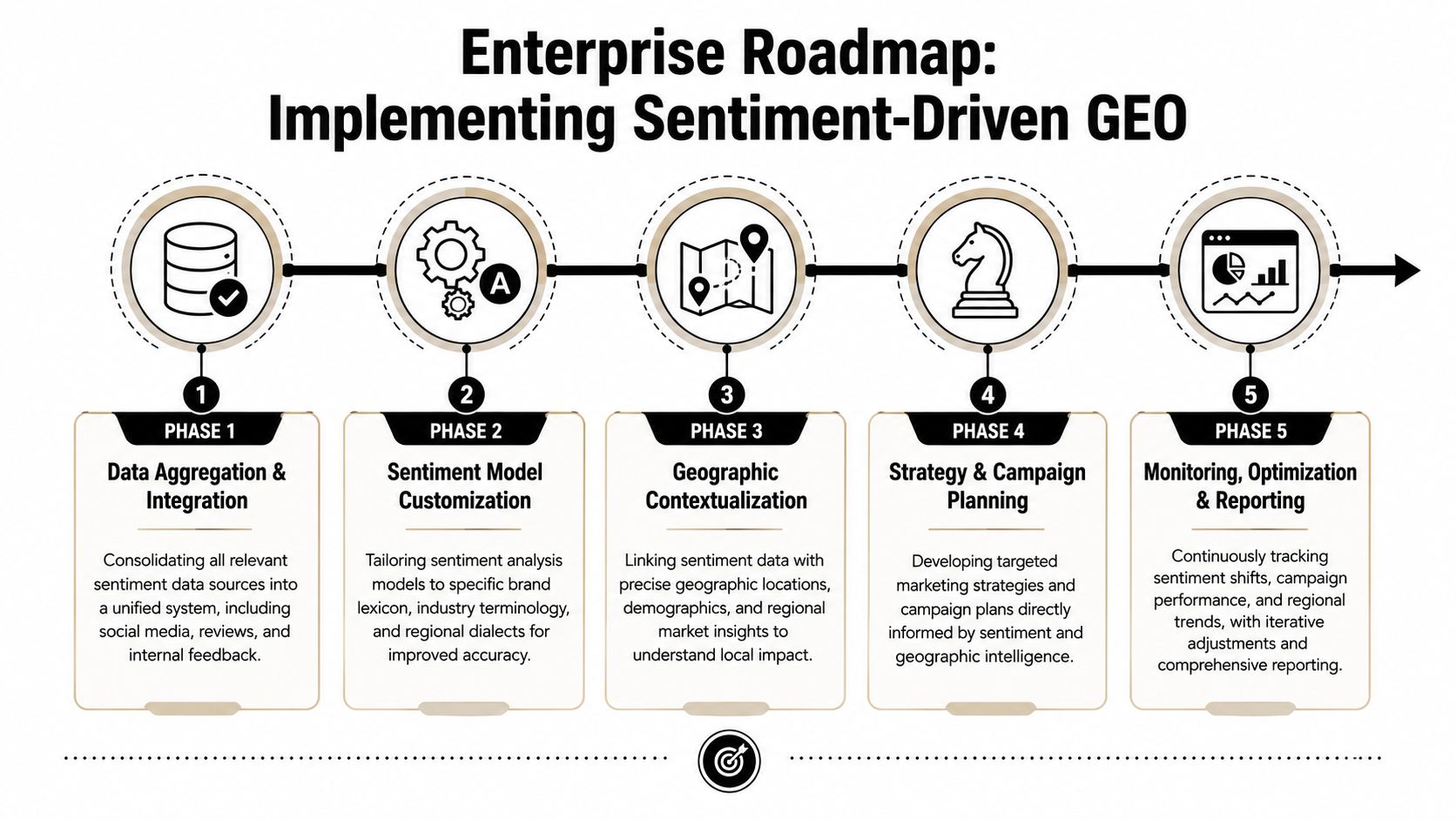
Phase 1 is data aggregation and baseline creation. Enterprise teams should unify reviews, social discussion, survey responses, support tickets, CRM notes where appropriate, and public editorial mentions into one normalized perception layer. The output is a baseline map of where the brand is discussed, how often sentiment can be captured, and where channel coverage is missing.
Phase 2 is model calibration and validation. Teams should test the model against industry-specific language, recurring product terms, ambiguity, negation, and sarcasm. Many programs fail at this point. They accept a general model output and treat it as truth, even though the actual requirement is domain fitness.
Phase 3 and Phase 4 turn analysis into workflow
Phase 3 builds the insight-to-action workflow. This means routing different classes of insight to different owners. Messaging issues go to product marketing. Repeated service complaints go to support leadership. Feature confusion goes to product and documentation teams. A good dashboard informs. A strong workflow assigns ownership.
Phase 4 integrates sentiment with AI visibility analysis. At this stage, the organization should compare internal sentiment patterns against how answer engines describe the brand in public prompts. That lets teams see whether internal improvements are surfacing in external machine narratives. For organizations evaluating citation quality across model outputs, reliable citation analysis for AI search engines is a useful operational reference.
A compact roadmap helps executive teams sequence investment:
Phase | Operational question | Main output |
|---|---|---|
Data aggregation | Where is sentiment being captured and missed? | Unified baseline |
Model calibration | Does the model understand the business language? | Validated classification logic |
Workflow design | Who acts on which insight? | Escalation and ownership map |
AI visibility mapping | Do public AI answers reflect intended perception? | Gap analysis between internal and external narrative |
KPI integration | Which sentiment shifts matter commercially? | Executive reporting tied to outcomes |
Phase 5 closes the loop with business outcomes
Phase 5 ties sentiment to CFO-relevant metrics. The program should not end with dashboards. It should connect topic-level sentiment movement to churn signals, conversion behavior, launch quality, or retention-related support themes.
A few implementation rules matter more than tool choice:
Standardize first: If source data uses different taxonomies, the team will produce noise at scale.
Validate before automating: Model outputs need spot checks before they trigger workflows.
Segment by journey stage: Early-funnel social buzz and late-funnel support frustration carry different strategic weight.
Benchmark comparatively: Relative perception often matters more than isolated brand sentiment.
One vendor category may include social listening platforms, VoC tools, BI layers, and specialized AI-search visibility platforms. In that mix, Algomizer can be used as one option for monitoring brand mentions in AI-generated answers and understanding how models interpret a brand, while broader sentiment systems handle intake and classification.
Enterprise sentiment analysis marketing becomes defensible when finance, marketing, CX, and product can all trace how a perception shift moved from raw language to business action.
Return to Chapter 1. Book a call with Algomizer to design a sentiment-driven GEO roadmap that connects model interpretation to measurable business outcomes.
Chapter 7 The Shift from Passive Listening to Active Shaping
Marketing leaders now manage machine-readable reputation
Passive listening belongs to an earlier digital environment. In the current environment, AI systems synthesize reality from distributed language signals. That makes sentiment a strategic input to discoverability, recommendation, and trust.
The progression across this paper leads to one conclusion. Sentiment analysis marketing is no longer a reporting discipline. It is a perception design discipline. The technical stack may involve NLP classification, topic modeling, dashboards, and alerting, but the executive task is broader. Leaders must decide which claims should become stable public evidence and then coordinate the operating functions that can make those claims true, visible, and interpretable.
A useful adjacent discipline is improving brand voice tone, because language consistency affects not only human trust but also how clearly machines can map a brand's attributes across channels.
The strategic question has changed
The old question was, “What are people saying about the brand?”
The better question is, “What will AI conclude about the brand from the available evidence?”
That reframing changes leadership behavior:
CMOs need sentiment governance, not just dashboard access.
Growth teams need to treat reviews, forums, support content, and editorial mentions as retrievable assets.
Product marketers need to align feature narratives with real customer language.
CX leaders need to understand that support interactions can become public brand evidence indirectly through downstream summaries and reviews.
The durable competitive advantage is cleaner, repeated, machine-readable proof.
This is the strategic shift from listening to shaping. Brands still need to detect dissatisfaction early. They also need to engineer clearer evidence around trust, quality, speed, support, and differentiation so that LLMs encounter coherent patterns rather than fragmented claims.
That is why the next frontier is better sentiment structure. Better coverage across channels. Better validation against nuance. Better connection between reaction and topic. Better alignment between what customers experience and what public language records.
The executive implication is decisive. If AI interfaces increasingly mediate discovery, then unmanaged sentiment becomes unmanaged visibility. Marketing leaders can't outsource that risk to a dashboard.
Return to Chapter 1.
If a team wants a clear view of how AI systems currently describe its brand, category, and competitors, it can book a call with Algomizer for a practical assessment of AI-generated visibility, citation patterns, and sentiment-linked perception gaps.