
Mastering Your First Party Data Strategy for AI Search
Unleash AI search dominance with a robust first party data strategy. Our 2026 guide covers architecture, activation, & measurement for B2B brands.

First-party data stops being a media input and becomes machine-readable proof of authority
Date: June, 2026
First-party data strategy is usually framed as a defensive response to cookie loss. That framing is too small. It treats owned data as a targeting substitute when its larger function is epistemic: it helps machines decide what a brand knows, whom it serves, and whether its claims align with observable behavior.
Large language models don't reason like media buyers. They compress patterns, retrieve corroborating evidence, and prefer consistent signals over isolated assertions. A brand that collects direct, consent-based signals from product usage, site search, registrations, support interactions, and transactions isn't just improving segmentation. That brand is constructing the most credible dataset available about its own expertise.
That shift matters because AI search changes the unit of competition. The old contest centered on impressions, clicks, and audience rental. The new contest centers on whether a system like ChatGPT, Claude, Gemini, or Perplexity finds enough structured, repeated, and behaviorally grounded evidence to mention a brand in an answer.
Table of Contents
Executive Summary The End of Data as a Targeting Tool
The Board-Level Question Has Changed
Owned Data Is the New Ground Truth
Renting Audiences Is Over
From Ad Impressions to AI Citations A New Paradigm
The Unit of Value Has Flipped
What the New System Rewards
The Signal Fidelity Framework For AI Trust
Data Unification Is Non-Negotiable
Behavioral Congruence Builds Trust
Intent Verification Proves Relevance
Architecting for High Signal Fidelity
The CDP Becomes Core Infrastructure
Identity Resolution Determines Signal Quality
Governance Protects the System
Activating Data for Generative Engine Optimization
Content Engineering Starts with Native Demand
Personalization Becomes Public Evidence
Evidence Clusters Extend Authority
Measuring Success Beyond the Click
Legacy KPIs Miss the Strategic Outcome
The Better Scorecard for AI Search
Conclusion Your Roadmap to AI Authority
Phase 1 Audit and Unify
Phase 2 Implement and Standardize
Phase 3 Activate and Measure
Phase 4 Optimize and Scale
Executive Summary The End of Data as a Targeting Tool
First-party data strategy now determines how machines evaluate brand authority, not just how marketers target audiences, and that changes budget logic, platform architecture, and measurement.
The common advice says first-party data replaces third-party cookies. That advice misses the more important transition. First-party data has become the raw material for AI-visible authority because it records direct relationships, explicit consent, and repeated patterns of real customer intent.
StackAdapt cites EMARKETER data showing that 38% of marketers worldwide planned to invest in personalization, while 27% were focusing on using first-party data for paid media in 2026 projections, which signals that first-party data had already become a growth lever rather than technical hygiene (StackAdapt on first-party data strategy). The underexamined implication is that many organizations still anchor the asset to paid media, even though AI systems reward the broader ecosystem that the data makes possible.

The Board-Level Question Has Changed
A mature first party data strategy is no longer about asking, "How can paid media target better?" The stronger question is, "What evidence does the company own that an AI system can repeatedly validate?"
Architecture is paramount. LLM-based search systems consume content, metadata, entity relationships, and corroborating external references. They don't merely read claims. They infer authority from consistency across surfaces. If a company says it serves enterprise buyers, but its registrations, support taxonomy, gated assets, and product education don't reinforce that claim, the model receives a weak authority signal.
Research position: Brands don't become authoritative in AI search by publishing more opinion. They become authoritative by aligning content claims with owned behavioral evidence.
Owned Data Is the New Ground Truth
The strongest first-party datasets come from direct customer relationships: websites, apps, loyalty programs, email and SMS sign-ups, surveys, gated content, and support interactions. Those inputs describe not only who the audience is, but what the audience repeatedly asks, compares, buys, and struggles to understand.
That is why the best operating model now starts with measurable objectives, trust, unification, and activation. These aren't just marketing best practices. They are prerequisites for building machine-legible evidence. Teams that still separate data collection from content strategy produce fragmented outputs. Teams that connect them create what AI systems recognize as a coherent knowledge environment.
For leaders evaluating systems design, the distinction between a CDP and CRM matters because each governs how identity and interaction history become usable downstream. A practical resource on that distinction is Halo AI's guide to Explore CDP vs CRM use cases.
Renting Audiences Is Over
The market used to reward reach. AI search rewards proof. In that environment, first-party data strategy becomes the operating system for Generative Engine Optimization. It shapes what a brand knows about demand, how clearly it expresses that demand in content, and how defensible its expertise appears when a retrieval layer assembles an answer.
The companies that win won't treat first-party data as a remarketing list. They'll treat it as the cleanest available source of truth about customer intent, product relevance, and category authority.
From Ad Impressions to AI Citations A New Paradigm
The legacy model optimized distribution efficiency, while the modern model optimizes retrievability, verifiability, and citation-worthiness inside AI-generated answers.
The old digital stack assumed scarcity of attention and abundance of trackable impressions. The emerging AI stack assumes abundance of content and scarcity of trusted evidence. That is why the same first party data strategy that once supported segmentation now governs whether a brand is even eligible to appear in generated answers.
The Unit of Value Has Flipped
Cookie-based advertising worked by approximating identity, inferring interest, and buying access. AI search works differently. It retrieves from available knowledge, weighs source coherence, and assembles language from patterns that survive validation.
That difference changes the core business question. A media team asks whether the campaign reached the intended audience. An AI search team asks whether the answer engine found enough credible, repeated evidence to mention the brand at all.
Vector | Legacy Model (Cookie-Based) | Modern Model (Citation-Based) |
|---|---|---|
Primary Goal | Ad targeting | AI authority |
Core Asset | Anonymous cookies | Known user profiles |
Key Technology | DMP | CDP |
Success Metric | ROAS | Share of Answer |
Content Role | Creative for response | Evidence for retrieval |
Identity Logic | Probabilistic audience approximation | Consent-based customer context |
Optimization Loop | Bid, impression, click | Retrieve, compare, cite |
Strategic Risk | Wasted spend | Invisibility in AI answers |
The language around LLM visibility is still messy, which is why many teams benefit from a cleaner definition of LLMO and how it differs from SEO. The distinction matters because an LLM doesn't "rank" a page the way a search engine result page does. It synthesizes across sources and rewards semantic consistency.
What the New System Rewards
A citation-based environment rewards four characteristics:
Consistency: The same expertise appears in product pages, help content, thought leadership, and customer-facing workflows.
Traceability: Claims connect back to real interactions such as registrations, demos, usage patterns, and support histories.
Entity clarity: The brand, products, use cases, and category terms map cleanly across systems.
Repetition across contexts: The same competence shows up on owned properties and corroborating external surfaces.
AI search doesn't need more promotional content. It needs fewer contradictions.
A first party data strategy becomes decisive here because it gives organizations a way to align declared expertise with observed demand. If buyers repeatedly search the site for implementation questions, ask support about integrations, and download migration guides, that pattern should shape public content, schema, navigation, and media placement. When it does, AI systems see a brand whose claims match its customer reality.
The old model tolerated fragmentation because the auction could still deliver impressions. The new model punishes fragmentation because conflicting signals reduce confidence. Brands that cling to cookie-era assumptions won't merely underperform. They will become harder for machines to trust.
The Signal Fidelity Framework For AI Trust
Signal Fidelity measures whether a brand's data produces clear, consistent, and verifiable inputs that retrieval-augmented systems can use to justify citation.
Most first party data strategies break at activation because the organization treats data collection as a storage problem. It isn't. It is a model-input problem. LLM and RAG systems perform best when the underlying evidence is unified, behaviorally consistent, and mapped to real user intent.
Algomizer's proprietary model for this problem is the Signal Fidelity Framework. It treats first-party data strategy as a trust-construction system for AI search, not a campaign support function.
Data Unification Is Non-Negotiable
Fragmented data produces fragmented authority. A website says one thing, the CRM says another, and the support platform contains the clearest expression of customer need but never informs publishing. The model receives noise.
A comprehensive strategy unifies behavioral, transactional, and declared-interest data into a persistent view that downstream systems can employ. In LLM terms, this creates a cleaner semantic substrate. Retrieval works better when the source environment has fewer conflicting entities, duplicated records, and disconnected taxonomies.
A useful companion for teams building machine-facing workflows is Robotomail's guide on AI agent developer email validation patterns. It is relevant because agent systems fail when identity quality degrades at input, and first-party pipelines suffer from the same problem.
Practical rule: If product, content, sales, and support classify the same customer differently, AI systems inherit that inconsistency.
The deeper engineering treatment of this principle appears in Algomizer's paper on engineering truth for GEO systems.
Behavioral Congruence Builds Trust
Authority claims need behavioral confirmation. If a company publishes advanced material on compliance automation, but users who register or search the site primarily engage with beginner content, the authority signal weakens. The issue isn't traffic. It is congruence.
Behavioral congruence means the actions users take on owned properties align with the expertise the brand wants models to infer. This includes patterns such as:
On-site search language: The terms visitors use should map to the categories the brand publicly owns.
Support vocabulary: Repeated ticket themes should reinforce solution depth, not expose mismatched positioning.
Conversion paths: High-intent journeys should connect naturally to the claimed use cases.
AI-first interpretation changes the playbook. Traditional marketers often treat user behavior as optimization fuel. AI systems treat repeated behavior as evidence. The same query appearing in site search, help content, webinar sign-ups, and product docs acts like multi-surface confirmation.
A video walkthrough helps clarify the trust stack in practice.
Intent Verification Proves Relevance
Not all first-party data deserves equal weight. Page views alone are weak. Verified intent is stronger. Site search, support conversations, registrations, subscriptions, and purchases reveal what users are trying to solve with much less ambiguity.
Intent verification connects those signals to answer design. If users repeatedly ask implementation questions before purchase, the company should build content that resolves implementation uncertainty. If support logs cluster around migration, integration, or compliance workflows, those themes should become public evidence assets.
Three activation priorities follow:
Extract recurring problem statements from site search, chats, and support workflows.
Map those statements to product pages, FAQs, glossary entries, and comparison pages.
Publish in language that preserves the user phrasing rather than replacing it with internal jargon.
Signal Fidelity is achieved when the brand's content environment mirrors actual customer demand. That is what makes the brand the most defensible source for an LLM to cite.
Architecting for High Signal Fidelity
A serious first party data strategy requires centralized, consent-based profiles because weak identity architecture creates contradictory signals that AI systems discount.
The infrastructure question is no longer optional. When data lives in isolated tools, every downstream output becomes less reliable. Content teams publish from incomplete briefs. Paid teams optimize from partial histories. Analytics teams report on different customer definitions. AI systems then encounter the public result of that internal fragmentation.
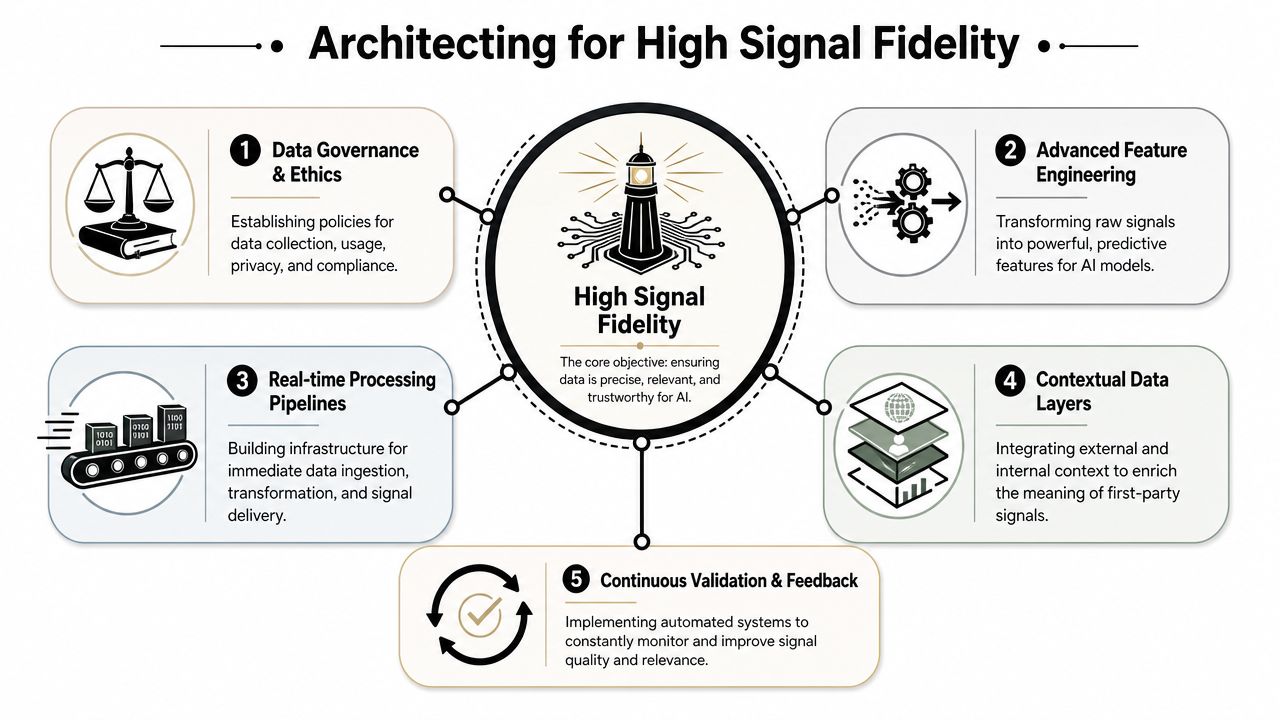
The CDP Becomes Core Infrastructure
A foundational milestone in first-party data strategy is the move toward centralized, consent-based customer profiles, often consolidated in a Customer Data Platform (CDP) or CRM for standardization and activation, transforming fragmented signals into a single customer view (Fullstory on first-party data strategy).
That architecture matters far beyond campaign orchestration. In AI search terms, the CDP functions as the system that makes customer reality legible. It collects interactions from websites, apps, CRM records, support systems, and transactional tools, then standardizes them into a persistent profile. Without that layer, every activation channel improvises its own version of the customer.
Identity Resolution Determines Signal Quality
Identity resolution is the mechanical core of Signal Fidelity. If one user appears as multiple profiles across registration forms, product usage logs, and support records, the company cannot reliably infer journey stage or topic depth.
That problem directly affects AI visibility because the public web presence usually mirrors the same disorder. Pages proliferate around overlapping terms. Taxonomy drifts. Messaging splits by department. A retrieval layer then encounters duplicate claims without a stable underlying entity model.
A high-fidelity architecture usually includes these functions:
Component | Operational Role | AI Search Consequence |
|---|---|---|
Identity stitching | Merges cross-channel records | Reduces contradictory entity signals |
Standardization | Normalizes fields and formats | Improves consistent topic expression |
Consent controls | Governs lawful data use | Protects trust and activation integrity |
Taxonomy mapping | Aligns teams on terms and categories | Makes brand expertise easier to retrieve |
Persistent profiles | Maintains history over time | Supports durable authority patterns |
Governance Protects the System
Architecture fails when governance is bolted on later. Consent, field definitions, event naming, and retention rules must be designed up front. This isn't only a legal concern. It is a signal quality concern.
A company that collects direct signals through a clear value exchange will produce cleaner data than one that captures everything and explains nothing. The first system attracts willing inputs. The second attracts noise, duplicates, and mistrust.
The best first-party architectures don't collect the most data. They collect the most defensible data.
The practical outcome is straightforward. A modern CDP-centered environment acts as the essential foundation for any company aiming for its AI systems to access a coherent, consent-based, machine-readable version of its expertise.
Activating Data for Generative Engine Optimization
Unified data becomes valuable only when it shapes what the brand publishes, personalizes, and reinforces across the open web for AI retrieval systems.
Many organizations stop at unification. They centralize records, clean fields, and declare success. That is infrastructure completion, not market activation. Generative Engine Optimization begins when standardized first-party signals start changing content, journeys, and external evidence patterns.
Content Engineering Starts with Native Demand
Because first-party data is collected across websites, apps, and registrations, a robust strategy requires a normalization layer and a single customer profile, often in a CDP, to consolidate, standardize, and enrich records before activation for use cases like retargeting and personalization (LiveRamp on first-party data strategy).
In AI search, that same normalization layer should drive editorial choices. Site search logs, support conversations, demo requests, and onboarding questions reveal the exact language users employ when they need help. That language is superior to brainstormed topic lists because it originates in real task completion.
The most effective pattern looks like this:
Collect native demand signals: Pull repeated questions from site search, support queues, webinars, and sales notes.
Convert them into answer assets: Build FAQs, comparison pages, implementation guides, and glossary definitions using the same phrasing customers use.
Preserve semantic clarity: Keep category terms stable across navigation, product copy, and documentation.
Teams building autonomous data collection or monitoring workflows often study building intelligent web agents because agentic systems reveal the same truth. Retrieval quality depends on structured environments, not just more pages.
A related implementation pattern appears in Algomizer's work on the custom search engine for website experiences, where internal search behavior becomes a direct input to content and discovery design.
Personalization Becomes Public Evidence
Traditional personalization focuses on conversion uplift. In GEO, personalization also acts as proof of domain fluency. When a brand serves content that reflects segment-specific needs, it demonstrates category understanding at a granular level.
This doesn't mean exposing private customer data. It means using first-party segments to shape what public assets exist and how they connect. A software company that knows enterprise buyers repeatedly ask about security reviews should not bury that knowledge in sales collateral. It should publish a durable answer surface that external retrieval systems can access.
Personalization is strongest when private insight produces public clarity.
Evidence Clusters Extend Authority
Evidence Clusters are the activation layer that most brands miss. The principle is simple. Use the attributes, pain points, and vocabulary of best-fit customers to inform where the brand publishes, what claims it repeats, and which authoritative contexts should corroborate those claims.
This creates a web of confirmation. Owned pages define the solution space. Product docs specify mechanics. Customer education explains workflows. External placements reinforce the same entities and use cases. AI systems prefer that pattern because it is easier to verify than isolated brand messaging.
A first party data strategy succeeds in GEO when it turns internal demand into external proof.
Measuring Success Beyond the Click
Clicks measure traffic response, but AI authority requires metrics that reveal whether answer engines mention, trust, and frame the brand correctly.
Performance teams inherited a dashboard built for ad auctions. CPC, CTR, and even conversion rate still matter for channel efficiency, but they don't answer the strategic question posed by AI search. A brand can run efficient campaigns and still disappear from generated answers for its core category.
Legacy KPIs Miss the Strategic Outcome
The weakness of traditional metrics is conceptual, not mathematical. They measure user reaction after exposure. They don't measure whether the brand was selected as a credible source before exposure occurred.
That distinction is decisive. In a generative environment, the model often intermediates discovery. If the answer excludes the brand, downstream click metrics never enter the picture. The company loses before the session reaches analytics.
This is why boards and executive teams need a parallel scorecard. It should track whether the brand is present in category answers, whether its content gets cited, and whether the model frames the company as authoritative or peripheral.
The Better Scorecard for AI Search
A practical AI-era measurement stack includes four metrics.
Metric | What It Tracks | Why It Matters |
|---|---|---|
Share of Answer | How often the brand appears in AI answers for target prompts | Measures category visibility at the answer layer |
Citation Rate | How often brand assets are cited or referenced | Shows whether content is trusted enough to support responses |
Branded vs unbranded query movement | Whether users shift from generic category queries toward the brand | Indicates growing authority and recall |
Answer sentiment analysis | How the brand is described when mentioned | Distinguishes favorable authority from neutral inclusion |
These metrics can be observed through controlled prompt sets, headless browser monitoring, response capture, and repeated evaluation across platforms such as ChatGPT, Claude, Gemini, and Perplexity. The operational discipline matters more than any single tool. Teams need fixed prompt libraries, clear entity definitions, and periodic review of answer variance.
Three implementation rules keep the scorecard useful:
Measure at the topic cluster level: Brand-wide averages hide important category gaps.
Review citation context, not just presence: A mention inside a weak or negative framing isn't success.
Compare owned and external evidence: If the brand isn't cited, the issue may be proof scarcity rather than ranking mechanics.
A click says someone responded. A citation says the machine trusted the brand enough to speak its name.
The shift in measurement changes budget conversations. Instead of defending content as top-of-funnel support, leaders can evaluate it as authority infrastructure. That is a more strategic lens because AI search rewards the sources that systems can justify, not merely the pages that attract traffic.
Conclusion Your Roadmap to AI Authority
A first party data strategy is now the operating model for AI visibility because authority in generative systems emerges from unified, consent-based, behaviorally validated evidence.
The most useful conclusion is to build a system that converts direct customer signals into machine-trustworthy proof.
That is the practical meaning of AI authority. A brand becomes citable when its data, content, taxonomy, and external reinforcement all point to the same conclusion.
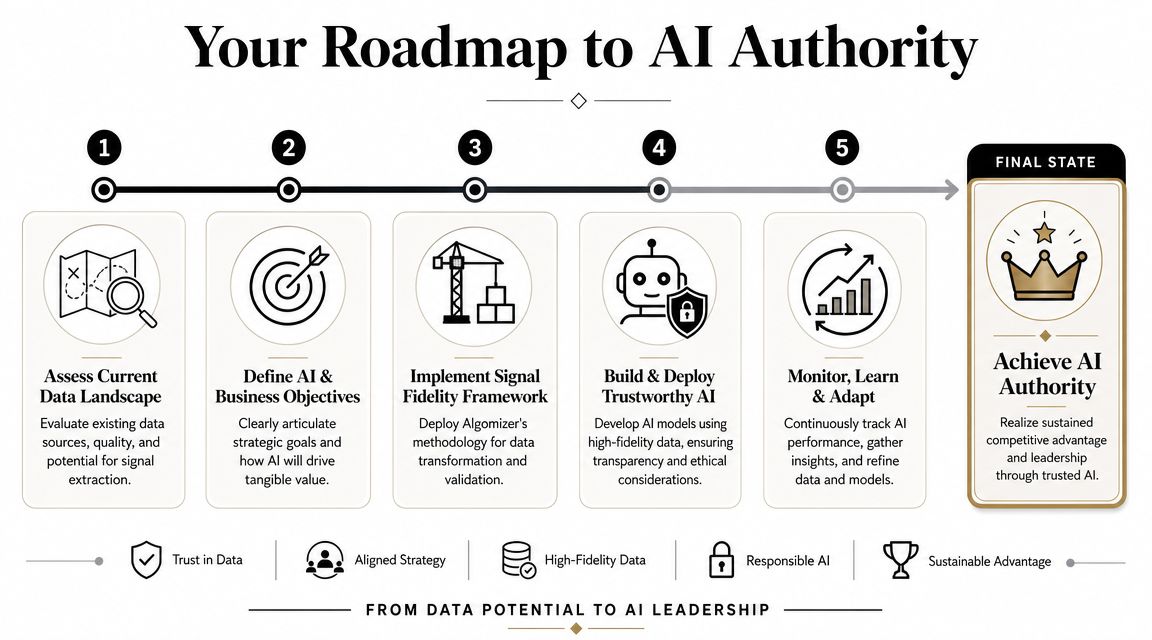
Phase 1 Audit and Unify
Inventory every owned source of demand and identity. That includes websites, apps, CRM records, support systems, registrations, subscriptions, surveys, and transaction environments.
The main output is a map showing where the company's most credible intent signals are located.
Assess overlap, duplication, taxonomy drift, and missing context. If teams use different names for the same product, segment, or use case, that inconsistency will echo into content and AI retrieval.
Phase 2 Implement and Standardize
Build the normalization layer. Standardize fields, event names, customer states, category labels, and content vocabulary. Consolidate profiles in a CDP or equivalent environment so that activation operates on one defensible customer view rather than departmental approximations.
This phase determines whether Signal Fidelity is possible. Without standardization, every later tactic becomes noisy.
Phase 3 Activate and Measure
Use direct customer signals to shape content, search experiences, documentation, and public proof assets. Pull repeated questions from site search and support. Translate those questions into answer-first pages. Use segmentation to reveal which topics matter by persona, industry, or buying stage.
Then measure at the answer layer. Track Share of Answer, citation behavior, branded demand shifts, and sentiment in generated responses. That is the level where AI-era competition occurs.
Phase 4 Optimize and Scale
Refine continuously. Expand the evidence footprint around winning topics. Retire pages that duplicate or confuse entity signals. Strengthen corroboration on external surfaces where the brand needs more validation. Recheck whether user behavior still aligns with claimed expertise.
This is not a marketing side project. It serves as a category-defense system. Brands that approach first-party data strategy as an AI authority program will influence how machines describe their market. Brands focusing solely on audience targeting risk allowing competitors to shape that narrative.
Chapter 1 remains the reference point because the core premise doesn't change: owned, consent-based customer evidence is the foundation of AI visibility. The path back to the beginning is simple for teams that need the full argument again. Return to Chapter 1.
Algomizer helps brands win visibility inside AI-generated answers across platforms such as ChatGPT, Claude, Gemini, and Perplexity by turning content, media, and technical signals into citation-ready authority. Teams that want a practical assessment of where their brand stands in AI search can book a call with Algomizer.