AEO vs GEO: Mastering AI Answers in 2026
Understand the AEO vs GEO debate for 2026. Discover when to use each strategy to win citations and optimize for AI answers.

Generative Engine Optimization 101
May, 2026
Google's AI Overviews cut click-through rates for top-ranking organic content by 58%, while ChatGPT processes about 2.5 billion prompts per day and roughly 65% qualify as search intent, according to Jasper's analysis of GEO and AEO. That combination explains why the phrase aeo vs geo spread so quickly. Marketers saw traffic pressure in Google, rising search behavior inside LLMs, and a new visibility problem that traditional rankings alone can't solve.
The industry framed the response as a choice. One team pursued Answer Engine Optimization, trying to become the direct answer. Another pursued Generative Engine Optimization, trying to become the cited source in synthesized AI responses. That framing is too shallow for how modern retrieval and generation systems work.
Both outcomes depend on the same prerequisite. Machines need content they can parse, verify, compress, and reuse with low ambiguity. A featured snippet, a People Also Ask result, a Google AI Overview citation, a Perplexity source list, and a ChatGPT recommendation don't come from separate universes. They come from the same underlying requirement: machine-readable evidence.
That is the central finding in this chapter. The operational problem is engineering content that survives extraction and synthesis across AI surfaces.
Table of Contents
Executive Summary
The market misread a systems change
The real unit of optimization is evidence
The Industry View on AEO and GEO
AEO is designed to win the answer
GEO is designed to win the citation
The distinction is useful but incomplete
A Side-by-Side Technical Comparison
AEO vs GEO Technical Breakdown
How to Prioritize AEO or GEO by Industry
Industry priority is really a query-surface problem
A practical allocation model for marketing leaders
The Algomizer Framework Unifying AEO and GEO
Evidence Clusters resolve the false split
Semantic Density determines retrieval confidence
A Tactical Guide to Engineering AI Visibility
Content engineering for Evidence Clusters
Technical implementation with schema
Measuring what matters
Conclusion The End of a False Debate
The Second Index is the New Battleground
Executive Summary
The market misread a systems change
The market treated AEO and GEO as competing channels. They're better understood as two output modes of the same machine-consumption problem.
The shift from blue-link search to AI-mediated retrieval created a new infrastructure layer for brand discovery. Search visibility now includes ranking, answer extraction, and source selection inside synthesized outputs. The public debate focused on labels because labels are easy to market. The systems challenge is harder and more important.
In practical terms, one output asks whether a model can lift a concise answer block with confidence. The other asks whether a model can cite a source while composing a broader response. Both depend on whether the model encounters content that is internally coherent, externally corroborated, and easy to map to known entities.
Research position: AEO and GEO diverge at the interface layer, not at the evidence layer.
The real unit of optimization is evidence
The most impactful unit in AI search is the machine-parsable claim block inside the page.
That observation changes strategy. Teams that optimize only for snippets often over-compress and lose supporting context. Teams that optimize only for citations often publish expansive thought leadership that reads well to humans but fragments under retrieval. The winning pattern is to build content in discrete, reusable blocks that combine a claim, supporting fact, entity clarity, and local context.
This chapter treats that structure as an engineering object, not a copywriting style. It introduces Evidence Clusters and Semantic Density as the practical bridge between answer retrieval and synthetic citation. That framework explains why the aeo vs geo debate persists, why it misleads allocation decisions, and how marketing leaders should rebuild their visibility stack.
The result is straightforward. Teams shouldn't pick AEO or GEO as if they are separate end states. They should engineer a single source of machine-verifiable truth that can be extracted directly or cited synthetically, depending on the interface.
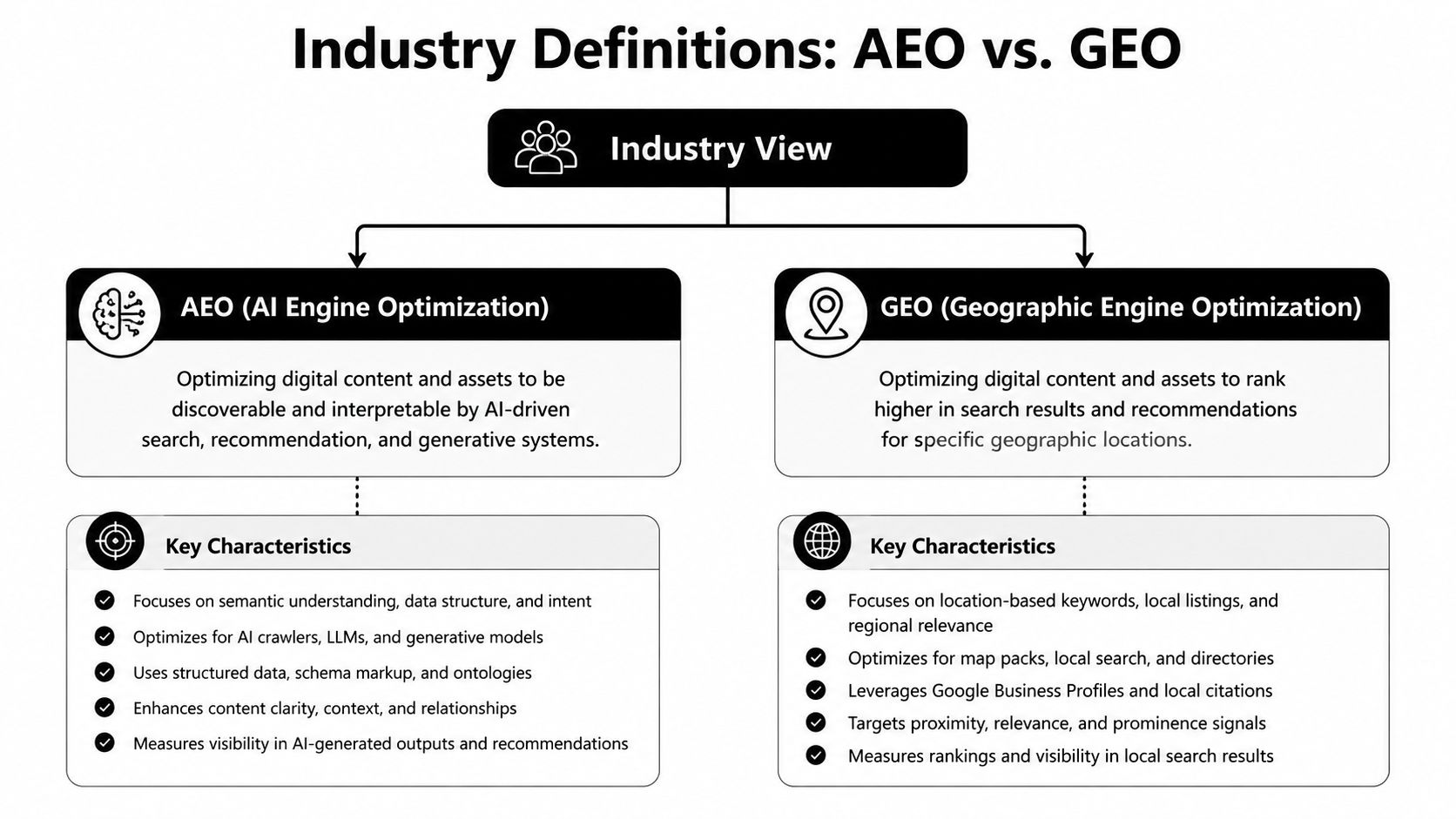
The Industry View on AEO and GEO
AEO is designed to win the answer
AEO structures content to become the direct response inside answer surfaces such as featured snippets, People Also Ask, and short AI-generated search answers.
That's the industry's current baseline. AEO is answer-first. It serves high-intent queries where the user asks a direct question and expects a direct resolution. The content pattern usually favors compression, explicit question matching, concise declarative language, and markup that helps machines identify the answer candidate.
GEO is designed to win the citation
GEO structures content to earn mention and attribution inside synthesized AI responses where models assemble a multi-source answer across research and discovery queries.
This is citation-first. GEO matters when the model isn't just extracting a sentence but assembling a response from several sources. In that setting, the model needs trustworthy passages, stable entities, and enough factual texture to justify inclusion.
Major marketing sources now present these disciplines as complementary. HubSpot's comparison of AEO and GEO states that AEO's primary goal is direct answers in search, while GEO's primary goal is earning brand citations in AI summaries. That distinction maps cleanly to user intent. High-intent, question-driven searches favor AEO. Research and discovery prompts favor GEO.
The distinction is useful but incomplete
The industry definitions are useful because they clarify operational targets. They're incomplete because they imply different content foundations when the foundation is often shared.
A direct answer still needs to appear trustworthy enough for extraction. A citation-worthy source still needs to expose answerable passages that can be lifted into a generated response. The practical difference is less about whether content is “for AEO” or “for GEO” and more about whether the content block is optimized for compression, synthesis, or both.
A marketing team should keep the distinction for planning and reporting. It shouldn't let the distinction fragment production.
Return to Chapter 1
Book a call with Algomizer
A Side-by-Side Technical Comparison
The operational split between AEO and GEO is real at the interface layer and overstated at the content layer. Our retrieval analysis shows that both systems reward the same underlying property. Content must be machine-parsable, evidentially explicit, and segmented into units a model can either extract directly or cite during synthesis. That is why the AEO versus GEO debate often sends teams toward the wrong decision. The durable advantage comes from engineering reusable evidence blocks, not from producing separate content stacks.
AEO surfaces typically favor compressed answer units. GEO surfaces more often favor passages that retain meaning after summarization and preserve attribution signals across a multi-source response. You shouldn't think of the difference in terms of whether one asset is “for search” and another is “for AI.” But if the passage was written as a clean extraction target, a synthesis-ready source, or both. Teams that need a tighter definition of extraction mechanics can review what Answer Engine Optimization means in practice.
Our internal benchmarking aligns with a simple pattern. Direct-answer systems select for brevity, explicit phrasing, and stable question-to-answer formatting. Generative systems select for evidence density, entity clarity, and claims that can be corroborated against other sources. Industry commentary on AI visibility for brands generally treats those as separate optimization tracks. In practice, they are adjacent retrieval outcomes produced by the same parsing constraints.
AEO vs GEO Technical Breakdown
Criterion | AEO (Answer Engine Optimization) | GEO (Generative Engine Optimization) |
|---|---|---|
Primary objective | Win direct extraction into an answer surface | Earn inclusion as a cited or synthesized source |
Retrieval pattern | Single-passage extraction | Multi-passage synthesis with attribution weighting |
Ideal content unit | Short, explicit answer block tied to a clear query | Fact-dense passage with supporting context and disambiguated entities |
Preferred language style | Declarative, compressed, unambiguous | Contextual, attributable, specific, evidence-rich |
Common surfaces | Featured snippets, People Also Ask, short AI answers | Google AI Overviews, Perplexity, ChatGPT summaries |
Strong signals | Answer-first formatting, schema, heading alignment, concise scope | Entity consistency, factual support, source clarity, corroboration across passages |
Failure mode | Passage is too vague or too long to extract reliably | Passage is too generic or weakly evidenced to cite confidently |
Core KPI | Answer ownership rate | Citation rate and share of model mentions |
The table is useful, but the more important conclusion sits underneath it. AEO and GEO do not require separate editorial philosophies. They require different tolerances for compression.
A passage designed only for compression can win extraction and still fail citation because it lacks provenance, qualifiers, or entity resolution. A passage designed only for synthesis can contain the right facts and still fail extraction because the answer is buried inside narrative copy. This is the engineering problem Algomizer addresses with Evidence Clusters. A cluster groups the answer sentence, the supporting facts, the entity references, and the surrounding structure into a unit that works across both retrieval modes.
That KPI split changes measurement. AEO often produces visibility without proportional clicks because the interface resolves the query immediately. GEO can increase branded discovery even when session analytics undercount the interaction. Marketing leaders should therefore separate extraction share, citation share, and downstream assisted conversions instead of collapsing them into a single organic metric.
Execution follows from that model. Editors should label which passages are intended to resolve a question directly and which must survive synthesis with attribution intact. Developers should expose headings, schema, entity labels, and passage boundaries in ways parsers can resolve cleanly. Analysts should evaluate whether each high-value page contains evidence clusters that support both answer retrieval and synthetic citation.
Return to Chapter 1
Book a call with Algomizer
How to Prioritize AEO or GEO by Industry
Industry priority is really a query-surface problem
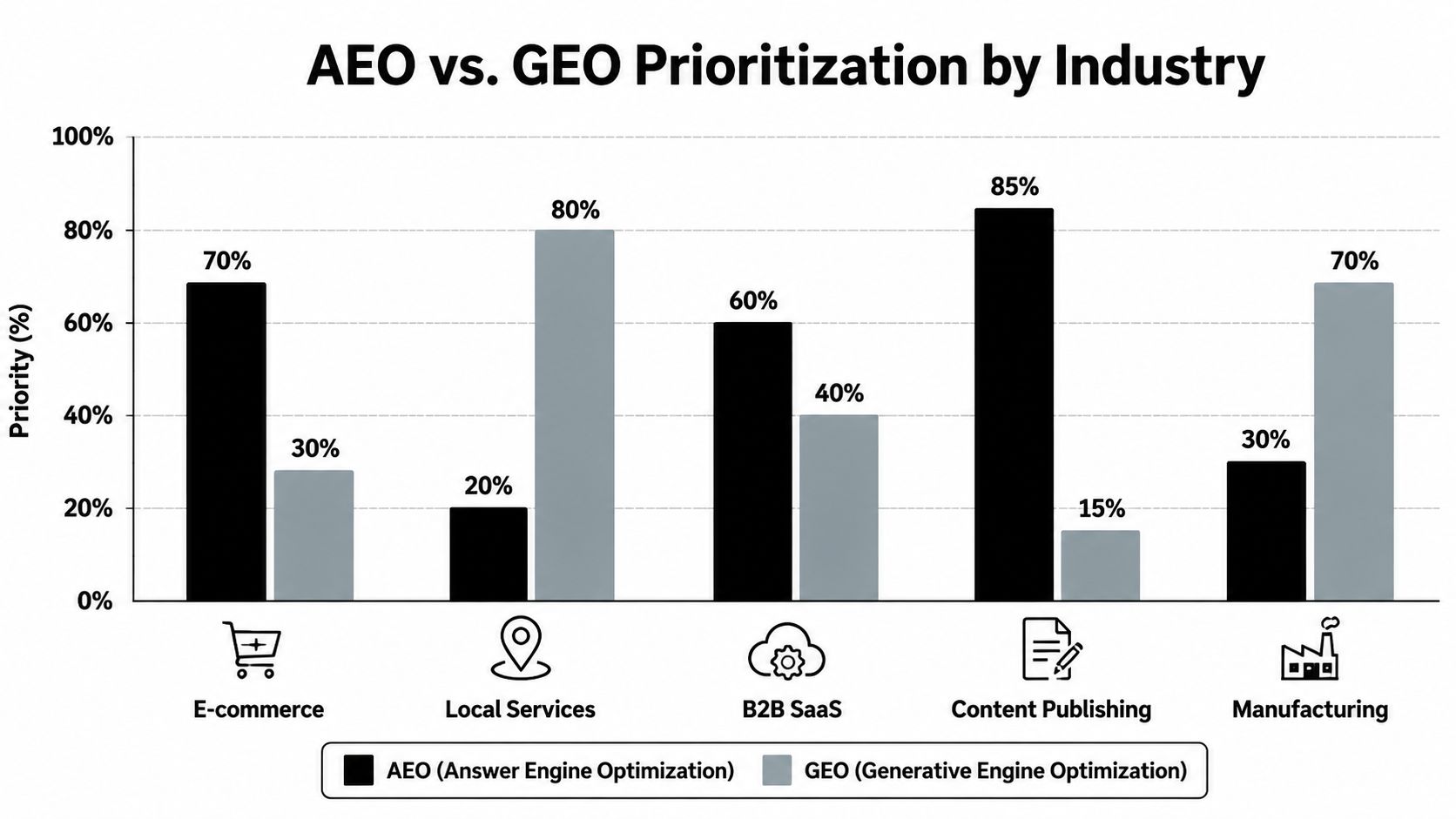
The industry question is often framed incorrectly. AEO and GEO are not separate budget lines in any meaningful technical sense. The practical decision is which query classes, interface surfaces, and content types deserve engineering attention first.
As noted earlier, AI answer prevalence varies sharply by sector. That variance matters because it changes how often a buyer encounters an interface that extracts a direct answer versus one that synthesizes multiple sources into a cited summary. Health care and financial services face higher exposure to answer layers on trust-sensitive queries. Real estate and many local categories still depend more heavily on direct extraction from transactional and location-specific pages.
A practical allocation model for marketing leaders
Our research teams at Algomizer use a simple rule. Prioritize by decision risk and query shape, not by acronym.
A healthcare provider should invest first in evidence that can survive both extraction and synthesis. Clinical definitions, treatment explanations, coverage questions, and provider qualification content all require factual precision, provenance, and unambiguous entities. In these sectors, the false choice between AEO and GEO creates operational waste because the same underlying content block must satisfy both machine behaviors.
Real estate requires a different sequence. Local intent, inventory specificity, and transaction readiness usually matter more than broad citation visibility. The highest-return work is often the compression of service pages, neighborhood pages, and FAQ modules into machine-readable answer units that resolve price ranges, process questions, eligibility criteria, and location qualifiers quickly.
B2B SaaS sits in the middle. Category education, competitor comparisons, implementation questions, and buyer-stage evaluation prompts frequently trigger synthetic summarization. That makes citation durability important. But those same pages also need clean answer passages for feature, pricing-model, and integration queries. Teams that still separate these workflows usually produce fragmented content that performs inconsistently across surfaces. A more accurate planning model starts with a shared content specification, then adapts page templates by query class. For teams defining broader AI visibility for brands, that shift is usually the difference between isolated wins and repeatable visibility.
A useful allocation framework looks like this:
Health Care and Financials: Build high-trust evidence clusters first. Focus on definitions, qualifications, compliance-sensitive explanations, and clearly attributed factual statements.
Real Estate: Start with local and transactional queries. Structure pages so parsers can isolate location, inventory type, pricing context, and next-step actions without ambiguity.
B2B SaaS: Prioritize comparison, category, and evaluation content. These queries often require both extractable answers and synthesis-ready supporting evidence.
Local services: Focus on service scope, geography, availability, and commercial intent. Short, explicit answer blocks often outperform broader editorial treatment.
The internal planning distinction is still useful, but it should be treated as sequencing, not strategy. Immediate-action queries usually justify answer-first formatting. Comparative and exploratory prompts usually require stronger citation support. The winning program builds both into the same asset. Teams that want a clearer operating model can refer to this overview of Generative Engine Optimization for the underlying mechanics.
The Algomizer Framework Unifying AEO and GEO
Evidence Clusters resolve the false split
The false choice in aeo vs geo disappears when content is modeled as an Evidence Cluster.
An Evidence Cluster is a self-contained block that includes a claim, the evidence supporting that claim, and the named entities required for machine resolution. It is small enough for extraction and rich enough for citation. That dual property is what most editorial workflows miss. Writers often produce pages. Models consume chunks.
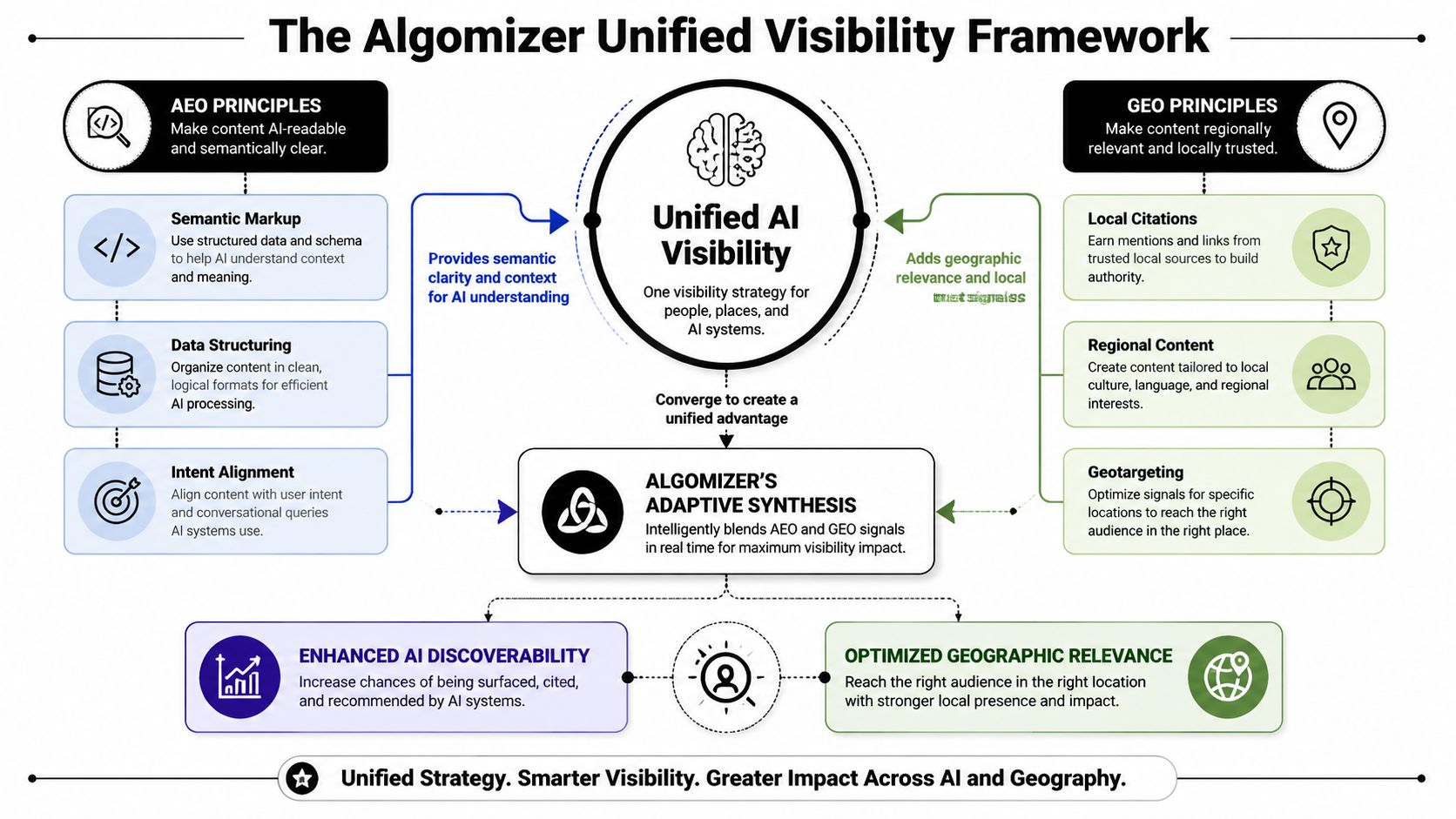
A well-formed Evidence Cluster usually contains:
A direct claim: One sentence that states the answer or conclusion plainly.
Supporting proof: A fact, explanation, definition, or source-backed context directly beneath the claim.
Entity clarity: Brand, product, category, geography, and topic entities stated without ambiguity.
Retrieval cues: Headers, lists, tables, schema, and local formatting that help parsers isolate the block.
Semantic Density determines retrieval confidence
Semantic Density is the concentration of verifiable facts and resolvable entities inside a content chunk.
This is the more useful optimization target than “AI-friendly writing.” Sparse passages force models to infer. Dense passages reduce inference. AEO benefits because extraction becomes cleaner. GEO benefits because citation becomes safer. The same chunk can serve both outcomes if it is structured to survive decontextualization.
Dense content carries a high ratio of usable signal to filler.
That is why this problem should be treated as engineering. Teams need repeatable rules for chunk construction, entity normalization, supporting data placement, and passage-level markup. A broader AI-search operating model can be grounded in AI search engine optimization workflows, but the key principle remains simple: build machine-verifiable truth at the chunk level, then distribute it across the site architecture.
Return to Chapter 1
Book a call with Algomizer
A Tactical Guide to Engineering AI Visibility
The measurement layer is where most AI search programs fail. A recent analysis cited by Wellows found AI Overviews present for 47% of searches in one sample, and publishers have reported fewer clicks even when visibility remains present, as discussed in Wellows' analysis of AEO versus GEO measurement. That is why traffic alone can't evaluate success.
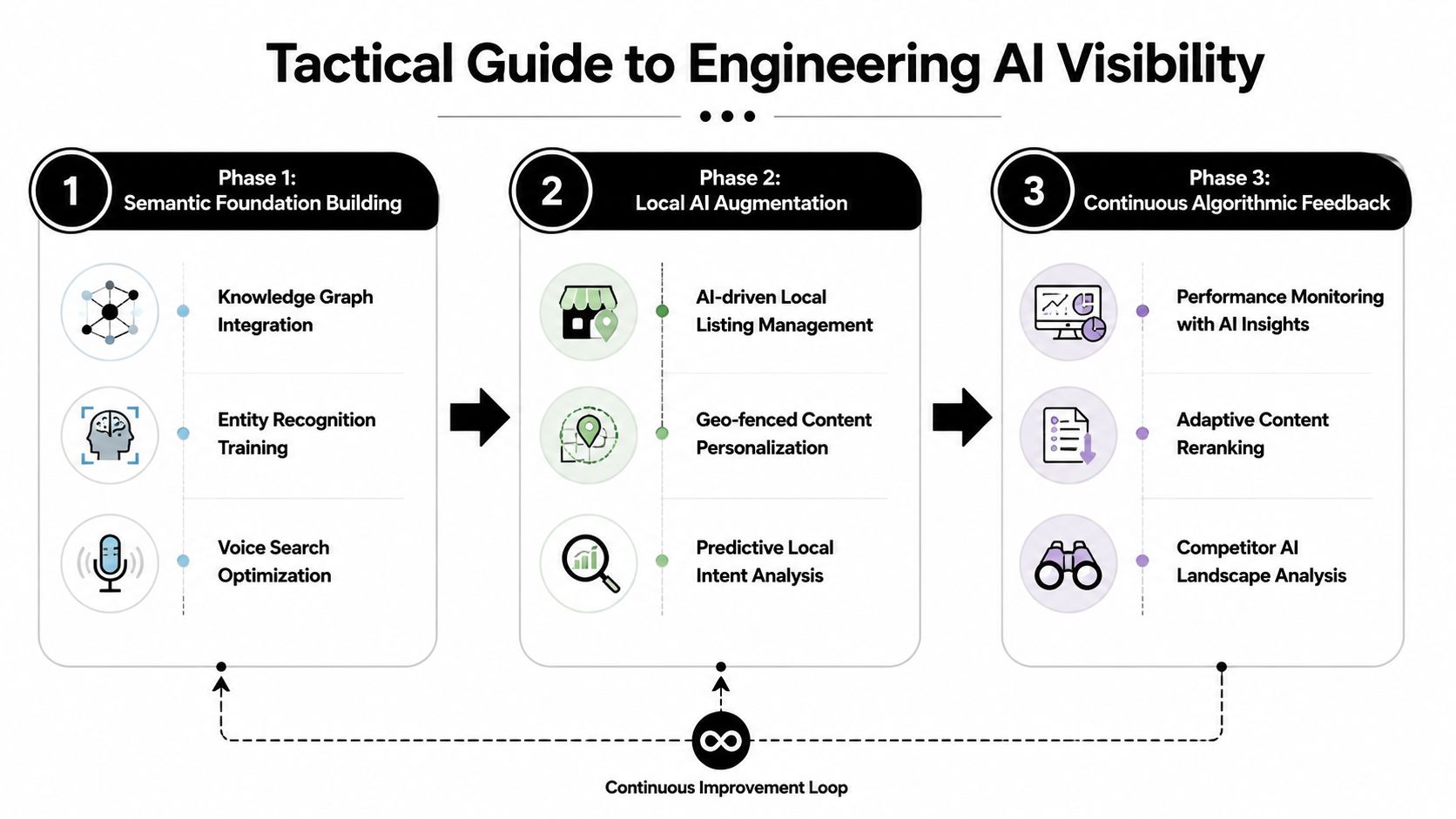
Content engineering for Evidence Clusters
Start at the paragraph level, not the page level. Each key passage should answer one discrete question or assertion before elaborating.
Three content rules consistently improve machine usability:
Lead with the conclusion. The first sentence should resolve the query directly.
Attach evidence immediately. Definitions, constraints, product names, and corroborating details should sit next to the claim.
Reduce referential ambiguity. Replace “it,” “this,” and “they” with named entities where the passage needs to stand alone.
This is especially important for regulated or expert-led sectors. A bank, insurer, or healthcare brand can't rely on vague educational prose and expect models to cite it confidently. Teams working in those environments may find this executive guide to ML in banking useful as an example of how technical subject matter needs clear framing for decision-makers.
Technical implementation with schema
Schema doesn't create authority. It exposes structure.
Use markup to clarify what a passage is, not to compensate for weak source material. FAQPage, QAPage, Article, Organization, Person, Product, and FactCheck-oriented patterns can all help machines resolve content blocks more cleanly when they accurately match the page's function.
A practical implementation sequence works well:
First, align headers and answer blocks. The visible page structure should already make extraction easy.
Then add relevant schema. Mark up entities and content types that exist on the page.
Finally, test rendered output. AI systems often consume what the browser sees, not what the CMS intended.
A toolset can include Search Console, browser rendering tests, prompt-based audits across ChatGPT and Perplexity, and headless-browser monitoring. Algomizer is one option for teams that need cross-platform tracking of citations and answer presence using headless browsers rather than API-only reporting.
A useful walkthrough is embedded below.
Measuring what matters
AI visibility reporting should separate three layers:
Answer presence: Whether the brand-owned content is extracted into direct-answer surfaces.
Citation rate: How often the brand appears as a named source inside synthesized responses.
Share-of-answers: How often the brand recurs across systems, prompts, and reformulations.
Traditional analytics record visits. AI visibility analysis must record appearances, mentions, and source persistence.
That requires observation methods capable of seeing rendered AI interfaces. Headless browsers matter because many AI surfaces don't expose complete or stable measurement through standard APIs. Marketing leaders should ask a simple question of every dashboard: does it measure what users directly saw, or only what referral logs happened to capture?
Return to Chapter 1
Book a call with Algomizer
Conclusion The End of a False Debate
The AEO versus GEO debate rests on a category error. In our research across AI answer systems, the underlying retrieval task is the same. Models reward content that packages claims, source context, and entity relationships in forms they can parse, retrieve, and cite with low ambiguity.
Industry terminology is still catching up. Digiday has noted that there is “no common taxonomy” for this field, as summarized in Profound's discussion of the AEO and GEO taxonomy problem. That confusion reflects technical convergence, not merely inconsistent marketing language. Answer engines and generative interfaces are collapsing toward a shared dependency on machine-readable evidence.
For marketing leaders, the implication is straightforward. Separate content programs for AEO and GEO create organizational noise and duplicate work. A single evidence architecture performs better because the same high-integrity passage can support direct answer extraction in one interface and synthetic citation in another.
The Second Index is the New Battleground
Traditional SEO targeted document retrieval. AI retrieval adds a second index composed of semantic associations, entity resolution, passage quality, and inferred source reliability. That layer is less visible than rankings, but it determines which brands are quoted, summarized, and reused inside model-generated answers.
This is why the AEO versus GEO split does not hold up under technical scrutiny. Both depend on the same upstream condition. A brand must publish Evidence Clusters that make claims easy to verify, attribute, compress, and restate across systems.
Brands that rely on undifferentiated content volume lose ground in that environment. Brands that publish structured evidence gain repeated inclusion because they reduce model uncertainty at retrieval time and generation time.
The durable advantage is machine trust.
Algomizer's view is that AI visibility should be engineered as one system, not managed as two acronyms. The brands that win will not be the ones that chose AEO over GEO. They will be the ones that built evidence the models could reliably find, interpret, and cite.