Unlock AI with Custom Search Engine for Website
Custom search engine for website - Build a custom search engine for your website to win in AI. Our guide covers modern architectures, implementation, ROI, and

Generative Discovery Infrastructure for the LLM Era
May 2026
Most advice about a custom search engine for website still treats the search box as a convenience feature. That advice is obsolete. In an LLM-driven market, site search has become infrastructure for retrieval, answer quality, and brand narrative control.
A modern brand doesn’t just publish pages. It publishes machine-readable evidence. When that evidence is indexed cleanly, updated quickly, and organized semantically, both humans and AI systems can retrieve it with less distortion. When it isn’t, competitors inherit the framing.
This paper argues that the internal search layer now sits at the intersection of on-site UX and off-site AI visibility. Teams building for this environment should think less about “adding search” and more about engineering a bounded knowledge system. For organizations auditing the raw content supply chain behind AI retrieval, tools like #1 Web Scraping API for LLMs are relevant because they expose the mechanics of structured extraction and retrieval readiness in a way generic SEO tooling doesn’t.
Table of Contents
Executive Summary Your Site Search Is an AI Training Ground
Site search has become retrieval infrastructure
The strategic shift is narrative control
Why Traditional Site Search Fails in the AI Era
Legacy search breaks on the modern web
Keyword logic can’t carry conversational intent
Comparing Modern Custom Search Architectures
Three architectures now matter
Search Architecture Trade-Offs
The real selection criterion is governance
The AEO Framework Engineering Search for AI Trust
Evidence Clusters create citation readiness
AEO turns internal retrieval into external authority
Implementation Pathways and Strategic Trade-Offs
Build and buy create different control surfaces
Headless sites require crawler-aware implementation
Measuring Search ROI and Ensuring Compliance
Query volume is the wrong executive metric
Compliance must shape the index itself
Conclusion The Search Box Is Your New Brand API
The brand that controls retrieval controls representation
Executive Summary Your Site Search Is an AI Training Ground
A custom search engine for website is no longer a support feature. It is a bounded retrieval system that shapes what users find, what AI systems ingest, and how a brand gets represented.
Site search has become retrieval infrastructure
Custom search engines use crawling and indexing architectures that differ from broad web search. On bounded datasets, they can deliver sub-second query times and support real-time indexing for dynamic content, which changes the economics of content freshness and retrieval speed for brands competing in AI-mediated discovery, according to Quotium’s guide to custom search engine technologies.
That architectural distinction matters more than most marketing teams realize. Broad web search optimizes across the public web. A custom engine optimizes across a curated corpus where every page, file, and answerable object can be intentionally prepared for retrieval. That makes the internal index a controllable knowledge substrate.
Practical rule: If a page can’t be reliably crawled, normalized, and retrieved inside the site’s own search system, it won’t be consistently represented in AI answer environments either.
The strategic shift is narrative control
The popular framing says site search exists to help visitors find pages faster. That framing is incomplete. The more consequential role is that site search defines which facts are easiest to retrieve, which claims stay fresh, and which entities remain connected inside a machine-usable corpus.
This changes the operating model for content and growth teams:
Freshness becomes competitive: Bounded indices can update quickly, so newly published material can become retrievable far sooner than conventional organic discovery.
Structure outranks volume: Brands benefit more from coherent evidence and clean indexing than from publishing undifferentiated page volume.
Search becomes cross-functional: CMS teams, content strategists, legal reviewers, and AI visibility teams now influence the same retrieval layer.
A brand that neglects this layer doesn’t merely ship a weaker on-site experience. It loses control over how its own facts are surfaced.
For Chapter 1, the governing conclusion is simple. Internal search is now external AI infrastructure in disguise. Readers who want to revisit this foundation can return to Chapter 1 of this series, or book a call with Algomizer.
Why Traditional Site Search Fails in the AI Era
Traditional site search fails because it was built for static pages, simple keyword matching, and a web that no longer exists. AI-era discovery demands semantic retrieval, resilient crawling, and coverage across dynamic architectures.
Legacy search breaks on the modern web
The biggest operational failure isn’t ranking. It’s incomplete indexing. According to SiteSearch360’s overview of custom search engines for websites, 80% of enterprise sites now use headless architectures, and traditional crawlers often fail in those environments. The same source notes that forum discussions in 2025 showed a spike in unanswered questions about making custom search work with Next.js SSR.
That means many enterprises are deploying polished front ends that their own search systems can’t reliably read.
A few common failure patterns explain why:
JavaScript-heavy rendering: Crawlers that expect static HTML miss content assembled at runtime.
Headless CMS delivery: APIs may expose content, but weak search implementations never ingest the rendered output correctly.
Fragmented documentation estates: Product pages, help centers, developer docs, and policy pages often live in separate systems with no shared retrieval layer.
Keyword logic can’t carry conversational intent
Even when legacy search indexes enough content, it often can’t interpret the way people now ask questions. Users don’t search like database operators anymore. They ask in full problems, trade-offs, and scenarios.
A query such as “which laptop is best for remote work security” illustrates the gap. A legacy engine tuned to exact terms might overvalue pages containing “laptop” and “security” separately, while missing content that answers the underlying use case through related language like device management, endpoint protection, or employee travel policy.
Legacy search returns pages. AI-ready search returns the best evidence path to an answer.
The same SiteSearch360 source states that reliance on tools like Google CSE can reduce user experience by 40% on AI-heavy sites because those systems lack semantic ranking. That point deserves a strategic translation. When the search layer can’t interpret intent, the brand cedes the first answer to whichever competitor has built a system that can.
The old assumption was that weak site search was a tolerable UX flaw. It isn’t. It’s a retrieval failure that distorts brand visibility at the exact moment when users and machines both expect direct answers.
Readers can return to Chapter 1, or book a call with Algomizer.
Comparing Modern Custom Search Architectures
The architecture decision determines what a site can retrieve, how quickly it can update, and whether it can support AI-native answer experiences. Most enterprise choices now collapse into three models.
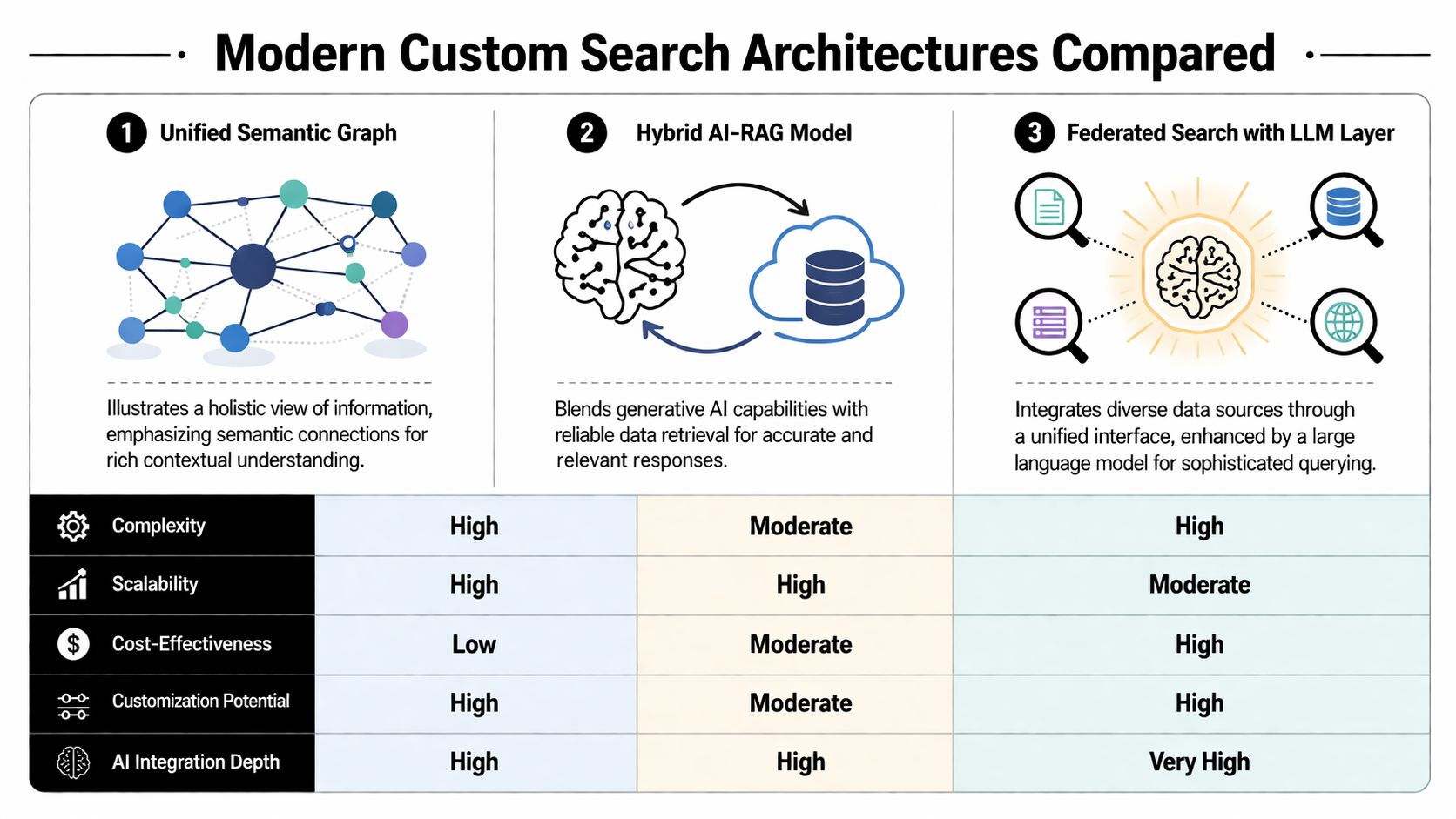
Three architectures now matter
The first model is Modern Site Search. This is the successor to basic keyword systems. It usually adds stronger crawling, improved indexing, and some level of natural-language relevance. For many marketing sites, this is the minimum viable modernization.
The second model is Federated Search. This architecture unifies multiple repositories into a shared search experience. A user can search the public site, knowledge base, documentation portal, and support content from one interface. Federated systems matter when the truth about a product no longer lives in one CMS.
The third model is AI or LLM-Driven Search. This moves beyond ranked links toward synthesized answers. The engine retrieves from internal sources, resolves semantic similarity, and can assemble direct responses from controlled evidence. In practice, vector retrieval, answer generation, and source grounding begin to merge.
Custom search systems matter here because, on bounded datasets, they can support rapid indexing and low-latency retrieval. That speed changes how quickly brands can make new information discoverable inside answer systems. For a deeper conceptual bridge between retrieval systems and generative visibility, this explanation of how GEO works is useful.
Search Architecture Trade-Offs
Attribute | Modern Site Search | Federated Search | AI/LLM-Driven Search |
|---|---|---|---|
Primary retrieval model | Improved lexical and basic semantic matching | Unified retrieval across multiple repositories | Semantic retrieval plus answer synthesis |
Best fit | Marketing sites and standard content libraries | Organizations with fragmented content estates | Brands that want direct-answer experiences |
Content scope | Usually one primary property | Multiple systems such as docs, support, and web content | Any source that can be normalized and governed |
Operational burden | Moderate | Higher, because connectors and schema alignment matter | Highest, because retrieval quality and grounding both matter |
User output | Ranked results | Ranked results across silos | Answers, citations, and ranked evidence |
Strategic upside | Better findability on the website | Shared truth across channels and teams | Strongest alignment with LLM-style discovery |
The real selection criterion is governance
The wrong way to choose is by feature checklist. The right way is by deciding how much of the brand’s knowledge environment needs to be unified and how directly the business wants to support answer-based interactions.
A practical decision path looks like this:
Choose Modern Site Search when a single web property contains most of the value and the primary problem is poor retrieval.
Choose Federated Search when users routinely cross between product, support, and documentation silos.
Choose AI or LLM-Driven Search when the business needs direct answers, retrieval transparency, and a machine-readable evidence layer that can serve both users and AI systems.
Architectural insight: Search quality rarely collapses because ranking is weak. It collapses because the chosen architecture can’t see enough of the truth to rank it in the first place.
The AEO Framework Engineering Search for AI Trust
Answer Engine Optimization treats retrieval as a trust problem, not a traffic trick. An AI-ready search engine earns citation preference when it exposes clean, verifiable, semantically connected evidence.
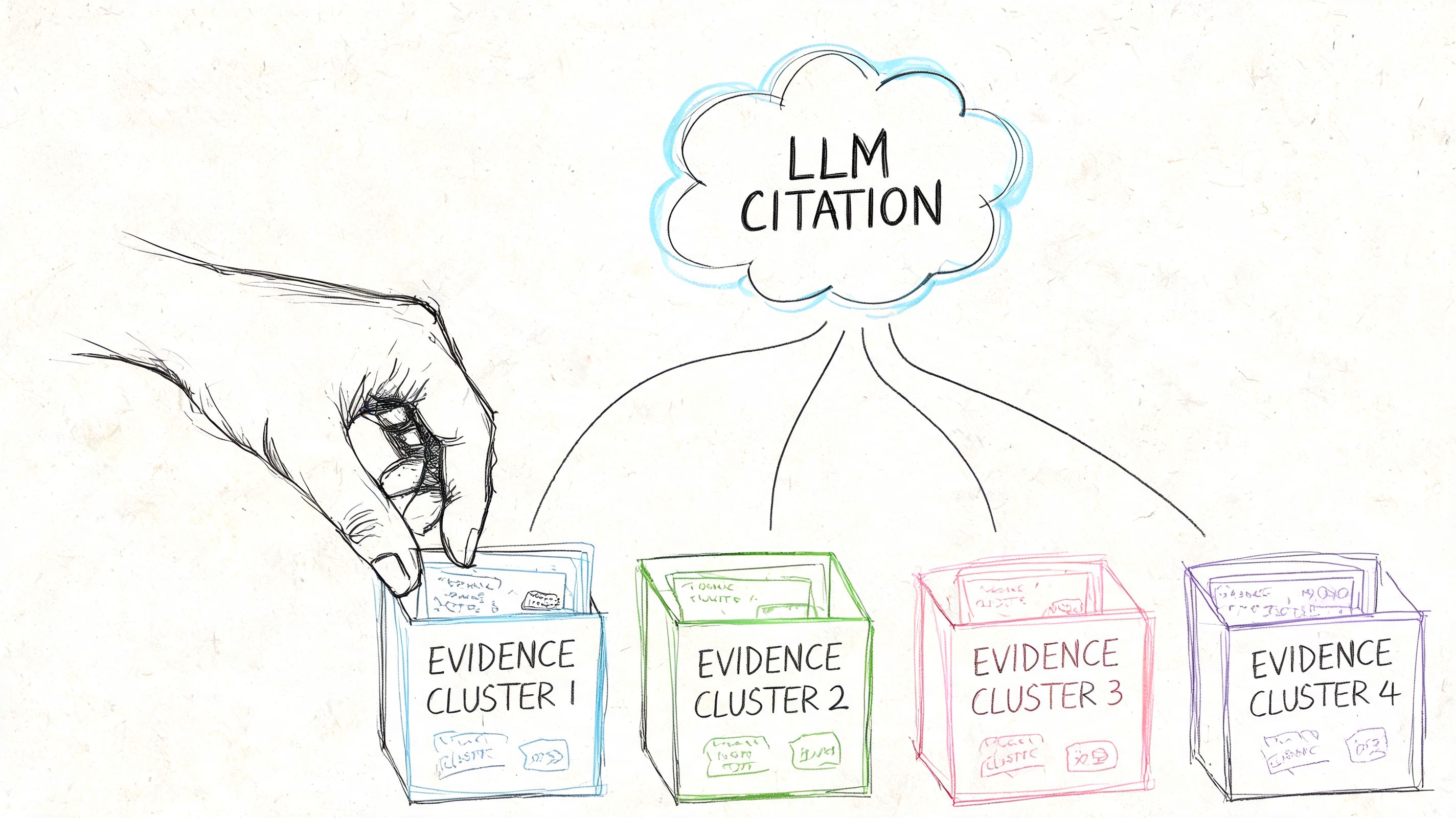
Evidence Clusters create citation readiness
The core unit in this framework is the Evidence Cluster. That term describes a deliberately constructed group of related claims, definitions, examples, and supporting context that can be retrieved together. Instead of scattering knowledge across thin pages, brands increase trust when they assemble coherent answer blocks.
A useful adjacent primer on optimizing content for LLM answers reinforces the same operating principle. AI systems prefer content that is easy to parse, verify, and connect.
An Evidence Cluster typically includes:
A canonical claim: One clear statement of what the page or section is asserting.
Supporting context: Explanations, product detail, policy language, or technical qualifiers that prevent ambiguity.
Entity connections: Links to related products, categories, use cases, documentation, or governance pages.
Retrievable formatting: Headers, structured sections, and stable language that a search system can index cleanly.
Design test: If a retrieval system isolates one paragraph from the rest of the page, that paragraph should still preserve enough meaning to remain trustworthy.
AEO turns internal retrieval into external authority
A custom search engine for website then becomes more than a user feature. The engine maintains the internal map of what belongs with what. It decides whether a product claim appears alone, whether policy language remains discoverable next to feature language, and whether definitions stay attached to the terms they qualify.
That internal structure has an external consequence. LLM systems built on retrieval pipelines are biased toward sources that are easier to segment, rank, and ground. A site with clean Evidence Clusters gives those systems stronger retrieval targets than a site full of fragmented, duplicative, or loosely connected pages.
The implementation discipline is straightforward in principle:
Normalize content into retrievable units.
Group related facts under stable semantic headings.
Reduce duplicate claims that compete with one another.
Keep critical pages fresh and connected inside the index.
Validate that the search layer retrieves the intended evidence first.
This comparative view of AEO vs SEO vs GEO helps clarify why answer systems reward structure differently than classic search systems.
A short walkthrough of retrieval behavior helps operational teams align on what “trust” means in practice:
The implication is strategic. Brands don’t wait for AI systems to understand them correctly by accident. They engineer retrieval conditions that make the correct interpretation the easiest one to select.
Implementation Pathways and Strategic Trade-Offs
Implementation is a governance decision disguised as a tooling decision. The central question isn’t just whether to build or buy. It’s who controls the index, the crawler behavior, and the retrieval logic that defines brand truth.
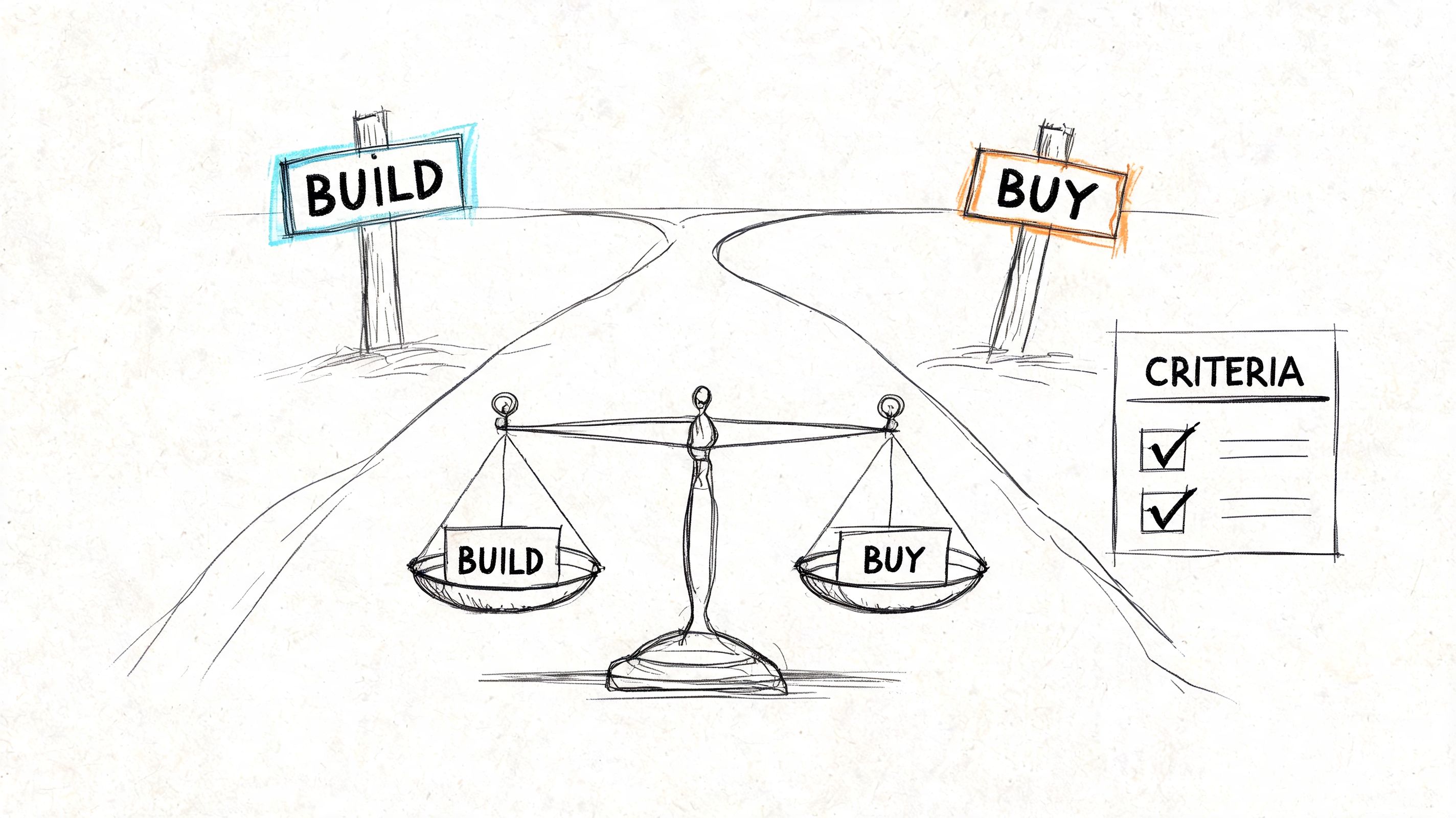
Build and buy create different control surfaces
A company that builds gains maximum flexibility. It can tailor crawling to the CMS stack, design its own indexing rules, and tune retrieval around business-critical entities such as products, legal terms, and support content. The cost is complexity. Internal teams must own crawler reliability, schema normalization, observability, ranking calibration, and ongoing maintenance.
A company that buys gets speed and abstraction. Vendors can accelerate deployment, reduce operational burden, and provide prebuilt connectors. The trade-off is that some of the most important decisions may be hidden behind product defaults, especially around crawling depth, semantic ranking behavior, and data handling.
A practical evaluation framework should include:
Crawler adaptability: Can the system handle rendered JavaScript, dynamic routes, and protected content states?
Index governance: Can teams control what enters the index, what gets excluded, and how canonical sources are prioritized?
Retrieval transparency: Can teams inspect why one result or answer was returned over another?
Integration burden: How much engineering work is required across CMS, docs, support systems, and analytics?
For organizations that lack the in-house engineering capacity to bridge strategy and implementation, selective staff augmentation for AI projects can be useful when the blocker is execution depth rather than strategic clarity.
Headless sites require crawler-aware implementation
The hidden implementation risk sits inside modern web delivery. 80% of enterprise sites now use headless architectures, traditional crawlers often fail in those environments, and user experience can drop by 40% on AI-heavy sites when teams rely on tools like Google CSE that don’t provide semantic ranking.
That changes vendor selection criteria immediately. A crawler that worked on a conventional CMS may fail on a Next.js or Nuxt.js deployment if the engine can’t correctly handle rendered states, route generation, or dynamically injected content.
A disciplined rollout usually follows this sequence:
Audit render paths. Teams identify what content exists in source systems, what appears only after rendering, and what the crawler sees.
Define inclusion rules. Product truth pages, support pages, and policy pages need explicit indexing treatment.
Test retrieval against real user questions. Query logs and support transcripts reveal whether the engine can answer scenario-based searches.
Establish freshness workflows. Publishing, recrawling, and validation need to operate as one chain.
Buying a search platform doesn’t solve retrieval if the platform can’t reliably see the site that was built.
The final implementation choice should follow the site’s architecture, not a generic buyer’s guide. A weakly integrated engine creates a polished interface over an incomplete corpus, which is the worst possible combination because the failure stays hidden.
Readers can return to Chapter 1, or book a call with Algomizer.
Measuring Search ROI and Ensuring Compliance
Search ROI in the AI era should be measured by answer quality and business outcomes, not by raw query volume. Executives need to know whether the engine resolved intent, influenced conversion, and protected governed content.
Query volume is the wrong executive metric
A high number of searches doesn’t prove that a custom search engine for website is working. It may prove that navigation failed. Better measurement starts with whether the engine delivered a useful answer path.
Three operational KPIs matter most:
KPI | What it measures | Why it matters |
|---|---|---|
Answer Fill Rate | Share of searches that return a direct, useful answer or clearly relevant result set | Shows whether the engine can satisfy intent |
Search-to-Conversion Lift | Whether search users move toward demo requests, purchases, or qualified actions more often than non-search users | Connects retrieval quality to revenue behavior |
Support Ticket Deflection | Whether searchable answers reduce repetitive support demand | Converts retrieval improvements into operational savings |
These metrics force the organization to evaluate retrieval as a business system. They also align closely with AI-era expectations, where users increasingly expect direct answers rather than ten blue links.
A strong governance practice is to compare search outputs against recurring customer questions. Teams that want a tighter method for assessing machine-visible source quality can use frameworks similar to this guide on reliable citation analysis for AI search engines.
Compliance must shape the index itself
Security and compliance aren’t post-processing layers. They have to shape what gets crawled, segmented, and exposed to retrieval in the first place.
A defensible program usually includes:
PII exclusion rules: Sensitive data should never enter the searchable index.
Access-aware retrieval: Internal or role-restricted material must respect authorization boundaries.
Source prioritization: Teams should define which repositories count as canonical when duplicate or conflicting content exists.
Vendor review: If third-party APIs participate in retrieval, legal and security teams need clarity on processing boundaries and retention assumptions.
A search engine becomes a compliance problem the moment it indexes material the business didn’t intend to expose.
The executive case becomes easier when these two conversations stay connected. ROI improves when search resolves intent. Risk stays contained when the indexed corpus is governed deliberately. Both outcomes depend on the same thing: disciplined control over retrieval.
Conclusion The Search Box Is Your New Brand API
The search box now functions as a machine-facing interface to brand truth. It determines what can be retrieved quickly, what remains connected contextually, and what gets surfaced when users or AI systems ask complex questions.
The brand that controls retrieval controls representation
The conventional view says a search engine helps visitors find pages. The stronger view is that it governs how a company’s knowledge becomes legible. Internally, that means better answer experiences. Externally, it means a cleaner substrate for AI systems that rely on retrieval to ground outputs.
That is why a custom search engine for website belongs in the same strategic category as analytics, content governance, and core CMS architecture. It shapes not just findability, but interpretation.
The durable advantage won’t come from publishing more content than competitors. It will come from publishing a more retrievable, more coherent, and more governable corpus than competitors. In the generative era, that difference decides which brand gets cited, trusted, and recommended.
Readers can return to Chapter 1, or book a call with Algomizer.
Algomizer helps brands win visibility inside AI-generated answers across ChatGPT, Claude, Gemini, Perplexity, and other large language models. Teams that want a clearer picture of how their brand is being retrieved, cited, and represented can book a call with Algomizer.