LLM Rank Tracker Guide: Measuring AI Visibility in 2026
Learn how an LLM rank tracker measures AI search visibility. This guide explains metrics, tools, and the shift from SEO to Generative Engine Optimization (GEO).

Date: June, 2026
Chapter 4
Rank tracking lost its original function once answer engines stopped returning pages and began assembling evidence.
Our research position is straightforward. AI visibility depends less on page placement and more on whether a model recognizes your brand as a credible source to cite, mention, or recommend. That shift changes the measurement logic inherited from SEO and introduces a new operational question: are you becoming part of the model's answer set?
This is the foundation of GEO, our framework for generative engine optimization. GEO uses an LLM rank tracker as an instrumentation layer for authority. Teams using a ChatGPT rank tracker for AI visibility analysis are measuring whether their content remains present through retrieval, synthesis, and citation inside generated responses.
The broader market has already recognized that generative search changes how discovery works, as discussed in AI's impact on search and SEO. Our conclusion extends that idea. Discoverability remains important, and citability has become the primary objective.
An LLM rank tracker, used correctly, shows whether a brand appears in model outputs, how often it is named, and whether the model uses it as support for an answer. That is the category definition that matters.
GEO succeeds or fails at the operating-model level
Phase 3 captures competitor-held answer space
The right checklist exposes weak architecture fast
Most vendors retrofit SEO logic into AI measurement
Evaluating Tracker Vendors The Old Way vs The Algomizer Way
Evidence Clusters and Semantic Density raise both metrics
The proprietary framework is citable authority, not page authority
GEO replaces SEO because LLMs choose evidence, not pages
Rank tracking ended when answers stopped being lists
Table of Contents
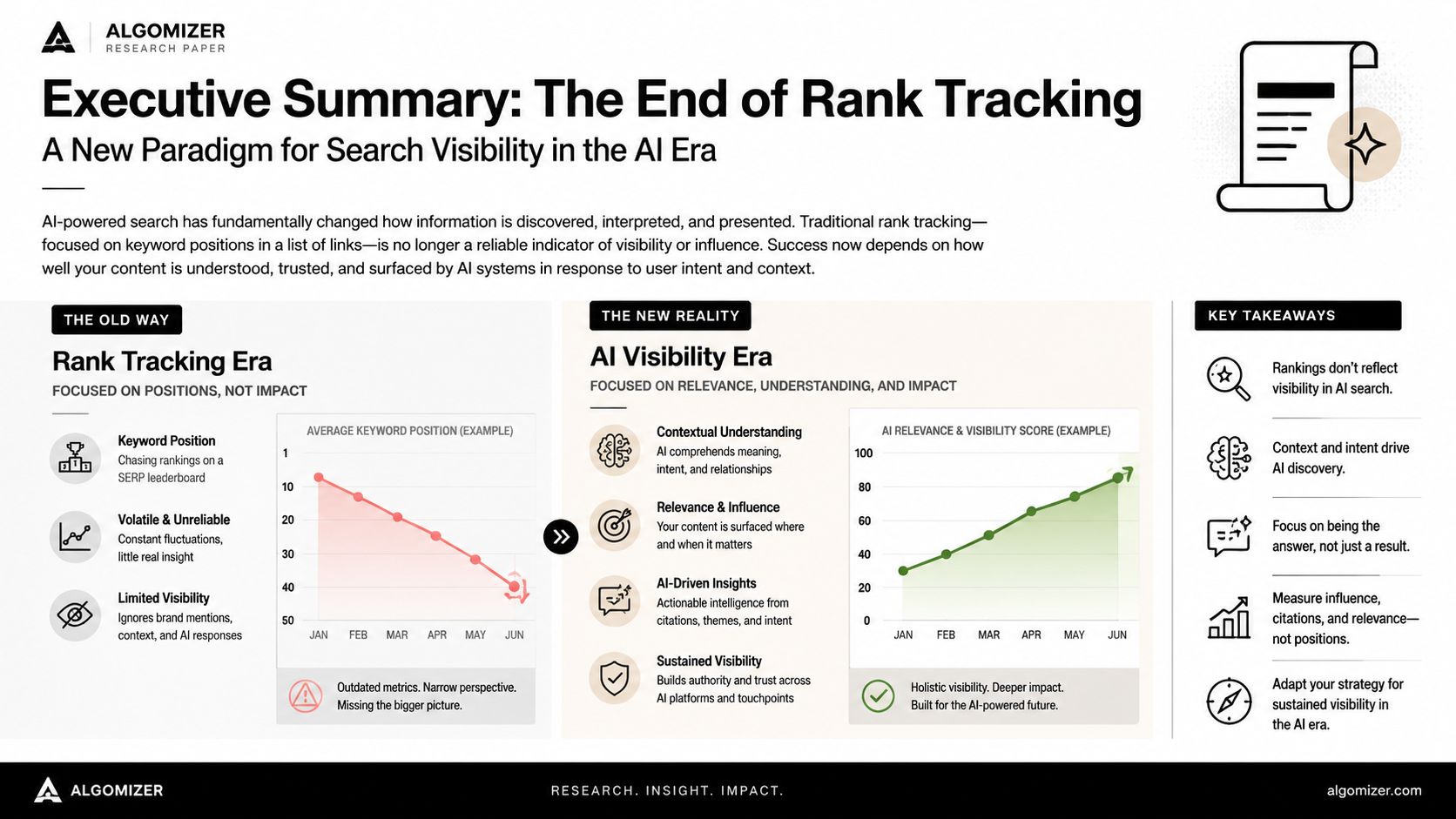
Executive Summary The End of Rank Tracking
Rank tracking changed when answers stopped being lists
GEO focuses on evidence selection inside LLM answers
The proprietary framework centers on citable authority
The Core Mechanics of LLM Rank Trackers
A real tracker measures generated behavior under live conditions
Headless browsers capture the rendered answer layer
The pipeline is prompt discovery, response capture, and classification
New Metrics for a New Medium Mention and Citation Rates
Mention rate is the baseline score
Citation rate is the stability signal
Evidence Clusters and Semantic Density support both metrics
Evaluating Tracker Vendors
Many vendors carry SEO assumptions into AI measurement
The right checklist clarifies architecture quickly
A Tactical Roadmap for Implementing LLM Tracking
GEO succeeds through operating-model discipline
Phase 1 establishes prompt reality
Phase 2 turns content into citable evidence
Phase 3 expands share of answer space
Phase 4 calibrates against drift
Conclusion The Shift From Discoverability to Citability
Citability is the new competitive moat
The brands that adapt will shape the answer layer
Executive Summary The End of Rank Tracking
Rank tracking changed when answers stopped being lists
Rank tracking changed once answer engines began composing responses from evidence instead of presenting ordered links. The unit of competition is now source inclusion inside a generated answer.
That change requires a new measurement framework. An LLM can mention a brand, cite it, paraphrase it, or omit it while drawing on several sources in the same response. A page may still perform well in traditional search and contribute little to AI responses. Analysts need a framework that measures whether a brand enters the model's reasoning path and remains present after synthesis.
GEO focuses on evidence selection inside LLM answers
SEO focused on retrieval. GEO focuses on citability.
The distinction is operational. Retrieval asks whether a page can be found. Citability asks whether a model sees the underlying claims, entities, and references as credible enough to reuse in an answer. That standard is more demanding because LLMs compress multiple inputs into a single response and assign uneven weight to each source. For leadership teams assessing the broader market shift, SharedTEAMS offers a useful framing of AI's impact on search and SEO.
Traditional search rewarded position. Generative search rewards source inclusion.
A useful tracker measures visibility at the answer level. Key signals include mention presence, citation behavior, recommendation frequency, and stability across prompt variation. These show whether a brand is becoming usable evidence inside AI systems.
The proprietary framework centers on citable authority
Our GEO framework is built around citable authority. We define it as the condition in which a model repeatedly treats a brand's content, claims, and corroborating references as valid material for answer construction.
We evaluate that condition through three signals:
Evidence Clusters: Groups of pages, references, and supporting mentions that reinforce the same claim set across related prompts.
Semantic Density: The clarity with which a page expresses entities, relationships, definitions, and constraints that a model can reliably extract.
Citation Persistence: The recurrence of mentions or citations across prompt rewrites, model updates, and adjacent query contexts.
This framework changes how teams should use tracking software. A model-specific tool such as a ChatGPT rank tracker for AI visibility analysis is an instrument for testing whether your authority remains present through retrieval, synthesis, and response generation.
Return to Chapter 1: Executive Summary | Book a call with the strategy team to assess brand AI visibility. (utm_source=blog4)
The Core Mechanics of LLM Rank Trackers
A real tracker measures generated behavior under live conditions
LLM rank tracking is a measurement system for probabilistic answer generation. That distinction shapes the entire category.
A serious tracker recreates the conditions under which users query ChatGPT, Perplexity, Claude, and similar systems, then observes how often a brand becomes part of the answer layer. The system needs to test prompt variation, model variation, and citation behavior across repeated runs. Repeated sampling helps analysts separate stable patterns from one-off responses and reduces the risk of building GEO strategy on noise.

Headless browsers capture the rendered answer layer
The measurement target is the answer a user sees on screen. API calls can miss part of that object. They may omit rendered citations, interface-level formatting, session behavior, and regional differences that affect what users read and click.
Headless browser infrastructure closes that gap by interacting with the product interface directly. It submits prompts, waits for the full response state, extracts visible links and answer structure, and stores the exact output that appeared in the session. For teams that want a technical primer on why this variability exists, Flaex provides a useful overview in large language models explained.
Our rule is simple. If a tracker cannot reproduce the rendered interface, it is not measuring the same object the customer sees.
That requirement marks a clear shift in tooling. Search rank trackers measured ordered documents on a results page. LLM trackers measure generated narratives, source attributions, and answer framing inside a live interface. The architecture resembles an experimental system more than a crawler.
A sound implementation records more than presence or absence. It logs citation links, response structure, brand placement inside the answer, and sentiment direction. Those fields let analysts distinguish incidental mentions from durable authority signals.
A quick visual walkthrough helps clarify the sequence.
The pipeline is prompt discovery, response capture, and classification
Under the hood, LLM tracking follows a three-part pipeline.
Prompt reverse-engineering: The system maps a company, product set, and topic area into likely user queries using entity extraction, semantic clustering, and intent grouping.
Cross-model execution: It runs those prompt sets across multiple LLM environments and stores the generated outputs at scale.
NLP classification: It identifies mentions, citations, answer role, and sentiment state, then aggregates the results at the prompt-cluster level.
Weak vendors often over-interpret limited data. They treat one prompt as one conclusion. That approach produces snapshots rather than dependable measurement.
Our GEO framework uses repeated prompt clusters because authority in AI systems is conditional. A brand may appear consistently for comparative prompts, disappear for diagnostic prompts, and earn citations only when the answer requires evidence. These patterns become visible when tracking is designed around prompt families, model variance, and repeat observation.
That is also why mature programs need a dedicated layer for AI citation analysis for search engines, even if they already use enterprise SEO software. GEO rewards citable authority across the answer layer.
Return to Chapter 1: Executive Summary | Book a call with the strategy team. (utm_source=blog5)
New Metrics for a New Medium Mention and Citation Rates
Mention rate is the baseline score
Rank is no longer the best unit of analysis for AI answers. In GEO, mention rate is the first check because it shows whether a model includes your brand in the answer layer at all.
That sounds simple, but the measurement shift is material. Ana Perez Botella's overview of mention and citation tracking tools separates "brand mentions in generated responses" from "linked or attributable source references." That distinction supports the operating model we use with clients. A mention shows retrieval and inclusion. It does not necessarily show that the model treated the brand as evidence.

Mention rate therefore functions as a floor. If your brand is absent, authority has not formed. If your brand appears often without attribution, authority remains fragile because the model can substitute a nearby entity in the same topic cluster.
Citation rate is the stability signal
Citation rate measures a more defensible form of visibility. It tracks how often the answer points back to a source the model is willing to use as support.
That is a stricter standard than mention presence. It indicates that your material is recognized and selected during answer construction. Over repeated prompt sets, citation rate also becomes a stability signal because citation behavior tends to persist when the source is structurally easy to extract, semantically aligned to the query, and corroborated elsewhere.
Metric | What it measures | Why it matters |
|---|---|---|
Mention rate | How often the brand appears in answers | Baseline presence in the answer layer |
Citation rate | How often the answer directly links to the source | Source selection and attributable authority |
Citation persistence | Whether citations recur across prompts and model refreshes | Stability under prompt variation and model change |
A mention confirms inclusion. A citation shows that the model found support it could use.
Evidence Clusters and Semantic Density support both metrics
Our GEO framework ties these metrics to two controllable inputs.
Evidence Clusters increase corroboration across the open web and owned assets. The goal is claim consistency. A company page, product documentation, third-party references, and category pages should reinforce the same entity definitions and factual statements so models encounter converging evidence.
Semantic Density increases extractability. Pages with clear entity naming, constrained claim structure, explicit relationships, and sourceable facts are easier for models to parse and cite. This is also why old ranking heuristics have limited value here. Outrank's recommended ranking tools remain useful for understanding traditional position tracking, though they do not measure whether a model treats your content as support inside a generated answer.
Teams that want a tighter read on source trust usually pair mention tracking with source-level citation analysis for AI search engines. The objective in GEO is citable authority.
Return to Chapter 1: Executive Summary | Book a call with the strategy team. (utm_source=blog6)
Evaluating Tracker Vendors
Many vendors carry SEO assumptions into AI measurement
The category is crowded because adoption accelerated quickly. The number of enterprise brands monitoring AI visibility has increased by over 350% since November 2022, and brands actively optimizing for GEO have seen a 40-60% increase in AI-driven referral traffic within 3-6 weeks according to industry reporting on LLM rank trackers.
That growth produced two broad vendor approaches. Some repurpose SEO tooling and add AI labels. Others build from the mechanics of generated answers.
For buyers comparing legacy software options, lists of recommended ranking tools remain useful background. They also highlight a category gap. Most ranking tools were designed for position tracking rather than synthesis tracking.
The right checklist clarifies architecture quickly
The fastest way to evaluate a vendor is to ignore branding and inspect the measurement model.
Criteria | Repurposed SEO Tools | GEO-Native Approach |
|---|---|---|
Measurement technique | API sampling and limited snapshots | Headless browser simulation across live interfaces |
Core metric | Keyword rank or approximated position | Mention rate, citation rate, and share of voice |
Optimization focus | On-page SEO adjustments | Evidence Clusters, source inclusion, and citable authority |
Prompt model | Small fixed list | Diverse clustered prompts with repeated sampling |
Reporting object | URL placement | Brand presence inside answer composition |
Business logic | Software subscription | Outcome-oriented visibility work |
A buyer should ask five direct questions:
What is measured: If the vendor talks mainly about positions, the product is using an outdated framework.
How prompts are generated: Thin prompt sets create unstable visibility models.
Whether citations are verified: If links are not inspected, authority claims are harder to trust.
How model variance is handled: Aggregation logic is necessary for reliable interpretation.
What action follows measurement: Dashboards help, and teams still need an execution layer.
One option in this category is software for AI visibility in search, including services that track mentions and citations across major LLM environments rather than approximating blue-link rank. The distinction changes what leadership can trust.
Return to Chapter 1: Executive Summary | Book a call with the strategy team. (utm_source=blog7)
A Tactical Roadmap for Implementing LLM Tracking
GEO succeeds through operating-model discipline
LLM tracking creates value when it changes how a team sets priorities, rewrites evidence, and measures authority over time. A dashboard informs the work. A disciplined GEO program drives citability.
The practical sequence is baseline, engineer, expand, calibrate. We use this cycle because AI answer visibility is unstable by design. Models update, retrieval layers shift, and citation patterns change as new source material enters the corpus. Teams that treat LLM tracking as a recurring operating system build durable share of voice inside generated answers.
Phase 1 establishes prompt reality
The first failure usually appears before measurement begins. Internal teams often select prompts based on what sales, product, or brand leaders expect users to ask. LLMs do not organize demand that neatly.
A credible baseline starts with prompt clusters. We group branded, comparative, problem-aware, and category prompts, then test mention presence, citation presence, and answer framing across repeated runs. That process shows where the model already associates the brand with a decision, where it omits the brand, and where a competitor has become the default cited source.
Track prompt clusters, not vanity keywords.
This phase also creates the benchmark for every later intervention. With that benchmark, teams can tell whether a content revision improved inclusion, changed answer framing, or simply coincided with normal model variance.
Phase 2 turns content into citable evidence
Once the baseline is clear, the work shifts from observing output to shaping input. The objective is evidence a model can extract, compress, and cite with low ambiguity.
That changes how teams revise pages. Priority assets should define entities clearly, answer adjacent questions directly, surface claims that can be verified, and present supporting references in a format retrieval systems can parse. In GEO, page quality includes synthetic usability for models alongside readability for humans.
Evidence Clusters become operational here. Instead of publishing isolated pages, teams build connected source sets around a topic, claim, or commercial use case. This increases the odds that a model encounters consistent language, aligned entities, and corroborating material across multiple retrieval paths.
Phase 3 expands share of answer space
After content engineering, the prompt set expands into contested territory. The mechanism is precision.
We identify prompts where rivals are regularly cited, then map the underlying inclusion logic. Sometimes the winning source is more specific. Sometimes it defines the category more clearly. Sometimes it packages evidence in a structure the model can quote with minimal reconstruction. Those distinctions matter because they show what the model is rewarding.
A practical roadmap looks like this:
Baseline assessment: Measure current mention and citation presence across the highest-value prompt clusters.
Content engineering: Restructure priority pages around entities, definitions, and supporting references.
Competitive conquesting: Target prompts where rival brands are cited and the brand is absent.
Calibration loop: Re-run tracking after each intervention and compare persistence, not only first appearance.
The goal is citable authority. Teams advance by publishing the clearest source in the decision space, then verifying that models use it.
Phase 4 calibrates against drift
AI visibility decays when teams assume a citation is permanent. It is not. Model refreshes, retrieval changes, source replacement, and new competitor material can all displace a previously cited brand.
That is why we treat citation velocity and persistence as operating signals. Analysts should monitor how quickly a brand appears after changes go live, how long those mentions remain stable across prompt clusters, and where substitution begins. A temporary mention spike is less valuable than a smaller but persistent citation footprint across high-intent prompts.
The result is a closed GEO loop. Measure answer behavior. Engineer evidence. Pressure-test competitor territory. Recalibrate after every model or content shift.
Teams that institutionalize this process do more than observe AI search. They build source authority that models can cite repeatedly.
Return to Chapter 1: Executive Summary | Book a call with the strategy team. (utm_source=blog8)
Conclusion The Shift From Discoverability to Citability
Citability is the new competitive moat
The old web rewarded pages that were easy to crawl, index, and rank. The answer layer rewards sources that are easy to trust, synthesize, and cite.
That is why LLM rank trackers sit in the GEO category. They analyze conversational AI output rather than traditional SERP URL positions, shifting attention toward brand mention and citation rate as described in this overview of GEO-native LLM rank tracking tools.
Discoverability still matters. It is simply not enough on its own. A discoverable page may still have limited presence inside the answer itself.
The brands that adapt will shape the answer layer
The deepest mistake in current search strategy is treating AI interfaces as another distribution channel for SEO. They function as a synthesis layer with their own inclusion logic.
That changes what leadership should fund, what teams should measure, and what content should become. The target asset is a body of evidence that a model can repeatedly convert into an answer.
An LLM rank tracker is therefore the instrument panel for Generative Engine Optimization. It tells a company whether the model sees the brand, trusts the brand, and cites the brand when the decision moment arrives.
Brands that continue to optimize only for positional discoverability will keep losing visibility in the moments where users increasingly ask for judgment, comparison, and recommendation. Brands that engineer citability will shape those moments.
Return to Chapter 1: Executive Summary | Book a call for a complimentary visibility assessment. (utm_source=blog9)
Algomizer helps brands measure and improve visibility inside AI-generated answers across platforms such as ChatGPT, Claude, Gemini, and Perplexity. Teams that need a practical GEO partner can book a call with Algomizer for a complimentary visibility assessment.