Your 2026 Playbook for LLM Search Optimization
Master LLM search optimization with our 2026 playbook. Win AI visibility using proven content & technical strategies.

An Algomizer Research Paper
May 2026
Search didn't start dying when rankings slipped. But when answers stopped needing a click.
In 2025, Google AI Overviews appeared in approximately 18% of all Google searches, and those AI-mediated results coincided with click-through-rate declines of 15% to 30% for AIO-triggering keywords, according to the compiled analyses summarized by Seenos on LLM optimization metrics. That single shift changed the unit of competition from the ranked page to the cited passage.
For CMOs, that means the operating model has already changed. Teams still optimizing around rankings, sessions, and blue-link share are measuring a discovery system that users increasingly bypass. Teams that understand model recall, source selection, and answer synthesis are engineering the new front door to demand.
That's why llm search optimization isn't a niche SEO variation. It's a separate discipline with different incentives, different failure modes, and different measurement logic. It starts from the architecture of retrieval and synthesis, then works backward into content design, technical deployment, and governance.

Marketing leaders that already manage complex content ecosystems can see the adjacent challenge in enterprise content discovery with Sitecore Search. Discovery now depends on how systems interpret information structures, not just how humans browse them. The same pattern applies more aggressively inside AI interfaces.
A useful starting point for that shift sits in Algomizer's analysis of search marketing intelligence, where the core issue becomes clear. Visibility now depends on what a model can retrieve, trust, compress, and cite.
Table of Contents
Executive Summary The End of Search As We Know It
Rankings no longer define visibility
The market has entered the citation era
Deconstructing LLM Recall and Citation Behavior
Models retrieve chunks, not brand narratives
Citation behavior follows machine incentives
The Algomizer Framework Evidence Clusters and Semantic Density
Semantic Density determines whether a chunk is liftable
Evidence Clusters create model confidence
Content Engineering for Model Consumption
Priority Discovery identifies winnable prompts
Snippet engineering turns depth into citations
Technical Deployment for Machine Readability
Structured data reduces ambiguity
Canonical systems protect source integrity
Measurement Verification and Governance
Legacy analytics obscure AI performance
Governance requires verified sampling and refresh logic
Conclusion: The New Model of Discovery
Executive Summary The End of Search As We Know It
Search has already split into two markets. One market still measures ranked pages and visits. The other decides which sources get absorbed into machine-generated answers before a click exists.
That shift is no longer theoretical. Earlier research cited in this article found broad adoption of AI answer interfaces and measurable click loss on queries where generated summaries appear. For CMOs, the implication is straightforward. Organic visibility can rise on a dashboard while brand influence falls inside the answer layer.
We see this as a measurement failure first and a traffic problem second. Legacy SEO metrics were built for link selection. LLM search optimization is built for source selection. Those are different systems with different incentives, and they reward different forms of content quality.
Rankings no longer define visibility
A top-ranking page still matters, but rank is no longer the cleanest proxy for discovery. Google AI Overviews, ChatGPT, Gemini, Claude, and Perplexity often compress multiple sources into one response. The commercial question changes with them. We no longer ask only whether a page appeared. We ask whether the model retrieved our material, trusted it, and used it.
That distinction is where many executive teams misallocate budget. They continue funding page-level competition while the model evaluates passage-level usefulness. In our research, this is the core break between legacy search performance and AI visibility performance.
Operational shift: The competitive unit is now the retrievable content fragment, not the page as a whole.
This change also explains why some brands with strong domain authority underperform in AI answers, while narrower publishers with clearer source material appear disproportionately often. Citation behavior is not a simple extension of rank. It is a confidence decision made under compression.
For teams building search marketing intelligence for AI-era discovery, the practical requirement is to instrument visibility where the answer is assembled, not only where the results page is rendered.
The market has entered the citation era
LLM search optimization is the discipline of increasing the probability that a brand's content is retrieved, selected, synthesized, and cited inside generated answers. We treat it as a systems problem. The work starts by reverse-engineering recall behavior, then shaping content so the model can verify, extract, and reuse it with low ambiguity.
This is why we have moved beyond legacy SEO scorecards and toward two proprietary constructs: Evidence Clusters and Semantic Density. Together, they describe whether a source gives a model enough local proof to trust a passage and enough informational compression to lift it into an answer. That is the core competition.
The broader technology stack points in the same direction. Enterprise teams have spent years improving internal retrieval and structured knowledge access through systems such as enterprise content discovery with Sitecore Search. Public-facing AI discovery now applies similar logic to external content. Retrieval quality, structural clarity, and source consistency determine who gets represented.
The immediate risk is strategic, not cosmetic. A brand can keep publishing, keep ranking, and keep reporting healthy impression volume while losing the first moment of consideration to a model that resolved the user's question with someone else's evidence.
We should treat citation share as a board-level visibility metric. Once the answer layer mediates discovery, the source that gets cited shapes preference before the visit, before the demo request, and often before the category shortlist exists.
Deconstructing LLM Recall and Citation Behavior
LLMs don't “search” the way traditional engines do. They retrieve, score, compress, and then generate.
That difference matters because optimization fails when teams target the wrong machine behavior. A ranking engine evaluates pages against query signals and link structures. A retrieval-augmented generation stack evaluates whether specific passages can help answer a prompt with minimal ambiguity and acceptable confidence. The visible output looks conversational. The underlying process is mechanical.
Models retrieve chunks, not brand narratives
The first break from traditional SEO is granularity. Retrieval systems don't prefer pages because they exist as pages. They prefer chunks because chunks are easier to compare, rank, and assemble into a final answer.
A long article can still perform well, but only if it contains extractable units. Those units usually share four traits:
Declarative clarity: The passage answers a question directly instead of circling it.
Conceptual completeness: The surrounding text defines the idea, its context, and its boundaries.
Low ambiguity: Terms stay stable. Claims don't conflict across neighboring passages.
Machine legibility: Headings, lists, tables, and schema reduce interpretive work.
This is why sprawling thought-leadership prose often underperforms in AI citations. It may persuade a reader, but it gives the model very little clean material to lift.
A closer treatment of cross-platform source validation appears in Algomizer's work on reliable citation analysis for AI search engines. The key lesson is straightforward. Retrieval systems reward content that can survive extraction.
Citation behavior follows machine incentives
Three stages usually matter most.
First, the system retrieves candidate material that appears semantically related to the prompt. Second, it scores those candidates for relevance, consistency, and usefulness. Third, it synthesizes a response while minimizing conflict and uncertainty. Brands don't win because a model “likes” them. They win because their information makes answer construction easier.
That produces a very different incentive map from legacy SEO.
Stage | What the system wants | What it tends to avoid |
|---|---|---|
Retrieval | Passages tightly aligned to prompt intent | Broad pages with weak local relevance |
Relevance scoring | Specific, stable language and verifiable claims | Contradictory wording and fuzzy positioning |
Synthesis | Snippets that combine cleanly with other evidence | Marketing copy that introduces noise |
A model cites what reduces answer risk. It ignores what increases synthesis cost.
That has a direct strategic implication for content teams. Brand messaging can't remain loosely distributed across product pages, blogs, docs, and off-domain mentions with slight wording differences. In AI environments, inconsistency doesn't just confuse prospects. It degrades machine confidence.
The organizations that outperform in llm search optimization don't merely publish more. They create coherent source material that a model can retrieve without having to reconcile internal disagreement. That requirement leads to a new content model built around evidence structure and semantic concentration.
Return to Chapter 1. Book a complimentary AI visibility assessment with the team at Algomizer.
The Algomizer Framework Evidence Clusters and Semantic Density
Winning citations requires two conditions. A model must find the right passage, and it must trust the passage enough to use it.
That is the basis of the Algomizer framework. It replaces outdated SEO abstractions with two operational concepts built for answer engines: Semantic Density and Evidence Clusters. Keyword density and domain authority described an index-and-rank era. These two concepts describe a retrieve-and-synthesize era.
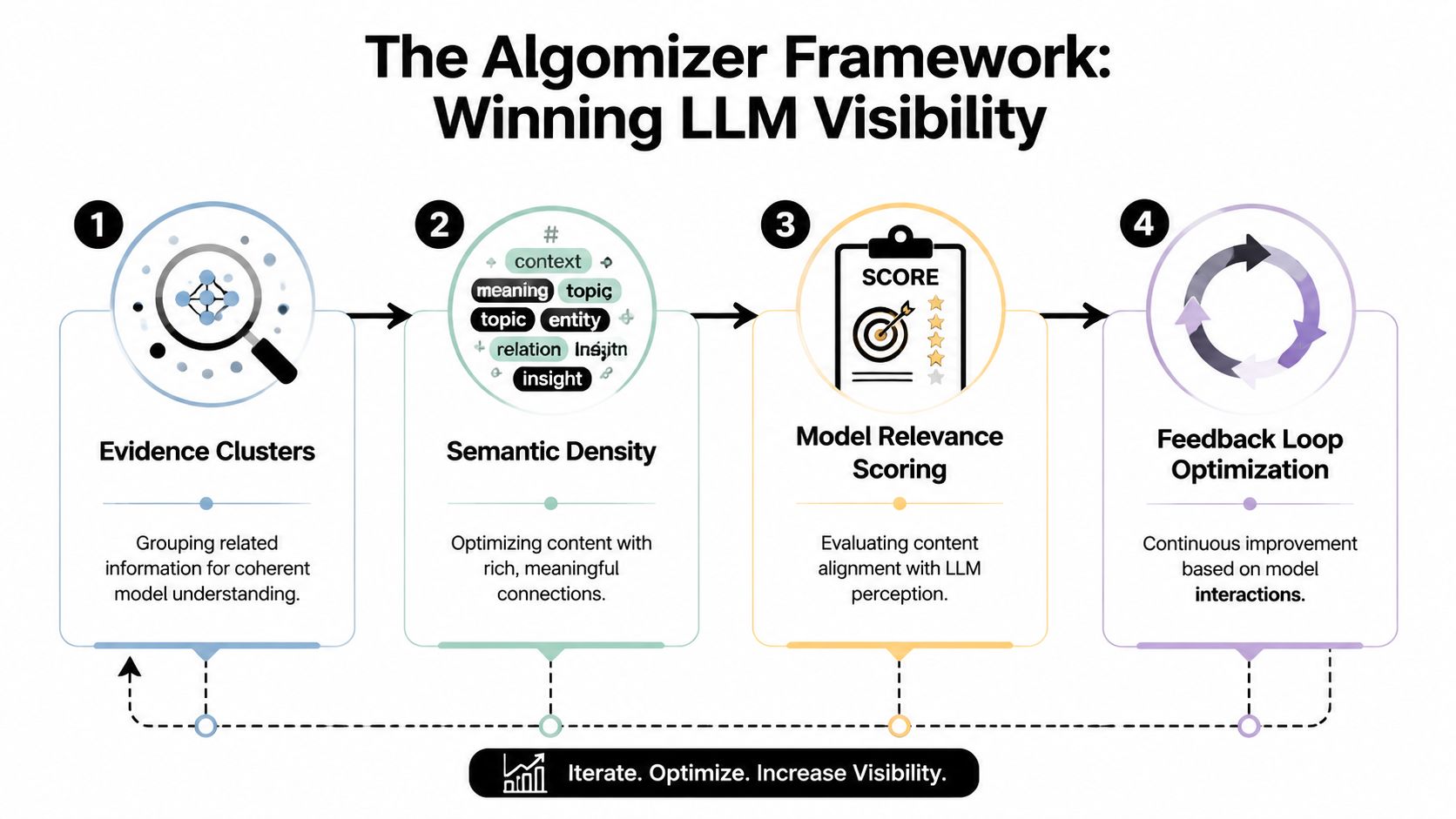
Semantic Density determines whether a chunk is liftable
Semantic Density is the concentration of useful meaning inside a passage. High-density content gives a model precise definitions, specific context, bounded claims, and language stable enough to quote or paraphrase. Low-density content pads around the point.
In practice, high Semantic Density looks like this:
The answer arrives early: The first sentence resolves the question instead of teasing it.
Terms stay fixed: A company doesn't call the same capability three different names across one page.
Examples support interpretation: Tables, FAQs, and tightly written summaries reduce ambiguity.
Claims remain scoped: The content says what is true, for whom, and under what conditions.
This is not a style preference. It is a retrieval advantage. A dense passage lowers compression loss when a model converts source material into an answer.
Evidence Clusters create model confidence
Evidence Clusters are networks of corroborating signals around a topic. They include primary site content, supporting documents, consistent terminology across assets, and credible third-party references that reinforce the same semantic position.
A single page can be clear and still fail if the rest of the ecosystem sends mixed signals. Evidence Clusters solve that problem by aligning the topic across the environment rather than isolating it on one page.
Board-level implication: AI visibility is not won by one “hero page.” It is won by a consistent evidence system.
The contrast with legacy SEO is easier to see side by side.
Metric | Traditional SEO (Obsolete Model) | LLM Optimization (New Paradigm) |
|---|---|---|
Core unit | Web page | Content chunk |
Primary signal | Keyword targeting | Semantic alignment |
Authority model | Domain-level accumulation | Topic-level evidence consistency |
Optimization target | Rank position | Citation eligibility |
Content habit | Volume and coverage | Precision and extractability |
Failure mode | Poor rankings | Omission from generated answers |
A useful conclusion follows from this framework. Many brands aren't losing AI visibility because their content is weak in the usual sense. They are losing because their knowledge is too diffuse for a model to compress confidently.
That is where tool choice becomes practical. Services such as Algomizer focus on reverse-engineering visibility across systems like ChatGPT, Claude, Gemini, and Perplexity by combining content engineering, media placement, and verification workflows. The important point isn't the vendor category. It's the method. Citation performance improves when teams design for evidence coherence instead of page-by-page publishing.
Return to Chapter 1. Book a complimentary AI visibility assessment with the team.
Content Engineering for Model Consumption
Content wins citations when it answers a prompt in the form a model can reuse.
That requires a production discipline different from standard editorial planning. Teams need to identify where answer engines are likely to retrieve, then build assets that maximize semantic completeness without burying the usable passage. The empirical support is unusually clear here. According to ALM Corp's analysis of over 15,000 AI Overview results, Semantic Completeness had the highest correlation with citation at 0.87, and content scoring 8.5/10 or higher achieved a 340% higher inclusion rate in AI-generated answers.
Priority Discovery identifies winnable prompts
Many organizations begin with keywords. That's too blunt. Priority Discovery starts with prompts, answer shapes, and citation gaps.
A practical workflow looks like this:
Map the commercial question set. Focus on prompts buyers ask before shortlist formation, during vendor comparison, and at objection points.
Inspect current answer behavior. Review how ChatGPT, Perplexity, Gemini, and Google AI Overviews currently frame the topic.
Find narrative absences. If the answer is generic, outdated, or missing a critical distinction, there is room to publish a superior source.
Build audience-specific pages. Granular pages aimed at a defined use case often outperform general category summaries in citation environments.
Teams looking to expand prompt libraries often benefit from adjacent ideation workflows. Bulby's insights on AI brainstorming are useful here because brainstorming quality affects question discovery, angle selection, and content decomposition before production ever starts.
Snippet engineering turns depth into citations
Depth matters, but extractability decides whether depth becomes visibility. That's the practical implication of the Semantic Completeness finding.
Pages built for llm search optimization should include:
Direct-answer openings: The first paragraph should state the answer cleanly.
Atomic sections: Each subsection should work as a standalone explanation.
Structured support: FAQs, lists, definitions, and comparison tables reduce model effort.
Evidence placement: Facts should sit inside the most likely cited passage, not buried at the end.
Content shouldn't force the model to infer the answer from the whole page. The answer should already exist in a reusable form.
For teams translating this into execution, Algomizer's guide to optimizing for AI Overviews offers a useful companion reference on shaping passages for generated-answer surfaces.
The production pattern is easier to visualize in motion:
The deeper conclusion is strategic. Human readability and machine readability aren't in conflict here. A page that resolves intent clearly, names the concept precisely, and structures evidence well becomes easier for both the model and the buyer to trust.
Return to Chapter 1. Book a complimentary AI visibility assessment with the team at Algomizer.
Technical Deployment for Machine Readability
Strong content still loses when delivery layers obscure meaning or fragment source truth.
Technical deployment for llm search optimization is narrower and more consequential than general technical SEO. The issue isn't merely whether a crawler can access a page. The issue is whether an AI retrieval system can parse the right version, identify the relevant entity, and separate fact from layout noise.
Structured data reduces ambiguity
Schema markup works because it tells the machine what the content is, not just what the words say. FAQ, HowTo, Product, and related structured formats are especially useful because they package assertions into predictable fields.
That matters for retrieval systems that need to interpret content at scale under uncertainty. Clean structure reduces the chance that the model misclassifies a definition, confuses a support page with a product page, or misses the exact answer embedded in a dense layout.
A practical AI-readiness audit should review:
Schema coverage: Key commercial and informational templates should expose their primary facts clearly.
HTML clarity: Important claims should appear in server-delivered, parseable markup.
Heading logic: H1, H2, and H3 structure should reflect conceptual hierarchy, not visual styling alone.
Snippet surfaces: FAQs, tables, and definitions should be present where answer extraction is likely.
Canonical systems protect source integrity
Canonicalization matters more in answer environments because duplicative or conflicting pages dilute machine confidence. If multiple URLs explain the same concept differently, a model has to choose between them or ignore both.
The right approach is to create a single source of truth for each important entity, product concept, or category definition, then support it with tightly aligned secondary pages. This is less about link equity than semantic discipline.
For teams publishing at scale in WordPress-heavy environments, senior-engineered WordPress markdown tools can help enforce cleaner source formatting and AI-ready content workflows. The value is operational consistency. Models parse what engineering ships, not what brand teams intended.
Machine readability is a governance issue disguised as a markup issue.
That distinction matters for enterprise teams. The technical layer doesn't create authority by itself, but it determines whether authority remains legible once content reaches retrieval systems.
Return to Chapter 1. Book a complimentary AI visibility assessment with the team at Algomizer.
Measurement Verification and Governance
Traditional dashboards misread AI visibility because they track visits after the answer, not influence inside the answer.
That makes governance the most underdeveloped part of llm search optimization. Teams often report rankings, organic sessions, and assisted conversions while missing the metrics that describe how often a brand appears in generated answers, where it appears, and whether citation quality is improving. The measurement model has to shift from page performance to answer performance.

Legacy analytics obscure AI performance
The useful KPI set is different:
KPI | What it measures | Why it matters |
|---|---|---|
Citation Rate | How often the brand appears in answer sets | Indicates retrieval and selection success |
Share of Answer | How much of the answer space the brand occupies | Reflects narrative control, not just presence |
Citation Position | Whether the brand appears early or late | Early placement usually carries more interpretive weight |
Verifiable Brand Mentions | Whether wording is attributable and consistent | Separates vague exposure from usable influence |
These metrics are difficult to capture in standard analytics platforms because many AI interactions don't generate clean referral data. Verification usually requires prompt libraries, repeated testing, and cross-platform observation using browser automation rather than depending only on APIs or web analytics.
The reporting stack has to observe the answer itself, not just the traffic that leaks out of it.
Governance requires verified sampling and refresh logic
The strongest external example of this operating model is the MERIT Framework whitepaper from Searchbloom. In validated case studies with brands including Webflow and Chime, the framework showed a 40% traffic uplift through automated content refresh workflows, and Chime tripled its AI citations in 4 weeks by tracking LLM-specific metrics and iterating against them.
That evidence matters for two reasons. First, it confirms that measurement and refresh aren't administrative tasks. They are performance levers. Second, it shows that governance must be continuous because retrieval environments decay when source material becomes stale or misaligned.
A practical governance cadence should include:
Prompt-set stewardship: Keep a stable set of commercial, category, and competitor prompts under review.
Cross-platform validation: Test the same topic across Google AI Overviews, ChatGPT, Gemini, Claude, and Perplexity.
Refresh triggers: Update high-value pages when answer quality drops, product language changes, or source competition intensifies.
Attribution review: Separate direct traffic outcomes from influence outcomes so visibility isn't undervalued.
The broader conclusion is uncomfortable but necessary. AI search can improve business performance while making some legacy traffic charts look worse. Governance exists to make that visible before the organization cuts investment in the very channel shaping market perception.
Return to Chapter 1. Book a complimentary AI visibility assessment with the team at Algomizer.
Conclusion: The New Model of Discovery
LLM search optimization fails when teams treat the click as the only valid signal of market influence.
That view breaks in AI-mediated discovery. Harvard Business Review captured the shift in its discussion of the “Attribution vs. Visibility Paradox,” explaining that AI-generated summaries “reduce click-through rates, delivering answers without requiring visits to branded websites” in HBR's analysis of LLMs overtaking search. The commercial implication is clear. Visibility can shape demand even when conventional traffic reporting understates it.
We have found that this changes what optimization is for.
A cited brand enters the buyer's decision process before the visit, before the form fill, and often before the shortlist is explicit. The model has already framed the category, selected the comparison set, and highlighted certain proof points over others. If a brand is absent at that moment, later-channel performance works against an upstream narrative it did not control.
That is why reverse-engineering citation behavior matters more than preserving legacy SEO vocabulary. The operative question is no longer whether a page ranks. The operative question is whether a model can extract enough structured, corroborated meaning from your corpus to cite you with confidence. Our work at Algomizer refers to that threshold as citation readiness. It is produced by evidence clusters that reinforce a claim across assets, and by semantic density that makes those claims legible to retrieval and synthesis systems.
The strategic hierarchy now looks different:
SEO optimized for visits.
LLM search optimization optimizes for citation eligibility.
AI visibility strategy optimizes for category influence.
The final category carries the highest economic value. Brands that win it do more than appear in answers. They shape how the market defines the problem, which evaluation criteria buyers adopt, and which vendors feel credible before any human conversation begins.
CMOs should treat this as a measurement and operating model shift, not a channel add-on. The durable advantage is not traffic in isolation. It is becoming a source that language models repeatedly retrieve, trust, and cite when they explain what matters.
Return to Chapter 1. Book a complimentary AI visibility assessment with the team at Algomizer.
Algomizer helps brands understand how AI systems surface, cite, and recommend their content across platforms such as ChatGPT, Claude, Gemini, and Perplexity. Teams that need verified visibility analysis, content engineering, technical implementation, and ongoing calibration can book a call with Algomizer.