
Query Fan Out in AI Search: Boost Brand Visibility
Understand query fan out in AI search. See how LLMs use sub-queries and discover strategies for brands to boost visibility in AI answers for 2026.

Query fan out is the visible trace of a deeper retrieval redesign
Date: June, 2026
Search no longer evaluates one query against one result set. Google described AI Mode as taking a single question and issuing “a multitude of queries simultaneously,” a public acknowledgment that retrieval has shifted from a linear model to a parallel one, as documented by Aleyda Solis on Google query fan-out.
That changes the optimization target. A brand now vies for inclusion across a diverse array of hidden sub-queries, source types, and synthesis steps, rather than just a single ranking position.
The consequence is counterintuitive. A page can still rank well in traditional search and remain structurally absent from AI answers because it only satisfies one branch of the retrieval graph.
Table of Contents
Executive Summary Deconstructing Query Fan Out
Fragmentation is the new discovery layer
The strategic mistake is treating fan out like keyword expansion
The Mechanics of Multi-Query Retrieval
Query fan out is a retrieval dispatch system
Parallel retrieval changes what counts as relevance
The Algomizer Framework Semantic Broadcasting
Semantic Broadcasting engineers retrievability across branches
Evidence Clusters outperform isolated pages
A Data-Driven Contrast Traditional SEO vs GEO
The unit of optimization has changed
Legacy SEO measures the wrong battlefield
Tactical Patterns for Fan-Out Optimization
Content has to shard cleanly
Volatility determines how deep coverage must go
Monitoring and Measuring Fan-Out Coverage
Fan-out coverage is an observability problem, not a rank-reporting problem
Measure selection breadth, not just mention frequency
Conclusion The Inevitable Fragmentation of Search
Visibility now depends on distributed evidence
Executive Summary Deconstructing Query Fan Out

Fragmentation is the new discovery layer
Query fan out involves breaking down discovery into multiple parallel retrieval paths and then combining them into a single answer. It reflects a change in architecture rather than a feature upgrade.
The previous belief that visibility primarily originated from a single authoritative page is no longer valid. In AI retrieval, the system analyzes the user request, explores various informational perspectives, gathers data from different source categories, and selects fragments it can confidently synthesize. This results in a unified visible answer, although the underlying retrieval process is diverse.
Marketing teams that still optimize around a single primary keyword are working against the architecture. They are publishing for the visible interface while ignoring the hidden routing layer that now determines whether a source even enters the candidate set. That mismatch is why many brands feel discoverable in search reports and invisible in answer engines at the same time.
Practical rule: If a topic can be broken into subtopics, comparisons, validation checks, or next-step questions, an AI system will likely retrieve it that way.
The strategic mistake is treating fan out like keyword expansion
The typical understanding is limited. Query fan out involves machine-level decomposition and evidence synthesis rather than expanded keyword targeting.
The distinction is important as the retrieval system seeks a source environment that addresses multiple aspects of the prompt simultaneously. A content strategy aimed at exact-match ranking often results in narrow pages lacking strong connections between claims, context, and proof.
The stronger model treats visibility as a coverage problem. Brands need assets that can be selected for multiple hidden sub-queries, not just one visible search phrase. That is the basis for the framework introduced later in this paper: Semantic Broadcasting.
The rest of this chapter proceeds from mechanism to strategy. It deconstructs how multi-query retrieval works, identifies what AI systems reward at the citation layer, contrasts traditional SEO with generative optimization, and closes with a measurement model built for fragmented retrieval.
The Mechanics of Multi-Query Retrieval
Query fan out is a retrieval dispatch system
Query fan out functions as a retrieval dispatch system, breaking a primary user question into multiple parallel sub-queries that can be routed, evaluated, and recombined before an answer is generated.
That process matters because AI retrieval no longer depends on a single matching document. It depends on how well the system can decompose intent into research tasks, pull evidence from different source classes, and assemble a response with low ambiguity. Google has publicly described this pattern as issuing many queries simultaneously from one prompt. Independent technical analysis also shows that fan-out retrieval commonly spans multiple retrieval paths rather than one ranked list, as outlined in Julien Gourdon's technical explainer on query fan-out.
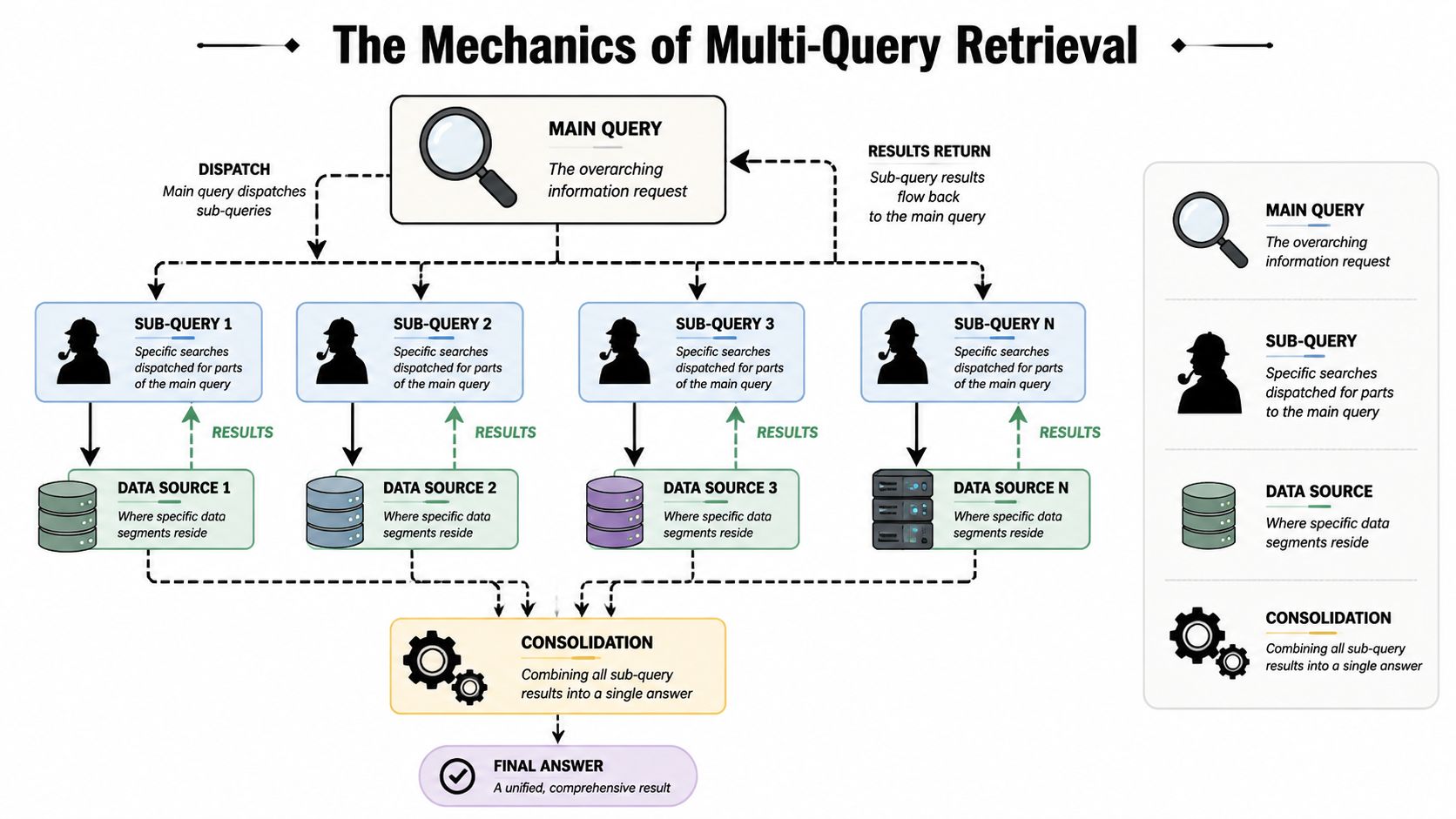
The operational sequence is straightforward:
Main query: The user submits one visible question.
Intent decomposition: The retrieval layer infers hidden tasks inside that question, such as definitions, comparisons, constraints, examples, validation checks, or local context.
Source routing: Each task is sent toward the source type most likely to satisfy it, including web pages, product feeds, knowledge graphs, reviews, forums, or proprietary indexes.
Evidence consolidation: The model weighs the retrieved fragments, resolves conflicts, and composes a single answer.
This architecture changes how brands should interpret visibility. A page is no longer competing only on phrase alignment. It is competing on whether its claims can survive decomposition and still be useful at the fragment level.
A product page might satisfy the attribute branch. A forum thread might satisfy the practical use branch. A documentation page might satisfy the verification branch. The answer engine can cite all three, even if none of them ranked first for the original phrasing.
A visual walk-through helps clarify the dispatch logic.
Parallel retrieval changes what counts as relevance
Parallel retrieval shifts relevance toward branch-level usefulness inside a distributed process. The winning source is often the one that resolves a specific sub-query cleanly enough for the model to reuse during synthesis.
That shift has a measurable strategic consequence. Content with strong topical adjacency, explicit constraints, and supportable claims can enter more branches of the retrieval tree than content built around a single exact-match phrase. This is the retrieval logic behind AI search engine optimization strategies. The goal is broader candidate-set inclusion across decomposed intents, not only higher rank for one query string.
The same principle explains why topic modeling methods such as semantic latent analysis remain useful, but only as an input. They help map adjacency. They do not explain branch selection on their own. The retrieval system still prefers sources that express those adjacent concepts in clear, quotable, locally complete passages.
Retrieval breadth changes content economics. Systems reward evidence that can be selected across multiple branches with minimal interpretation cost.
This is the deeper architectural shift behind query fan out. Fan-out is the visible behavior. The underlying change is that answer engines increasingly evaluate content as modular evidence within a broadcast network of sub-queries. Brands that publish isolated pages for isolated keywords leave coverage gaps. Brands that design assets to be independently retrievable across several related intents gain a compounding advantage because the same source can be selected, cited, and synthesized from more than one path.
The Algomizer Framework Semantic Broadcasting

Semantic Broadcasting engineers retrievability across branches
Semantic Broadcasting is the deliberate design of content so that multiple retrieval branches can independently select, interpret, and reuse it.
Most guidance still treats discoverability as a formatting issue. Add schema, sharpen headings, improve metadata. Those tactics help, but they are not the full picture. Emerging research indicates that 40% of AI-generated citations in late 2024 still originated from unstructured, text-heavy pages where AI inferred context through implicit fan-out, according to 85sixty's analysis of citation patterns. That finding breaks a common assumption. Schema improves machine readability, but schema alone does not define machine usefulness.
Semantic Broadcasting starts from a different premise. The retrieval system selects evidence, not layouts. It looks for informational units that are semantically dense, locally clear, and globally connected to adjacent questions. That is why some forum threads and long-tail blog posts still surface. They contain recoverable evidence even without polished structure.
A useful adjacent concept appears in this explanation of semantic latent analysis, which helps clarify why systems can infer topical relationships beyond exact wording. The practical implication is direct. Brand content has to carry enough contextual signals that an LLM can recover meaning even when the user's hidden sub-query never appears verbatim.
Evidence Clusters outperform isolated pages
The winning unit is the Evidence Cluster, which consists of interconnected content fragments that support each other across retrieval branches.
Semantic Broadcasting relies on three components:
Component | What it does | Why it matters |
|---|---|---|
Evidence Clusters | Groups related claims, comparisons, definitions, and proof points | Lets multiple sub-queries land on different parts of the same topic environment |
Answer Capsules | Short, self-contained explanatory blocks | Gives models citable fragments that survive extraction |
Semantic Density | Packs context, qualifiers, and entity detail into concise passages | Reduces ambiguity during retrieval and synthesis |
This framework changes editorial decisions. A long guide should not behave like one monolithic asset. It should behave like a broadcast surface, emitting multiple interpretable units that a model can pick up from different entry points.
Brands trying to operationalize this shift can align it with broader AI-era optimization patterns in this guide to AI search engine optimization. The important move is structural. Content has to answer the hidden decomposition of the topic, not just the visible headline.
A page can be elegant for humans and unusable for retrieval if its evidence is trapped inside long, unresolved prose.
A Data-Driven Contrast Traditional SEO vs GEO
The unit of optimization has changed
Traditional SEO optimizes for rank on a visible query. GEO optimizes for citation across hidden retrieval branches. That is a different operating model.
The strongest quantitative signal in this shift comes from a December 2025 Surfer SEO study, which reported that pages ranking for fan-out queries were 161% more likely to be cited in Google AI Overviews, with a Spearman correlation of 0.77 between fan-out coverage and AI Overview citations, as reported in Ekam Moira's summary of the Surfer research.
That finding doesn't say fan-out optimization is one tactic among many. It says citation behavior tracks strongly with coverage of the hidden sub-questions the system generates.
Legacy SEO measures the wrong battlefield
Legacy SEO still matters for search traffic, but it measures the surface. GEO measures whether a brand is eligible for synthesis.
Dimension | Traditional SEO (Single-Query Model) | Generative Engine Optimization (Fan-Out Model) |
|---|---|---|
Unit of optimization | Web page | Content chunk or evidence fragment |
Retrieval model | One query, one main ranking set | One prompt, many parallel sub-queries |
Success signal | Ranking position | Citation presence and inclusion in synthesized answers |
Content design | Primary keyword targeting | Multi-angle topical coverage |
Authority signal | Backlinks and page authority | Semantic density and branch-level usefulness |
Failure mode | Low rank | Invisible to answer generation even when indexed |
The operational gap is especially visible in service categories. Teams that still think in keyword pages often miss how AI systems evaluate expertise, comparisons, use cases, and trust cues together. For service-business teams, this overview of achieving visibility for service businesses is useful because it shows how buyer-intent content and authority signals have to connect, not sit in separate silos.
The broader strategic distinction between legacy optimization and AI-era optimization is captured well in this breakdown of AEO vs SEO vs GEO. The key point is simple. Search visibility and answer visibility no longer share the same unit economics.
Tactical Patterns for Fan-Out Optimization
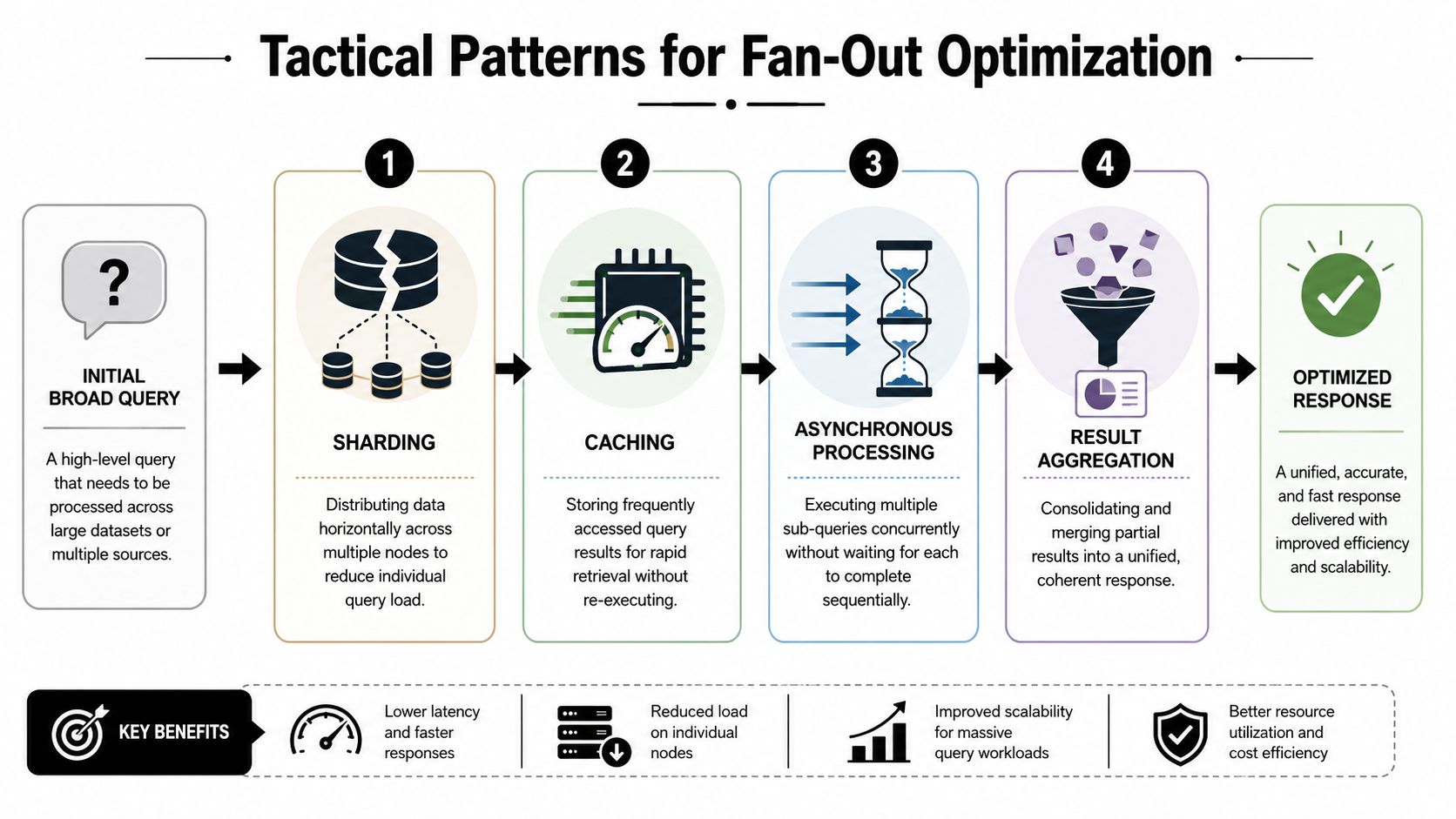
Content has to shard cleanly
Fan-out optimization works when content can be split, fetched, and recombined without losing meaning at the fragment level.
The most effective editorial patterns mirror distributed systems design.
Content sharding: Break long assets into self-sufficient sections that answer one narrow question clearly. Product comparisons, implementation steps, policy explanations, and definitions should stand on their own.
Semantic caching: Maintain definitive resource pages that answer recurring questions with stable language and explicit scope. Models tend to favor sources that repeatedly resolve the same branch cleanly.
Asynchronous support content: Publish adjacent assets that cover the likely follow-up questions around a topic, not just the central commercial page.
Result aggregation readiness: Use tables, compact summaries, and direct answer blocks so extracted fragments remain coherent when they are merged into a synthesized answer.
A content team using an AI SEO software workflow can make this more systematic by identifying recurring retrieval angles and converting them into reusable content modules. The key idea is independent of any specific tool. Retrieval systems favor fragments that can be easily isolated and safely recombined.
Volatility determines how deep coverage must go
Not every industry fans out equally. Sector volatility changes how many hidden research branches an AI system needs before it answers.
New data from Q1 2025 found that high-volatility sectors experienced a 3.5x higher fan-out frequency, averaging 12 to 15 sub-queries per prompt, while low-volatility sectors averaged 3 to 5, even when search volumes were identical, according to Growth Memo's summary of industry search log analysis.
That changes prioritization.
Industry condition | Likely retrieval behavior | Practical content response |
|---|---|---|
High volatility, such as fintech | More branch expansion, more validation steps | Build dense comparison, policy, and update-oriented coverage |
Lower volatility, such as real estate | Fewer branches, more stable information patterns | Focus on durable explanatory pages and localized specifics |
A volatile category needs more than “good content.” It needs branch redundancy. The brand has to cover shifting definitions, competing options, trust markers, and recency-sensitive constraints because the model is less willing to answer from a thin evidence set.
In unstable markets, shallow coverage disqualifies more often because the model has to verify more dimensions before synthesis.
Monitoring and Measuring Fan-Out Coverage
Fan-out coverage is an observability problem, not a rank-reporting problem
Query fan-out changed the unit of measurement. The relevant question is no longer whether a page ranks for a visible query, but whether the brand is repeatedly selected across the hidden branches an LLM uses to assemble an answer.
Classic rank tracking was built for one query mapped to one results page. Fan-out retrieval breaks that model. A single prompt can trigger comparative checks, definitional lookups, trust validation, and edge-case expansion before the model produces a response. If measurement stops at the visible query, the analysis misses the selection events that determined inclusion.
That is why AI visibility has to be measured at the answer layer. The analyst needs to inspect rendered outputs across systems, record which sources are cited, and map those citations back to prompt families and sub-query patterns. Headless browser collection supports that work because it captures the interface users see in ChatGPT, Claude, Gemini, and Perplexity, including source presentation, answer formatting, and citation recurrence.
Measure selection breadth, not just mention frequency
A brand with narrow citation concentration is still vulnerable, even if it appears often. Fan-out coverage is strong only when the brand is selected across multiple semantic branches of the same topic.
Semantic Broadcasting involves an architectural change. Its aim is not merely to expand keywords. Instead, it focuses on publishing evidence that remains intact even when broken down, allowing it to re-emerge across
A practical scorecard includes:
Citation rate by topic cluster: How often the brand appears in generated answers across a defined set of prompts on one subject.
Branch coverage gap: Which recurring sub-queries produce cited answers without the brand present.
Source-type spread: Whether selection comes from one owned page only, or from multiple document types and web environments.
Prompt family distribution: Whether visibility is limited to branded or navigational prompts, or extends into comparison, evaluation, and decision-stage prompts.
Citation stability over repeated runs: Whether the brand persists across regenerated answers and adjacent prompt variants.
The non-obvious signal is concentration risk. If a brand appears only in one branch, such as a definitional sub-query, it can look visible in a dashboard while remaining absent from the synthesis path that drives conversion-oriented answers.
Teams that want a repeatable methodology should use a structured process for auditing brand visibility across LLM-generated answers. The requirement is methodological rigor. Sampling has to cover prompt families, repeated runs, and rendered interfaces, or the audit will overstate visibility by confusing isolated mentions with real fan-out coverage.
Conclusion The Inevitable Fragmentation of Search
Visibility now depends on distributed evidence
Search has become a fragmented retrieval system. Query fan out is the clearest public proof that discovery now happens through parallel evidence gathering, not one-to-one ranking.
That shift changes what content must do. It must be decomposable, semantically legible, and broad enough to satisfy hidden sub-queries without collapsing into vagueness. Brands that still publish for one keyword and one page are optimizing for an interface that no longer governs selection.
The non-obvious implication is strategic. Visibility is no longer a page-level achievement. It is a network property of the brand's information environment. The source that wins is the source that can be retrieved from multiple paths and synthesized with low friction. That is why query fan out matters beyond search mechanics. It reveals the logic by which LLMs decide what is usable evidence.
The old search playbook chased prominence. The new one engineers retrievability. That is the lesson of fan-out architecture.
Search teams that accept this shift can redesign content around Evidence Clusters, Answer Capsules, and branch coverage. Teams that ignore it won't merely lose rank. They will disappear from the systems that increasingly mediate commercial discovery.
For brands that need a clear view of how they appear inside AI-generated answers, Algomizer provides visibility assessments, AI search optimization, and cross-platform citation tracking built for this fragmented retrieval environment. Readers who want the broader research foundation can start from Chapter 1 in the Algomizer blog archive, then book a call to discuss an assessment: book a call with Algomizer.