Increasing Brand Visibility: Master AI Search GEO
Unlock a new framework for increasing brand visibility in AI search. Learn 2026 Generative Engine Optimization (GEO) tactics for CMOs.

An Algomizer Research Paper on GEO, recall systems, and the mechanics of AI-era discovery
Date: April, 2026
Executive Summary
Brand visibility no longer depends on winning a rank position. It depends on becoming the source an AI system chooses to cite, compress, and repeat.
That shift changes the operating model for marketing leaders. Search still sits at the center of discovery. 32.8% of worldwide internet users report discovering new brands and products via online search in DataReportal’s Digital 2025 reporting, which places search slightly ahead of TV ads at 32.3% and confirms that visibility still starts in search behavior, even as the interface changes (DataReportal Digital 2025 brand discovery findings).
What changed is the retrieval layer. Buyers increasingly encounter synthesized answers before they encounter websites. In that environment, traditional SEO remains a supporting discipline, not the engine of visibility. The engine is Generative Engine Optimization, or GEO. GEO treats visibility as an engineering problem: which claims get retrieved, which sources get trusted, and which brands become part of a model’s answer pattern.
Marketing teams looking for practical supporting reads on distribution and brand presence can also review OneNine’s collection of actionable brand building strategies. But those tactics need a new control layer. They need to be designed for citation, not just exposure.
The practical divide between answer engines and classic search is captured well in this breakdown of AEO vs SEO vs GEO. The point is simple. A page can rank and still remain absent from AI answers. A brand can publish heavily and still fail recall if its evidence footprint is fragmented.
This paper argues that increasing brand visibility now requires two engineered assets: Evidence Clusters and Semantic Density. The first creates distributed corroboration. The second makes content legible to large language models. Together they replace the outdated idea that visibility is mainly a function of links and rankings.
Table of Contents
The End of SEO as the Engine of Visibility
SEO lost exclusivity over discovery
Visibility now means citation
The New Battlefield for Brand Recall
The unit of visibility has changed
Recall now depends on repeated citation
The Algomizer Framework for Engineering Truth
Evidence Clusters create defensible recall
Semantic Density makes claims retrievable
Contrasting Legacy SEO and Modern GEO
The operating system changed
Share of Voice bridges old metrics and new outcomes
The Three Pillars of GEO Implementation
Content engineering comes first
Authority must exist off-site too
Technical structure determines parse quality
How to Measure What Truly Matters in AI Search
Rank tracking misses the actual outcome
The right KPIs focus on citation presence
Conclusion From Chasing Clicks to Becoming Truth
The End of SEO as the Engine of Visibility
SEO lost exclusivity over discovery
Search still matters. Search no longer behaves the way most marketing teams assume.
The older model was straightforward. A user entered a query, scanned ranked links, clicked a result, and judged the brand after landing. That workflow made the webpage the basic unit of competition. It also made ranking the dominant proxy for visibility.
That model is breaking. AI systems like ChatGPT and Gemini increasingly intercept the discovery step by synthesizing an answer before the user ever evaluates a result set. The commercial implication is severe. Ranking a page is not the same as controlling the answer.
Research claim: Increasing brand visibility in AI-era search requires brands to optimize for retrieval and citation, not only for click acquisition.
Visibility now means citation
Brand leaders still inherit a language built for classic SEO. They talk about impressions, rankings, and click-through rates. Those metrics describe a list-based interface. AI search uses an answer-based interface.
That interface changes what a brand must produce. It must publish claims that can be extracted cleanly, validated across multiple contexts, and repeated without distortion. In practical terms, the visible asset is no longer the URL. It’s the evidence-bearing content fragment.
Traditional SEO assumptions fail here for three reasons:
Ranking doesn’t guarantee recall: A strong page can exist without becoming part of an LLM’s response pattern.
Backlinks don’t equal answer inclusion: Link equity alone doesn’t tell a model which claim to repeat.
Clicks are delayed signals: By the time traffic appears, the brand may already have lost the recommendation layer.
The strategic result is stark. Marketing teams that still treat SEO as the sole engine of discovery are optimizing distribution while neglecting cognition. They are trying to win the shelf while the purchase decision has already moved into the assistant.
Book a call to assess your AI search visibility (utm_source=blog1).
The New Battlefield for Brand Recall
The unit of visibility has changed
Brand recall now forms through repeated presence inside synthesized answers, not just through repeated exposure to pages, ads, or posts.
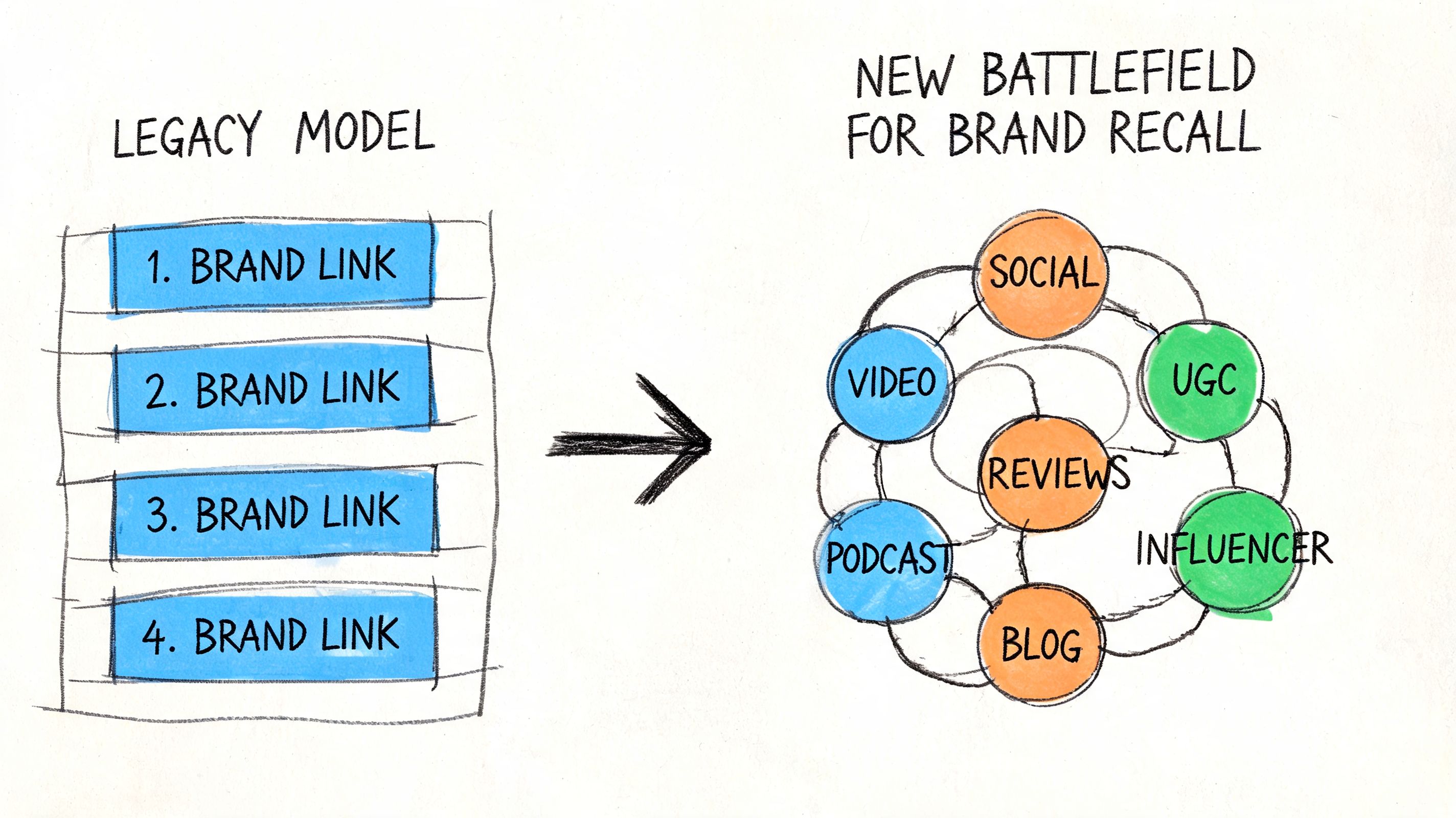
The legacy web rewarded page prominence. The AI web rewards claim portability. A model does not need to reproduce an entire article to make a brand memorable. It only needs to surface a few coherent facts, associations, and source cues across multiple prompts. That is enough to shape market perception.
This is why old visibility dashboards feel increasingly disconnected from reality. A brand can hold respectable rankings yet disappear in conversational discovery if its claims are diffuse, unsupported, or linguistically weak.
Recall now depends on repeated citation
The older marketing principle still applies, but in a different medium. Achieving brand recall traditionally requires 5-7 exposures, often referred to as the Marketing Rule of Seven, and that logic now extends to repeated citation within AI-generated answers (branding statistics reference including the Rule of Seven).
That doesn’t mean a brand needs the same answer repeated verbatim. It means the brand needs to appear consistently enough that the model treats it as a stable option in category-level reasoning.
A modern recall loop looks more like this:
Prompt exposure: A user asks a broad or evaluative question.
Claim retrieval: The model selects a compact set of supporting facts.
Brand attachment: The answer links those facts to a named company or product.
Repeat encounter: The same brand appears again in a later query, adjacent topic, or follow-up.
Repetition in AI search isn’t media frequency. It’s citation recurrence under varied prompts.
This is why source integrity matters more than ever. Large language models synthesize from disparate materials. They compress, compare, and normalize. If a brand’s evidence appears inconsistent across the web, the model has less reason to privilege it. If the evidence aligns, the model can reuse it with confidence.
The primary battlefield for increasing brand visibility is therefore not the SERP alone. It is the model’s internal decision about which brand is safe to mention again.
Return to Chapter 1.
The Algomizer Framework for Engineering Truth
SEO did not evolve into AI visibility. It lost control of the interface. In answer-first systems, the winning unit is no longer the page. It is the claim package the model can retrieve, verify across sources, and restate without distortion.
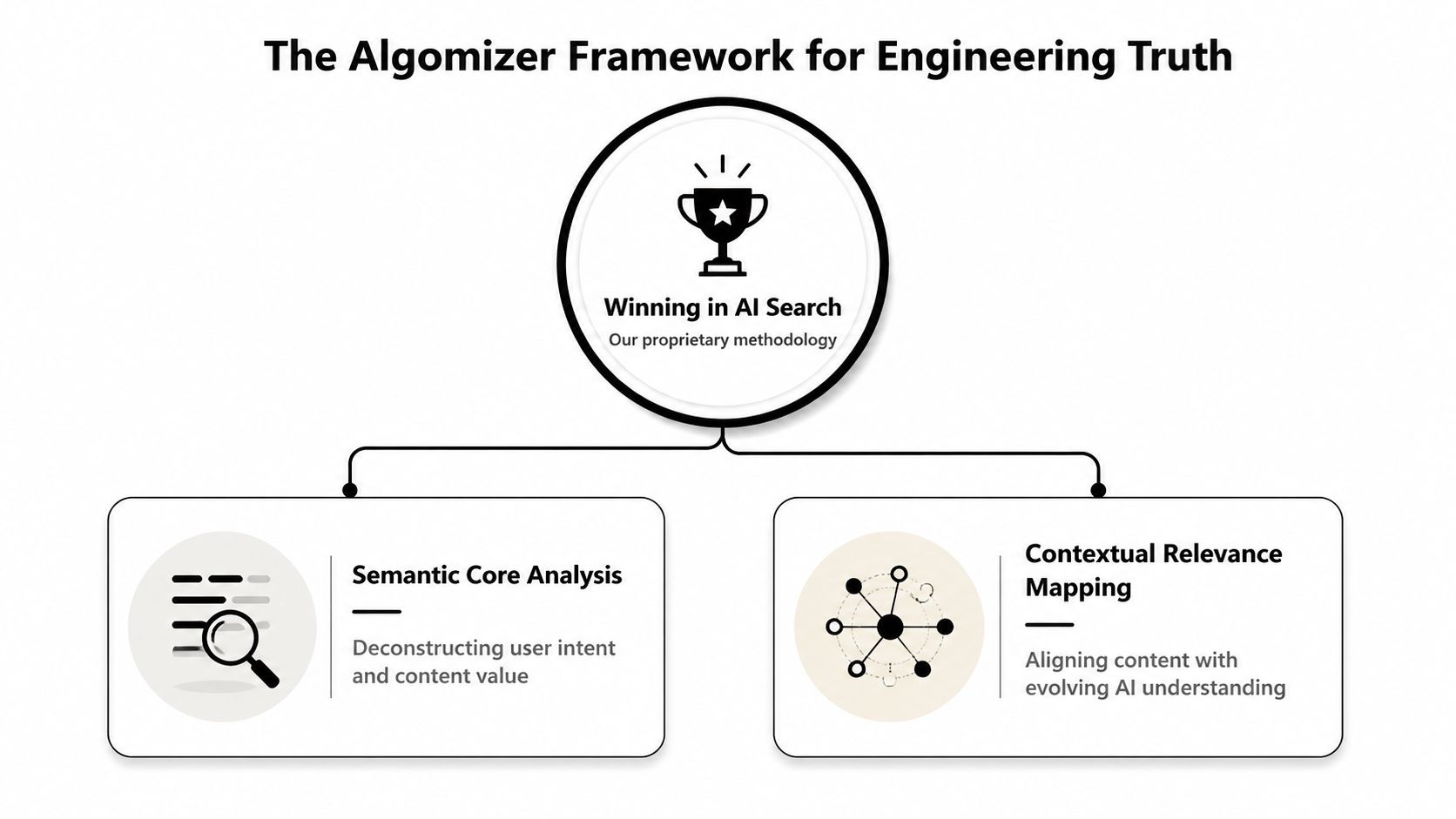
Algomizer’s framework starts from that premise. It treats visibility as an engineering problem inside language models, not a traffic problem inside search result pages. Two mechanisms drive the outcome: Evidence Clusters and Semantic Density.
Evidence Clusters create defensible recall
An Evidence Cluster is a distributed body of aligned proof. It spans owned pages, documentation, earned media, partner references, structured data, expert commentary, and other public artifacts that express the same commercial truth with consistent terminology and verifiable detail.
LLMs do not "believe" a homepage; instead, they infer reliability from repetition under variation. A claim that appears in several credible contexts with matching entities, definitions, and supporting details is easier to retrieve and safer to cite. A claim that appears once, or appears in conflicting forms, creates ambiguity that lowers citation probability.
A strong cluster usually contains four components:
Category definition: explicit statements about the company’s market role and use case
Proof objects: named products, technical attributes, customers, processes, and other checkable facts
External reinforcement: third-party mentions that restate or validate the same position
Terminology discipline: stable phrasing across sources so models do not have to resolve unnecessary synonyms
Creative variation still has a role. It just cannot rewrite the underlying evidence every time a campaign changes. Teams refining campaign assets and message testing can use resources like AdCrafty’s AI-powered ad creative guide, but performance creative helps AI visibility only when the factual substrate stays consistent.
Semantic Density makes claims retrievable
Semantic Density measures how much extractable meaning a passage carries relative to its length. High-density passages give a model compact material it can lift, compare, and synthesize. Low-density passages force compression, and compression usually strips out brand-specific detail first.
For teams that need the model-layer definition behind this shift, Algomizer’s explanation of what LLMO means in practice clarifies why retrieval fit now matters as much as ranking.
The writing implications are concrete:
State the answer early: put the core claim near the top of the section
Use precise nouns: name the category, product, audience, and technical concept directly
Bind proof to claims: pair assertions with facts, examples, or sourceable details
Cut low-information transitions: passages with slow setup give retrieval systems less usable material
A simple test works well here. If a sentence is extracted alone and loses meaning, it is unlikely to survive retrieval intact.
One implementation path is to use a managed platform that tracks visibility across ChatGPT, Claude, Gemini, and related systems while combining media placement, content engineering, technical implementation, and ongoing calibration. Algomizer is one example of that model.
The framework is straightforward. Evidence Clusters increase cross-source agreement. Semantic Density improves extraction quality. Combined, they raise the odds that a model will attach your brand to a category claim inside the answer itself.
Contrasting Legacy SEO and Modern GEO
The operating system changed
Traditional SEO optimizes pages for rank. GEO optimizes claims for retrieval, synthesis, and citation.
That difference is not cosmetic. It changes budget allocation, content design, PR strategy, and measurement. Teams that understand the mechanics of LLM retrieval can see why classic optimization models produce diminishing returns when the interface shifts from links to answers.
For a deeper operational definition of the model layer itself, this overview of what LLMO means in practice helps frame the distinction.
Dimension | Traditional SEO | Generative Engine Optimization (GEO) |
|---|---|---|
Primary goal | Rank a URL in search results | Become a cited source in AI-generated answers |
Core unit | Webpage | Claim, passage, and evidence chunk |
Main optimization object | Keywords, links, on-page signals | Retrieval fit, corroboration, semantic clarity |
Distribution logic | Capture clicks from rankings | Shape model recall across prompts |
Trust signal | Link authority and SERP performance | Evidence Clusters, source quality, repeated alignment |
Content style | Comprehensive page targeting | Dense, extractable answer components |
Success state | Higher position and more traffic | Higher citation presence and stronger category attachment |
Share of Voice bridges old metrics and new outcomes
Not every legacy metric should be discarded. Some still matter because they measure market attention rather than interface behavior.
One of the most useful examples is Share of Voice. In media and search analytics, a 10% increase in SOV across media mentions is associated with a 15-20% uplift in branded search volume and direct URL visits (TechnologyCounter on brand visibility metrics). That matters because AI systems are more likely to encounter, compare, and reuse brands that already occupy a larger share of the public information layer.
The implication is not that SEO disappears. The implication is that SEO becomes one contributing input to a broader retrieval system. GEO absorbs search, PR, content design, and source architecture into one visibility function.
SEO asked, “Can the page rank?”
GEO asks, “Will the model trust this claim enough to repeat it?
The Three Pillars of GEO Implementation
Brand visibility in AI search is engineered. It does not emerge from publishing volume, keyword coverage, or intermittent PR activity.
Content engineering comes first
The first pillar is content engineering. In AI retrieval, the unit of competition is not the page. It is the extractable claim.
Pages that earn reuse inside model answers share a specific profile. They answer the core question early, define the category with precision, and attach each important claim to language that can survive quotation, summarization, or retrieval compression. Internal testing at AI search labs has shown the same pattern repeatedly. Citation presence improves when content is written as a set of evidence-bearing statements rather than as a narrative optimized for scroll depth.
That is the logic behind Evidence Clusters and Semantic Density. Evidence Clusters group the claims, definitions, comparisons, and proof points a model needs to reproduce a brand accurately. Semantic Density measures how much unambiguous meaning a passage carries per sentence. Low-density copy forces inference. High-density copy reduces inference and raises recall fidelity.
A practical content engineering checklist looks like this:
Front-load the answer: Start with the clearest response, then support it.
State category fit clearly: Specify what the brand is, who it serves, and where it fits.
Write evidence-bearing sentences: Use factual phrasing, concrete attributes, and attributable claims.
Reduce ambiguity: Keep one consistent description for each offer, feature, and category position.
Teams refining prompt-level retrieval behavior should review this guide on how to rank in ChatGPT.
Authority must exist off-site too
The second pillar is authoritative media placement. Models do not infer trust from owned pages alone. They infer trust from repeated agreement across the public web.
This changes the job of PR, analyst relations, founder visibility, and expert commentary. Off-site mentions should reinforce the same category framing, product description, and proof structure found on the brand site. A scattered media footprint creates semantic conflict. A coordinated footprint creates corroboration. In retrieval systems, corroboration is often the difference between being mentioned and being ignored.
The strategic mistake is treating external coverage as a top-of-funnel awareness program. In AI search, it functions as a validation layer for model memory.
This section benefits from a visual walkthrough of how AI visibility changes by platform and answer format.
Technical structure determines parse quality
The third pillar is technical implementation. Retrieval systems reward legibility.
Schema still matters, but rich results are no longer the main reason to use it. The larger issue is parse quality. Entity consistency, heading logic, list structure, document hierarchy, and markup all affect whether a system can resolve who the company is, what it offers, and which claims belong to which entity. Weak structure increases interpretive error. Strong structure reduces it.
A practical rollout usually follows three tracks:
Entity normalization: Keep brand names, product names, and service descriptions consistent across site and third-party references.
Structured context: Use markup and page architecture that clarify who, what, and where.
Prompt alignment testing: Evaluate whether target queries surface the intended claims.
Treating GEO as a copywriting variation on SEO misses the mechanism. GEO is an engineering discipline across content design, external evidence, and machine-readable structure.
How to Measure What Truly Matters in AI Search
Rank tracking misses the actual outcome
Most visibility reporting still measures positions, sessions, and click patterns. Those metrics describe a world where users must choose among links.

AI search changes the event to be measured. The decisive moment is whether the brand appears in the answer, how prominently it appears, and what context surrounds the mention. Keyword rankings can still inform input quality, but they no longer define output visibility.
This blind spot is widespread. Only 15% of brands are effectively tracking their citations and visibility within AI-generated answers, which leaves most firms unable to see their actual performance in this channel (BrandGeko on AI visibility tracking gaps).
The right KPIs focus on citation presence
A workable AI visibility system needs metrics that match AI behavior. Three KPIs matter most.
Citation rate: How often the brand appears across target prompts and platforms.
AI Share of Voice: How frequently the brand appears relative to category competitors.
Context quality: Whether the surrounding language is favorable, neutral, or exclusionary.
These metrics usually require headless browser tracking because APIs don’t always expose the final answer experience consistently across ChatGPT, Claude, Gemini, and Perplexity. The point is measurement fidelity. A brand needs to know what the user saw.
Visibility in AI search is not a ranking position. It is observed inclusion under live query conditions.
A strong measurement workflow also separates prompt classes. Navigational prompts, comparative prompts, local-intent prompts, and product-research prompts often produce very different citation patterns. Without that segmentation, teams misread partial presence as market visibility.
Conclusion From Chasing Clicks to Becoming Truth
Increasing brand visibility used to mean winning attention. In AI search, it means winning acceptance inside the answer layer.
That is a different ambition and a more durable one. Rankings fluctuate. Paid reach decays. Clicks remain downstream artifacts. But a brand that becomes a repeated, trusted citation in category-level answers occupies a stronger position. It shapes preference before the visit, before the demo request, and often before the shortlist even forms.
The old search playbook taught marketers to chase surfaces. The new one requires engineering retrieval conditions. Evidence Clusters create corroboration. Semantic Density creates extractability. Measurement confirms whether the model is repeating the brand where category decisions are made.
Marketing leaders that want a practical complement to internal tracking can review frameworks for how to monitor brand visibility in AI search. The larger conclusion remains unchanged. Visibility is no longer a publishing problem alone. It is a systems problem spanning language, evidence, and retrieval.
Return to Chapter 1. Book a call to become the authority in your category (utm_source=blog7).
Algomizer helps brands understand how AI platforms interpret, cite, and recommend them across systems like ChatGPT, Claude, Gemini, and Perplexity. Teams that need a visibility assessment, citation tracking, and GEO implementation can book a call with Algomizer.